近日,全球顶级数据挖掘竞赛 KDD Cup 2020 已经正式画上圆满句号,KDD Cup 2020 RL Track 比赛结果也随之出炉,北京航空航天大学软件开发环境国家重点实验室童咏昕教授研究组与第四范式罗远飞组成的联合团队脱颖而出,斩获 KDD Cup 2020 强化学习挑战赛冠军。
![]()
据主办方滴滴介绍,本次注册队伍达到了 1007 支,其中不乏普渡大学、南京大学、中国科学技术大学、中山大学、东南大学等国际顶尖高等院校以及电商巨头京东、出行巨头 Lyft、 日本通信巨头 NTT DOCOMO 的身影。
作为全球数据挖掘领域最有影响力的赛事,KDD Cup 比赛由 ACM 协会的国际顶级会议 SIGKDD 举办,自 1997 年以来每年举办一次。KDD Cup 多年来一直保持着很高的工业界参与度以及对解决实际问题的敏感度。与去年 KDD Cup 强化学习挑战赛的分类问题以及过往多应用在体育竞技类比赛性质不同,今年的强化学习赛道(RL Track)聚焦于更加真实且问题极为复杂的业务场景,旨在解决共享出行领域优化难题。在题目难度进一步增加的同时,也将强化学习的价值进一步放大。
如今,按需出行(MoD)或网约车平台已成为大众不可或缺的出行方式,对于网约车平台来说,高效率的按需出行系统可以为司机和乘客提供更好的用户体验:司机可以通过减少空转时间获得更高的收入,乘客等待时间会更短,满意度也会更高。因此,如何更有效地利用空置车辆,更快、更高效地匹配乘客需求、提高司机收入成为了网约车平台优化指标当中的重中之重。
按需出行系统的效率取决于时空中供需分布的协调程度。如果想要调整供给分布来更好地协调需求,从而优化运营效率,有两个重要的问题:车辆调度(vehicle repositioning)和订单分配(order dispatching)。订单分配负责把空闲的车辆分配给等待中的出行订单,并把乘客(和司机)运输到订单终点。车辆调度是一种更主动的策略,可以把闲置的车辆部署到预计未来会产生需求的特定位置。
因此,参赛者需要同时解决按需出行平台上订单分配(order dispatching)和车辆调度(vehicle repositioning)问题,通过主办方提供的真实场景数据和模拟器,基于强化学习设计一个智能匹配与调度算法,以最大化平台所有司机的平均日收入。
真实场景,数据量大:历史数据包含西南某省会城市一个月时间内几百个 G 的数据记录;线上亦基于若干天的真实数据来评测;
因素多:影响司机收益的因素很多,如接驾距离、天气、路况信息、出行时间等,需要考虑复杂的环境因素;
实时性:在一天内,算法每 2 秒被调用一次,必须 2 秒内做出分配,且订单和司机信息每次不同,不能预分配;
调参难:官方并未提供模拟器,且已有数据不足以在线下搭建出高质量的模拟器,需要开发的算法具有较强的鲁棒性。
为了最大化平台上所有司机日均收入,在计算每个订单的收益时,采用基于强化学习的方法,不仅能考虑当前时刻的收入,还能兼顾未来可能的收益。同时,结合剪枝与 C++ 实现的高效二分图匹配算法,能够在 2 秒的时限内,及时找到合适的订单分配方案,从而取得了更好的效果。
![]()
代码地址:htt
ps://github.com/maybeluo/KDDCup2020-RL-1st-solution
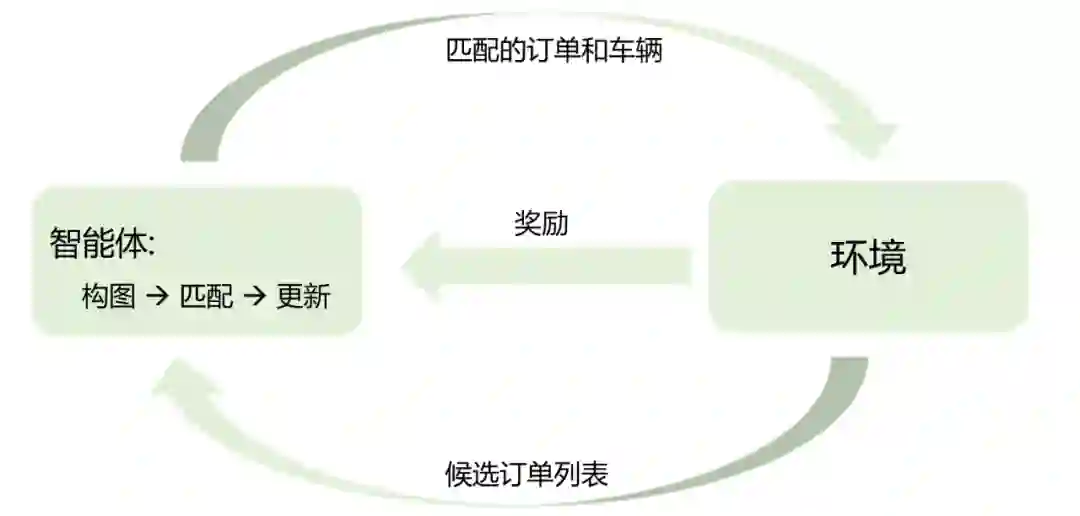
本赛题的优化目标是最大化平台上司机一天内的平均总收益,因此在派单时,不仅要考虑最大化当前时间窗的收益,还必须考虑未来的可能收益。同时,当前的订单分配会影响车辆的位置和收益,对未来产生影响,是一个序列决策问题,因此考虑通过强化学习解决。此情景下,环境 (Environment) 包括订单、司机车辆信息位置等,而参赛者需要定义智能体 (Agent)的学习和预测策略,以最大化司机的收益。本问题中司机和车辆一一对应,下文中如未特殊强调,车辆和司机含义一般可以互换。状态 (State)、动作(Action) 和奖励 (Reward) 设计如下:
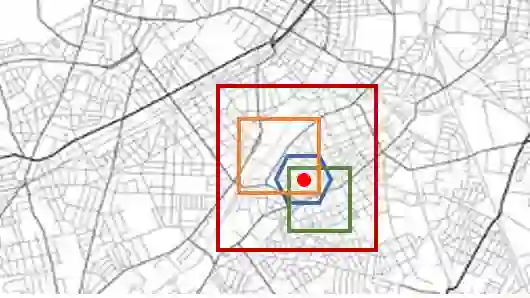
联合团队使用车辆的地理坐标经过离散化后对应的 ID,来表示车辆的状态,而不考虑时间因素。具体的,团队同时使用了多种离散化策略,使得每个地理坐标,对应多个不同粒度的状态,如主办方提供的六边形格子划分策略,还可以是多种不同大小的四边形等。如下图所示,对于图中的坐标点(红色圆点),离散化后,可以同时采用六边形、不同大小的四边形来标识该点对应的状态。
![]()
智能体执行派单程序后,会生成司机和订单的匹配列表。在不考虑取消订单的情况下,成功匹配的司机将会进入服务 (serving) 状态: 司机会到达指定上车点,接到乘客,并运送到指定下车点,拿到相应的奖励。而未能分配到订单的司机,将会闲置(idle),不能拿到任何收益。
每次派单成功后,司机会拿到相应订单的收益,作为本次动作的奖励。本次比赛的目标,即是最大化所有司机的平均收益。
每次智能体被调用时,将接收到当前所有的候选订单信息,并在 2 秒内做出司机和乘客的匹配。候选信息列表是候选订单的集合,每个候选订单主要包含如下信息:
oorder_id 和 driver_id: 订单 ID 和司机 ID,用来唯一标识候选订单和司机;
odriver_location: 司机在当前时刻所处的地理位置,本次比赛中地理位置信息均采用经纬度对来表示;该信息信息经过离散化后,得到订单的起始状态标识;
oorder_finish_location:订单结束位置,即订单的目的地;该信息经过离散化后,得到订单的终点状态标识;
oduration:订单的预估时长;
oreward:订单带来的收益。
此外,还有当前时刻信息、订单起始位置(order_start_location)、接驾距离(司机和乘客的距离 order_driver_distance)、预估接驾时长(pick_up_eta)等,可以根据此类信息推断订单取消概率。
本方案整体策略为通过时序差分算法(Temporal Difference)学习状态值,并通过二分图匹配算法最大化收益。具体的,智能体接受到候选订单列表后,将依次执行以下三个步骤:
1) 构图:通过候选订单信息,将司机和乘客建模成二分图;并根据起止点对应的状态,计算边权;
2) 匹配:通过二分图匹配算法,将司机和乘客匹配,并派单;
3) 更新:根据匹配结果,通过时序差分算法的学习规则,更新涉及到的状态对应的值。
下面详细介绍每个步骤。
本文将订单 ID 和司机 ID 作为图的顶点,并根据候选订单信息,连接相应的订单和司机,得到对应的图。因为订单之间、司机之间均不存在连接关系,因此该图是二分图。另外,为了保证更快的得到匹配效果,加速后续匹配算法,将二分图按如下策略剪枝:对于每个订单,只保留接驾距离最小 K 个司机对应的边;在比赛中,K 取 11。
不妨将司机位置(driver_location)和订单终点(order_finish_location)对应的状态分别记为 S
和
S^'
,其对应的
状态值分别
为
V(S)
和
V(S^')
,则二分图中的边权 w 计算方式为:
![]()
其中,R 为订单对应的收益,t 为离散化后的订单时长,![]() 为折扣
因子, p 为订单的取消概率。
订单取消概率和接驾距离、接驾时长等有关,可以通过对官方提供的历史数据中订单取消概率建模,得到对应的订单取消概率预测模型,以便线上推断每个订单的取消概率。
构图完成后,得到剪枝后的二分图以及每条边的权重,可以直接利用匈牙利算法进行匹配。在实际使用时,团队发现 Scipy 提供的对应算法接口 (https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.linear_sum_assignment.html) 效率较低,导致超时(不能在 2 秒的时间窗内做出匹配)。如果直接使用贪心算法(完全贪心或
为折扣
因子, p 为订单的取消概率。
订单取消概率和接驾距离、接驾时长等有关,可以通过对官方提供的历史数据中订单取消概率建模,得到对应的订单取消概率预测模型,以便线上推断每个订单的取消概率。
构图完成后,得到剪枝后的二分图以及每条边的权重,可以直接利用匈牙利算法进行匹配。在实际使用时,团队发现 Scipy 提供的对应算法接口 (https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.linear_sum_assignment.html) 效率较低,导致超时(不能在 2 秒的时间窗内做出匹配)。如果直接使用贪心算法(完全贪心或![]() - greedy)分配
订单,则效果不佳
。
另外,司机和乘客数量一般不等,导致图中二分图顶点数目
不均衡。
综合
以上因素,我们使用
C++ 实现了高效的匈牙利算法(hungarian algorithm),并编译成
对应的 so 文件,通过 Python 直接调用,以解决容易超时的问题。
当订单分配完成后,需要根据分配的结果更新对应的状态值。因官方未提供比赛环境对应的模拟器,不能线下调参,因此选择从简单模型入手。我们选取了单步在线策略更新的 SARSA 算法(state–action–reward–state–action)。对于每个订单的起点和终点,它们均会同时激活多个不同粒度的状态表示,记每个坐标位置离散化后的状态个数为 k。
- greedy)分配
订单,则效果不佳
。
另外,司机和乘客数量一般不等,导致图中二分图顶点数目
不均衡。
综合
以上因素,我们使用
C++ 实现了高效的匈牙利算法(hungarian algorithm),并编译成
对应的 so 文件,通过 Python 直接调用,以解决容易超时的问题。
当订单分配完成后,需要根据分配的结果更新对应的状态值。因官方未提供比赛环境对应的模拟器,不能线下调参,因此选择从简单模型入手。我们选取了单步在线策略更新的 SARSA 算法(state–action–reward–state–action)。对于每个订单的起点和终点,它们均会同时激活多个不同粒度的状态表示,记每个坐标位置离散化后的状态个数为 k。
![]()
![]()
计算得到状态值后,对起点所对应的各状态,按照如下公式更新:
![]()
其中,![]() 为学习率。
联合团队也曾尝试基于深度强化学习的状态学习和更新方法,但效果不佳;尝试基于动态规划、时序差分等方法,通过历史数据在线下学习对应状态值,作为线上状态的初值,未能取得收益。也尝试了一系列方法,以降低时序差分单步更新时可能引入的噪音,仍未能取得更好的效果。
因此,针对真实场景下的大规模订单实时分配问题,将强化学习和二分图匹配算法相结合,在最大化当前收益的同时,能够有效兼顾未来可能的收益。相比基线模型或其他选手方案,本方案能够取得更大的收益。
为学习率。
联合团队也曾尝试基于深度强化学习的状态学习和更新方法,但效果不佳;尝试基于动态规划、时序差分等方法,通过历史数据在线下学习对应状态值,作为线上状态的初值,未能取得收益。也尝试了一系列方法,以降低时序差分单步更新时可能引入的噪音,仍未能取得更好的效果。
因此,针对真实场景下的大规模订单实时分配问题,将强化学习和二分图匹配算法相结合,在最大化当前收益的同时,能够有效兼顾未来可能的收益。相比基线模型或其他选手方案,本方案能够取得更大的收益。
Amazon SageMaker 是一项完全托管的服务,可以帮助开发人员和数据科学家快速构建、训练和部署机器学习 模型。SageMaker完全消除了机器学习过程中每个步骤的繁重工作,让开发高质量模型变得更加轻松。
现在,企业开发者可以免费领取1000元服务抵扣券,轻松上手Amazon SageMaker,快速体验5个人工智能应用实例。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

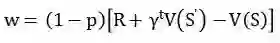
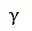 为折扣
因子, p 为订单的取消概率。
为折扣
因子, p 为订单的取消概率。
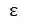 - greedy)分配
订单,则效果不佳
。
另外,司机和乘客数量一般不等,导致图中二分图顶点数目
不均衡。
综合
以上因素,我们使用
C++ 实现了高效的匈牙利算法(hungarian algorithm),并编译成
对应的 so 文件,通过 Python 直接调用,以解决容易超时的问题。
- greedy)分配
订单,则效果不佳
。
另外,司机和乘客数量一般不等,导致图中二分图顶点数目
不均衡。
综合
以上因素,我们使用
C++ 实现了高效的匈牙利算法(hungarian algorithm),并编译成
对应的 so 文件,通过 Python 直接调用,以解决容易超时的问题。
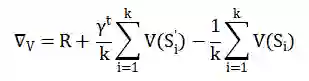
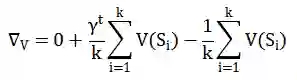
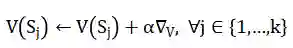
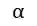 为学习率。
为学习率。





