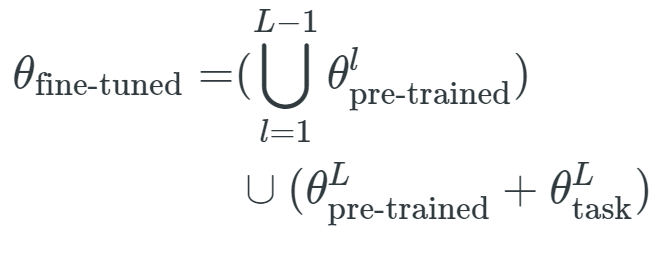详解 2020 最具影响力的十大 ML、NLP 研究的 DeepMind 研究科学家又来了,这次来讲讲语言模型微调领域的最新进展。
![]()
对预训练语言模型(LM)进行微调已成为在自然语言处理中进行迁移学习的实际标准。在过去三年中(Ruder,2018),微调(Howard&Ruder,2018)已经取代了使用预训练嵌入(Peters 等,2018)的特征提取,而预训练语言模型由于它们提高了采样效率和性能(Zhang 和 Bowman,2018),受到了基于翻译训练的模型(McCann 等,2018)、自然语言推理(Conneau 等,2017)和其他一些任务的青睐。
这些成功经验促成了开发更大的模型(Devlin 等,2019; Raffel 等,2020)。实际上,近来一些模型因为很大,所以它们可以在不进行任何参数更新的情况下实现合理的性能(Brown 等,2020)。但是出于这种零样本设置的局限性,为了获得最佳性能或保持合理的效率,在实践中使用大型预训练 LM 时,微调仍可能是操作方式。
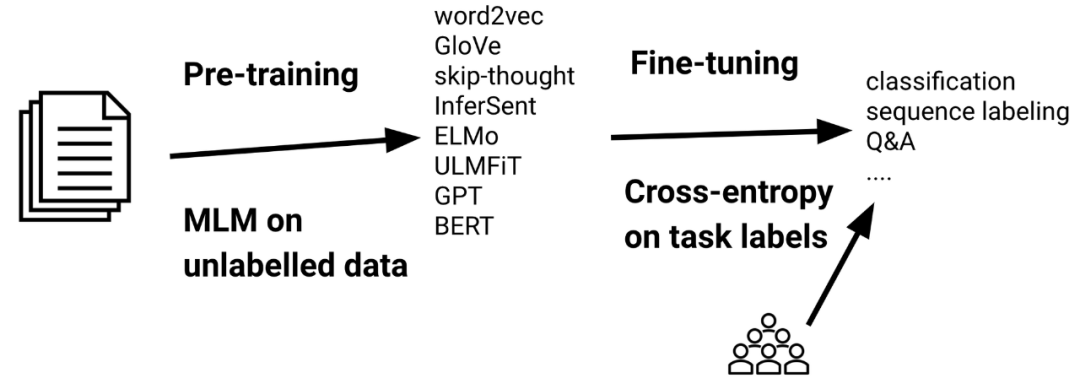
在标准的迁移学习设置中,首先使用语言建模损失(如掩码语言建模(MLM; Devlin 等,2019))让模型在大量未标记数据上进行预训练,然后使用标准的交叉熵损失在下游任务的标记数据上进行微调。
![]()
预训练需要大量计算,而微调却可以相对便宜地完成。微调对于此类模型的实际使用更为重要,因为要下载和微调了数百万次单独的预训练模型。在本篇文章中,作者重点介绍了微调,特别是可能重塑或改变语言微调模型方式的最新进展,如下所示。
![]()
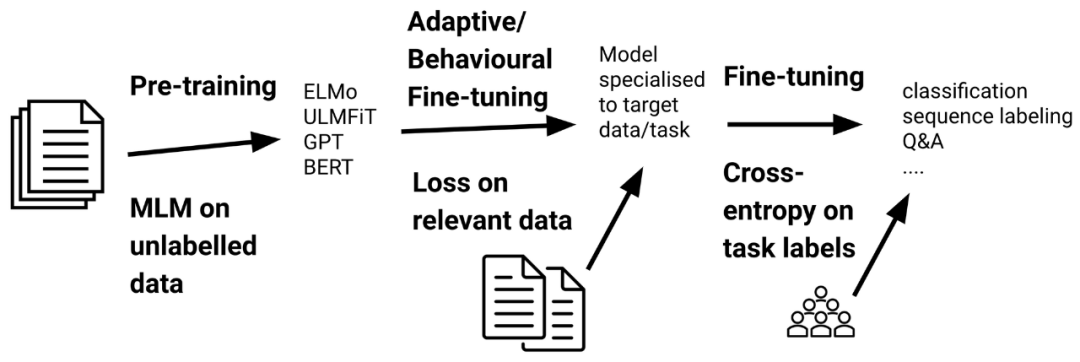
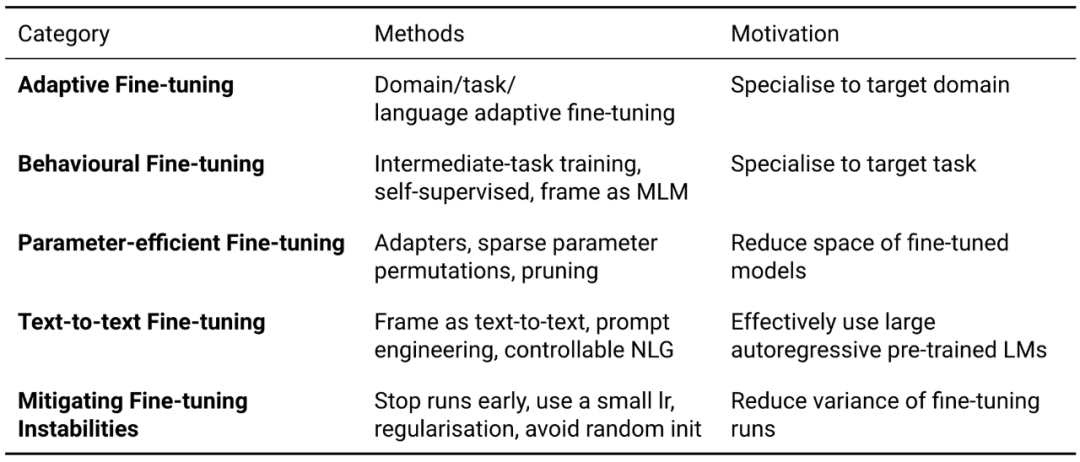
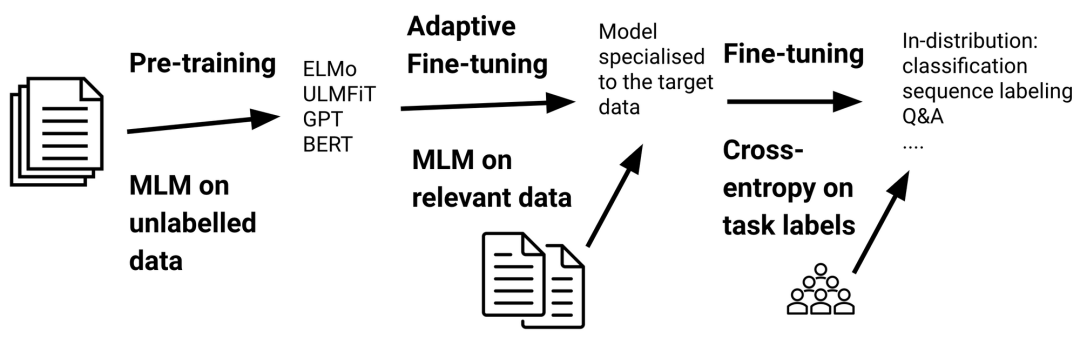
即使就分布外泛化而言,经过预训练的语言模型比以前的模型更加鲁棒(Hendrycks 等,2020),但它们仍然不能很好地处理与预训练数据完全不同的数据。自适应微调是一种通过在更接近目标数据分布的数据上微调模型来弥合这种分布偏移的方法。具体而言,自适应微调包括在任务特定的微调之前,在附加数据上对模型进行微调,如下所示。重要的是,该模型已根据预训练目标进行了微调,因此自适应微调仅需要未标记的数据。
![]()
自适应微调是标准迁移学习设置的一部分。预训练模型是在更接近目标分布的数据上使用预训练损失(通常是掩码语言建模)进行训练的。
形式上,给定由特征空间 x 和特征空间上的边缘概率分布 P(X) 组成的目标域 D_T,其中 X = {x_1,...,x_n}∈x(Pan and Yang,2009; Ruder,2019),自适应微调允许学习特征空间 X 和目标数据的分布 P(X)。
自适应微调的变体(域,任务和语言自适应微调)已分别用于使模型适应目标域,目标任务和目标语言的数据。Dai 和 Le(2015)首次表明了域自适应微调的好处。Howard and Ruder(2018)随后通过在域内数据上进行微调展示了更高的采样效率。他们还提出了任务自适应微调,这种微调可以根据任务训练数据上的预训练目标对模型进行微调。与 one-hot 任务标签上的交叉熵相比,预训练损失为建模目标数据提供了更丰富的信息,因此任务自适应微调比常规微调更有用。或者,可以通过多任务学习(Chronopoulou 等,2019)联合进行自适应微调和常规微调。
域和任务自适应微调最近已应用于最新一代的预训练模型(Logeswaran 等,2019;Han 和 Eisenstein,2019;Mehri 等,2019)。Gururangan 等(2020)的研究表明,适应目标域和目标任务的数据是互补的。最近,Pfeiffer 等(2020)提出了语言自适应微调,以使模型适应新语言。
自适应微调模型专用于特定的数据分布,它能够很好地建模。但是,这需要为成为通用语言模型的能力付出代价。因此,当在单个域的任务(可能有多个)的高性能很重要时,自适应微调最有用,如果预训练模型应该适应大量域,那么自适应微调在计算上效率低下。
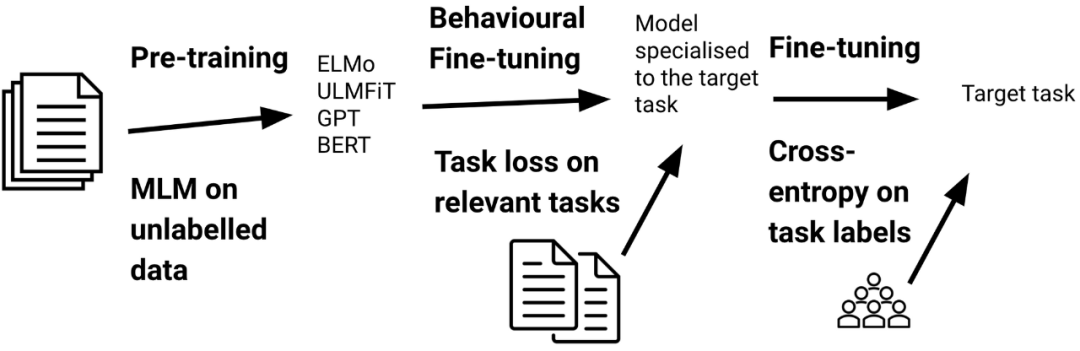
尽管自适应微调使我们能够将模型专门化为 D_T,但它并不能直接告诉我们有关目标任务的任何信息。形式上,目标任务τ_T 由标签空间 y,先验分布 P(Y),其中 Y = {y_1,...,y_n}∈y 和条件概率分布 P(Y | X)组成。或者,我们可以通过在相关任务上进行微调来教模型某些能力,使得该模型可以很好地完成目标任务,如下所示。我们将这种设置称为行为型微调,因为它着重于学习有用的行为并将其与自适应微调区分开。
![]()
预训练模型的行为型微调。对与目标任务相关的任务,使用特定于任务的监督目标或自监督目标,对预训练模型进行了训练。
教模型掌握相关能力的一种方法是在特定于任务的微调之前,根据相关任务的相关标记数据对其进行微调(Phang 等,2018)。这种所谓的中间任务训练最适合需要高层级推断和推理能力的任务(Pruksachatkun 等,2020 ;Phang 等,2020)。带有标记数据的行为型微调已被用于教有关命名实体的模型信息(Broscheit,2019),复述(Arase 和 Tsujii,2019),语法(Glavaš和 Vulić,2020),答案句子选择(Garg 等, 2020)和问题解答(Khashabi 等,2020)。Aghajanyan 等(2021)在大规模多任务设置中微调约 50 个带标签的数据集,并观察到大量多样的任务集合对于良好的迁移性能至关重要。
由于通常很难获得此类高层级推理任务的监督数据,因此,我们可以在目标上进行训练,这些目标可以教模型掌握与下游任务相关的能力,但仍可以以自监督的方式进行学习。例如,Dou 和 Neubig(2021)微调了一种词对齐模型,其目标是教其从其他句子中识别平行句(parallel sentences)等。Sellam 等(2020)对 BERT 进行了微调,以使用一系列句子相似度信号进行质量评估。在这两种情况下,学习信号的多样性都是重要的。
另一种有效的方法是将目标任务设计成掩码语言建模的一种形式。为此,Ben-David 等(2020)使用 pivot-based 目标微调了一种用于情感域适应的模型。还有一些研究者提出了预训练目标,可以在微调中类似地使用它们:Ram 等(2021)预训练了具有 span 选择任务的 QA 模型,而 Bansal 等(2020)通过自动生成 cloze-style 的多类分类任务来预训练用于少样本学习的模型。
自适应型和行为型微调的区别鼓励我们考虑要注入模型的归纳偏差,以及它们是否与域 D 或任务τ的属性有关。区分域和任务的作用很重要,因为通常可以使用有限的未标记数据来学习关于域的信息(Ramponi 和 Plank,2020),而采用当前方法获得的高级自然语言理解技能通常需要数十亿的预训练数据样本(Zhang 等,2020)。
但是,当我们根据预训练目标来组织任务时,任务和域之间的区别变得模糊。MLM 等足够通用的预训练任务可以为学习 P(Y | X)提供有用的信息,但可能不包含对该任务重要的所有信号。例如,经过 MLM 预训练的模型难以建模反向情况、数字或命名实体(Rogers 等,2020)。
类似地,数据增强的使用使 D 和τ的角色纠缠在一起,因为它允许我们直接在数据中编码所需的功能。例如,通过微调用性别相反的单词替换性别单词的文本模型,会使模型对性别偏见更加鲁棒(Zhao 等,2018; Zhao 等,2019; Manela 等,2021。
当需要在许多设置中(例如,针对大量用户)对模型进行微调时,为每种情况存储微调模型的副本在计算上会非常昂贵。因此,近来一些研究致力于保持大多数模型参数固定不变,并对每个任务微调少量参数。实际上,这使得存储大型模型的单个副本以及许多具有任务特定修改的小文件变得容易。
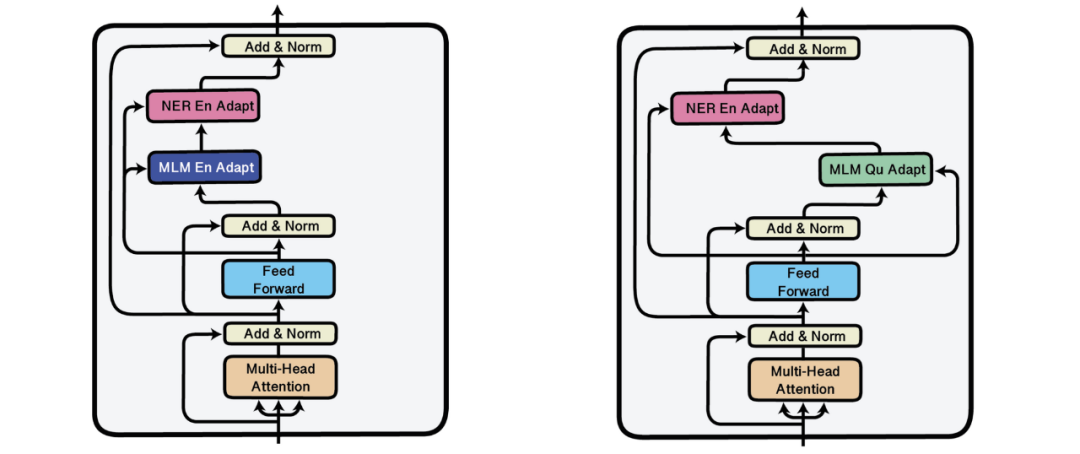
这类研究中的第一种方法是基于「适配器」(Rebuffi 等,2017),在预训练模型各层之间插入了小的瓶颈层(Houlsby 等,2019;Stickland 和 Murray,2019),其参数是固定的。适配器提供通用设置,例如在训练过程中存储多个检查点以及更高级的技术(例如检查点平均(Izmailov 等,2018)、快照集成(Huang 等,2017)、temporal 集成(Laine 和 Aila,2017))时,空间效率更高。使用适配器,通用模型可以有效地适应许多设置,例如不同的语言(Bapna 和 Firat,2019)。Pfeiffer 等(2020)最近证明了适配器是模块化的,可以通过堆栈进行组合,从而可以独立学习专用表征。这在使用上述方法时特别有用:可以通过在其顶部堆叠经过训练的任务适配器来评估自适应型或行为型微调的适配器,而无需进行任何特定于任务的微调,如下图所示。
![]()
在 MAD-X 框架的 Transformer 块中插入的任务和语言适配器(Pfeiffer 等,2020)。适配器学习封装的表征,并且可以相互替换,从而实现零样本迁移。
适配器在不更改基础参数的情况下修改模型的激活函数,另一类研究则是直接修改预训练参数。为了说明这类方法,我们可以将微调视为学习扰动(perturb)预训练模型参数的方法。形式上,为了获得微调模型
![]() 的参数(其中 D 是模型的维数),需要学习特定于任务的参数向量
的参数(其中 D 是模型的维数),需要学习特定于任务的参数向量
![]() 来捕获更改预训练模型参数
来捕获更改预训练模型参数
![]() 的方法。
微调后的参数是将任务特定的排列应用于预训练参数的结果:
的方法。
微调后的参数是将任务特定的排列应用于预训练参数的结果:
![]()
该方法没有为每个任务存储θ_fine-tuned 的副本,取而代之的是可以为每个任务存储θ_pre-trained 的单个副本和θ_task 的副本。
如果我们可以更有效地参数化θ_task,那么这种设置会更加划算。
为此,Guo 等(2020)学习θ_task 作为稀疏向量。
Aghajanyan 等(2020)设置
![]() 其中,θ_low 是一种低维向量,M 是随机线性投影。
或者,我们还可以仅对预训练参数的子集进行修改。计算机视觉中有一种经典方法(Donahue 等,2014)仅微调了模型的最后一层。假设θ_pre-trained 是模型所有 L 层上预训练参数的集合,即
其中,θ_low 是一种低维向量,M 是随机线性投影。
或者,我们还可以仅对预训练参数的子集进行修改。计算机视觉中有一种经典方法(Donahue 等,2014)仅微调了模型的最后一层。假设θ_pre-trained 是模型所有 L 层上预训练参数的集合,即
![]() ,其中
,其中
![]() 是与第 l 层相关联的参数向量,表示形式和θ_fine-tuned、θ_task 类似。
因此,仅对最后一层进行微调等效于:
是与第 l 层相关联的参数向量,表示形式和θ_fine-tuned、θ_task 类似。
因此,仅对最后一层进行微调等效于:
![]()
虽然这在 NLP 中效果不佳(Howard&Ruder,2018),但是还有其他一些参数子集可以更有效地进行微调。例如,Ben-Zaken 等(2020)仅通过微调模型的偏差参数就可以实现很好的性能。
还有一类研究是在微调期间剪枝预训练模型的参数。此类方法使用不同的标准来剪枝权重,例如基于权重重要性的零级或一阶信息(Sanh 等,2020)。由于当前硬件对稀疏架构的支持有限,因此目前最好采用结构上稀疏的方法,即将更新集中在有限的一组层,矩阵或向量中。例如,预训练模型的最后几层已显示在微调过程中用途很有限,并且可以随机重新初始化(Tamkin 等,2020; Zhang 等,2021),甚至被完全移除(Chung 等,2021)。
剪枝方法着重于减少任务特定模型的参数总数,而其他大多数方法着重于减少可训练参数的数量,同时保留θ_pre-trained 的副本。后者中的最新方法通常与完全微调的性能相匹配,同时每个任务训练大约 0.5%的模型参数(Pfeiffer 等,2020; Guo 等,2020; Ben-Zaken 等,2020)。
越来越多的证据表明,大型的预训练语言模型可以很好地压缩 NLP 任务(Li 等,2018;Gordon 等,2020;Aghajanyan 等,2020)。这些实用的证据以及它们的便利性,可用性(Pfeiffer 等,2020 )以及最近的一些成功研究使这些方法在实验和实际环境中都颇为有效。
迁移学习的另一个发展方向是从 BERT(Devlin 等,2019)和 RoBERTa(Liu 等,2019)等掩码语言模型到 T5(Raffel 等,2019) 和 GPT-3(Brown 等,2020)等自回归语言模型的转变。
虽然这两种方法都可以用于为文本分配可能性得分(Salazar 等,2020),但自回归 LM 更容易采样。相反,掩码 LM 通常仅限于空白填充设置(如 Petroni 等,2019)。
使用掩码 LM 进行微调的标准方法是使用随机初始化任务特定 head 替换用于 MLM 的输出层,其中 head 被用于目标任务上的学习(Devlin 等,2019)。或者,通过以 cloze-style 格式将任务重塑为 MLM(Talmor 等,2020;Schick 和 Schütze,2021),预训练模型的输出层能够被复用。类似地,自回归 LM 通常以文本到文本的格式抛出目标任务(McCann 等,2018;Raffel 等,2020;Paolini 等,2021)。在这两种设置中,模型都能够从所有预训练知识中受益,并且无需从头开始学习新参数,从而提高了样本效率。
在极端情况下,如果不对参数进行微调,根据预训练目标构建目标任务允许使用特定于任务的 prompt 和少量任务样例实现零样本或少样本学习(Brown 等,2020)。但使用这种模型进行少样本学习并不是最有效的方式(Schick 和 Schütze,2020)。不含更新的学习需要一个巨大的模型,因为该模型需要完全依赖现有知识。该模型可用的信息量也受到其上下文窗口的限制,并且呈现给模型的 prompt 也需要仔细设计。
检索增强可以减轻外部知识的存储负担,并且可以使用符号化方法教类似于(Awasthi 等,2020)的模型特定于任务的规则。预训练模型也将变得更大更强,并且可能会在行为上进行微调,以使其在零样本设置下性能良好。但是,如果不进行微调,模型最终适应新任务的能力将受到限制。
因此,对于大多数实际环境,最佳方法可能是使用上述介绍的方法对模型参数的全部或其子集进行微调。此外,预训练模型将越来越重视生成能力。虽然当前的方法通常集中在修改模型的自然语言输入上,例如通过自动 prompt 设计(Schick 和 Schütze,2020; Gao 等,2020; Shin 等,2020),但调节此类模型输出最有效的方法可能会直接作用于它们的隐藏表征(Dathathri 等,2020)。
微调预训练模型的一个实际问题是,不同运行实验之间的性能可能会发生巨大变化,尤其是在小型数据集上(Phang 等,2018)。Dodge 等(2020)发现,输出层的权重初始化和训练数据的顺序都会导致性能发生变化。由于不稳定通常在训练的早期就很明显,因此建议在训练 20-30%后尽早停止最无希望的尝试。Mosbach 等(2021)还建议使用较小的学习率,并在微调 BERT 时增加 epoch 数。
许多最新方法试图依靠对抗或基于信任域的方法来减轻微调期间的不稳定性(Zhu 等,2019;Jiang 等,2020;Aghajanyan 等,2021)。此类方法通常使用限制更新步骤之间差异的正则化项来增加微调损失。
根据前文的内容,我们可以提出一些建议,以最大程度地减少微调过程中的不稳定性:避免通过将目标任务构建为 LM 形式在小型数据集上对目标任务使用随机初始化的输出层,或者在特定于任务的微调之前使用行为型微调对输出层进行微调。虽然文本到文本模型因此在小型数据集上微调更具鲁棒性,但它们在少样本设置中就很不稳定,且对于零样本样例和 prompt 较为敏感(Zhao 等,2021)。
总体而言,随着模型越来越多地用于训练样例较少的挑战性任务,开发对可能的变化具有鲁棒性并且可以进行可靠微调的方法至关重要。
原文链接:https://ruder.io/recent-advances-lm-fine-tuning/
亚马逊云科技线上黑客松2021
这是一场志同道合的磨练,这是一场高手云集的组团竞技。秀脑洞、玩创意,3月26日至5月31日,实战的舞台为你开启,「亚马逊云科技线上黑客松2021」等你来战!
为了鼓励开发者的参与和创新,本次大赛为参赛者准备了丰厚的奖品,在一、二、三等奖之外,还特设prActIcal奖、creAtIve奖、锦鲤极客奖、阳光普照奖,成功提交作品的团队均可获赠奖品。
识别二维码,立即报名参赛。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
 的参数(其中 D 是模型的维数),需要学习特定于任务的参数向量
的参数(其中 D 是模型的维数),需要学习特定于任务的参数向量
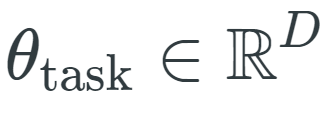 来捕获更改预训练模型参数
来捕获更改预训练模型参数
 的方法。
微调后的参数是将任务特定的排列应用于预训练参数的结果:
的方法。
微调后的参数是将任务特定的排列应用于预训练参数的结果:

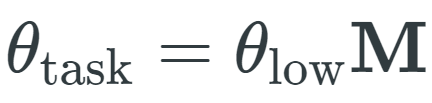 其中,θ_low 是一种低维向量,M 是随机线性投影。
其中,θ_low 是一种低维向量,M 是随机线性投影。
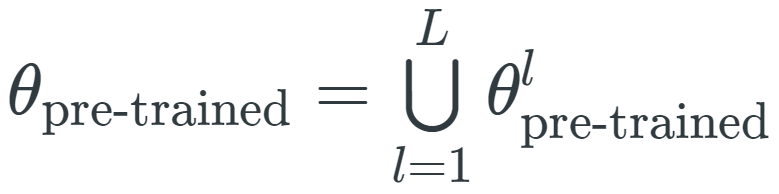 ,其中
,其中
 是与第 l 层相关联的参数向量,表示形式和θ_fine-tuned、θ_task 类似。
因此,仅对最后一层进行微调等效于:
是与第 l 层相关联的参数向量,表示形式和θ_fine-tuned、θ_task 类似。
因此,仅对最后一层进行微调等效于: