paper:Multi-Level Discovery of Deep Options
Multi-Level Discovery of Deep Options
Abstract
Augmenting an agent’s control with useful higher-level behaviors called optionscan greatly reduce the sample complexity of reinforcement learning, but manually designing options is infeasible in high-dimensional and abstract state spaces. While recent work has proposed several techniques for automated option discovery, they do not scale to multi-level hierarchies and to expressive representations such as deep networks. We present Discovery of Deep Options (DDO), a policy-gradient algorithm that discovers parametrized options from a set of demonstration trajecto- ries, and can be used recursively to discover additional levels of the hierarchy. The scalability of our approach to multi-level hierarchies stems from the decoupling of low-level option discovery from high-level meta-control policy learning, facilitated by under-parametrization of the high level. We demonstrate that using the discov- ered options to augment the action space of Deep Q-Network agents can accelerate learning by guiding exploration in tasks where random actions are unlikely to reach valuable states. We show that DDO is effective in adding options that accelerate learning in 4 out of 5 Atari RAM environments chosen in our experiments. We also show that DDO can discover structure in robot-assisted surgical videos and kinematics that match expert annotation with 72% accuracy.
DDCO: Discovery of Deep Continuous Options for Robot Learning from Demonstrations
Sanjay Krishnan, Roy Fox, Ion Stoica, Ken Goldberg
(Submitted on 15 Oct 2017 (v1), last revised 31 Oct 2017 (this version, v2))
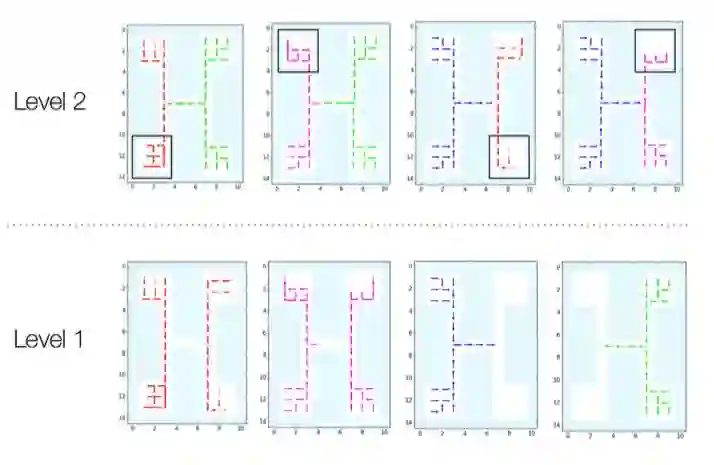
An option is a short-term skill consisting of a control policy for a specified region of the state space, and a termination condition recognizing leaving that region. In prior work, we proposed an algorithm called Deep Discovery of Options (DDO) to discover options to accelerate reinforcement learning in Atari games. This paper studies an extension to robot imitation learning, called Discovery of Deep Continuous Options (DDCO), where low-level continuous control skills parametrized by deep neural networks are learned from demonstrations. We extend DDO with: (1) a hybrid categorical-continuous distribution model to parametrize high-level policies that can invoke discrete options as well continuous control actions, and (2) a cross-validation method that relaxes DDO's requirement that users specify the number of options to be discovered. We evaluate DDCO in simulation of a 3-link robot in the vertical plane pushing a block with friction and gravity, and in two physical experiments on the da Vinci surgical robot, needle insertion where a needle is grasped and inserted into a silicone tissue phantom, and needle bin picking where needles and pins are grasped from a pile and categorized into bins. In the 3-link arm simulation, results suggest that DDCO can take 3x fewer demonstrations to achieve the same reward compared to a baseline imitation learning approach. In the needle insertion task, DDCO was successful 8/10 times compared to the next most accurate imitation learning baseline 6/10. In the surgical bin picking task, the learned policy successfully grasps a single object in 66 out of 99 attempted grasps, and in all but one case successfully recovered from failed grasps by retrying a second time.
DIVIDE-AND-CONQUER REINFORCEMENT LEARNING
Standard model-free deep reinforcement learning (RL) algorithms sample a new initial state for each trial, allowing them to optimize policies that can perform well even in highly stochastic environments. However, problems that exhibit consider- able initial state variation typically produce high-variance gradient estimates for model-free RL, making direct policy or value function optimization challenging. In this paper, we develop a novel algorithm that instead partitions the initial state space into “slices”, and optimizes an ensemble of policies, each on a different slice. The ensemble is gradually unified into a single policy that can succeed on the whole state space. This approach, which we term divide-and-conquer RL, is able to solve complex tasks where conventional deep RL methods are ineffective. Our results show that divide-and-conquer RL greatly outperforms conventional policy gradient methods on challenging grasping, manipulation, and locomotion tasks, and exceeds the performance of a variety of prior methods. Videos of poli- cies learned by our algorithm can be viewed at http://bit.ly/dnc-rl.

