你以为自己在填验证码,其实你是在给Google义务劳动
点击上方蓝色字体“腾讯创业” 选择关注公众号
创投圈大小事,你都能尽在掌握

腾讯创业 | ID:qqchuangye
每一个网上冲浪的高手都在验证码上栽过跟头。
作者 / 邢逸帆
来源 / 硅星人(ID:guixingren123)
最近,我们发现,上网遇见的验证码“越来越有内容”了。
为了证明自己是个真人,除了要输入方框里的文字,还得做从下面图中挑出路牌、挑出门牌这种连连看似的高级任务。
在连续干了好几茬之后,我突然醒悟:我这哪里是在填验证码,根本就是在帮别人标注数据,训练AI啊!
不管是给图片分类:

给路牌勾边:
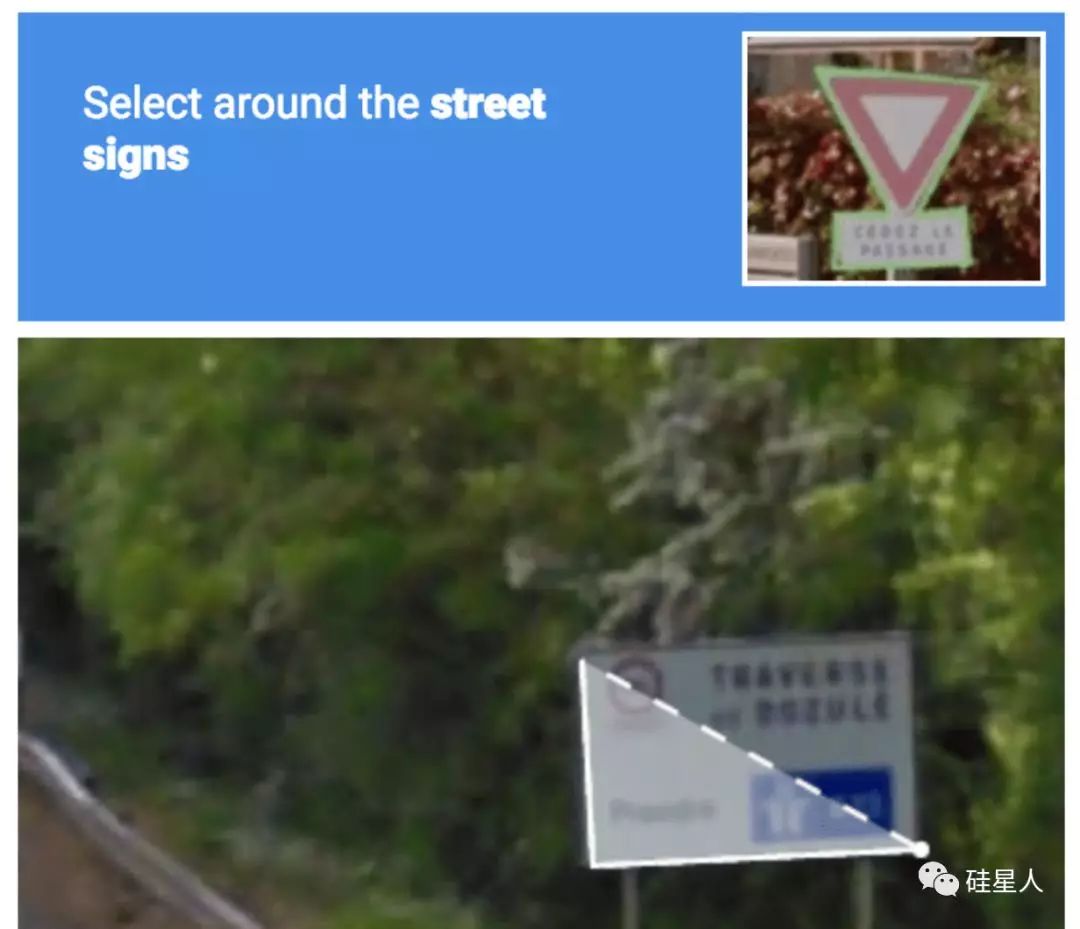
还是把路牌圈出来:

感觉都是在教无人驾驶的AI认路啊……
其实,“输验证码就是在为AI打工”并不是硅星人想得太多。事实上,我们在输验证码时义务劳动的历史,从古早的文字验证码时期就开始了。
1
每次输入验证码,你都在义务劳动
今天,应用最广的验证码系统就是reCAPTCHA(Completely Automated Public Turing Test To Tell Computers and Humans Apart,区分人机的全自动图灵测试系统)了。
这家如今已被Google收购的公司,承担了世界上大部分网络的人机验证工作(上文给出的三个例子均来自 reCAPTCHA)。
2007 年,reCAPTCHA的创始人之一,卡内基梅隆大学教授路易斯·冯·安(Luis von Ahn)想到:“如果人类与机器各有擅长,能不能利用验证码系统,让人类和机器共同解决问题呢?”

当时,一个亟待解决的问题就是,如何把浩如烟海的人类纸质典籍数字化。
想要数字化文本,一种方法是手工录入。这种方法费时费力,还容易出现录入错误。
另一种方法是先扫描文本,再结合光学文字识别技术录入文字。听起来很美,但有些年代久远或本身质量就差的文本扫描出来后实在是太糊了……

以至于电脑识别出来的文本漏洞百出,根本没法看。

为了解决文本数字化的问题,2007年,路易斯推出了新的验证码系统reCAPTCHA。
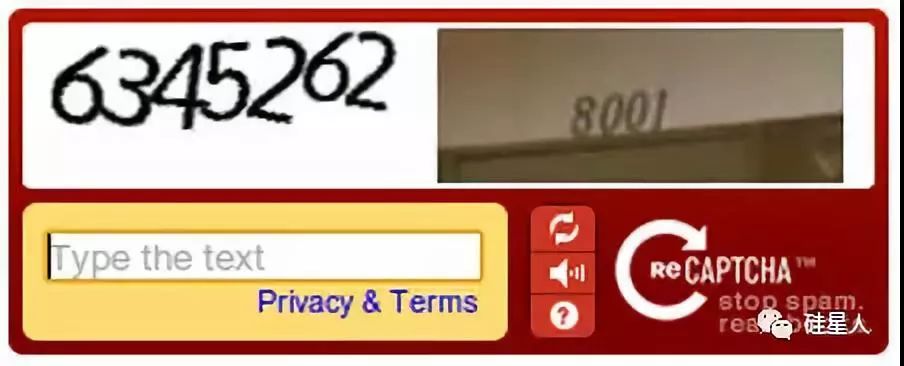
在reCAPTCHA验证码系统里,一个验证码会由两部分构成。
第一部分和之前一样,是自动生成并且经过变形处理的文字,用来检验你是不是真人。而第二部分,则是从无法识别的文本中截取出来的词。

如果用户正确输入前半部分,那么reCAPTCHA就会假设用户输入的后半部分也是正确的,然后把录入结果返回至reCAPTCHA的项目主机。
结果返回主机后,主机还会把这个结果再派发给多个用户进行交叉验证,以确保没有不小心或故意输错单词的情况。
也就是说,真正有效的人机测试在验证码的前半段已经完成,而后半段,就是用户在义务为人类文明做贡献了。
那么,reCAPTCHA到底做了多大贡献呢?
2007年推出之初,reCAPTCHA每天都能帮助录入3000万个字符。2008年,这个数字飙升到了6000万个。粗略统计,在今天,全世界每天都有2亿个字符通过reCAPTCHA录入,相当于人类15万小时的工作量。
也就是说,一个人要不吃不喝不睡连轴转两年半,才能完成 reCAPTCHA 一天的工作量。
到今天为止, reCAPTCHA已经录入了从1851年至今的所有《纽约时报》,共计1300万篇文章。除《纽约时报》外,reCAPTCHA还数字化了超过2500万本书,而全球的图书数量约为1.3亿本。

路易斯在接受媒体The Hustle采访时这样评价reCAPTCHA:“我创造了一个系统,以十秒为单位,数百万小时为增量,来利用世界上最宝贵的资源:人的大脑。”
2
验证码是在剥削我们么?
如果reCAPTCHA的故事到这里就结束了,每个人都会很开心。但事情没那么简单。
2009年,Google以大约2780万美元的价格收购了reCAPTCHA,并开始利用reCAPTCHA帮助标注数据。
正如前文所说,reCAPTCHA的前半段是在验证你是不是真人,后半段就是真人为验证码打工阶段了。
2012年,Google开始把Google街景中难以识别的门牌和路牌加入验证码,请用户帮忙标注。
除了标注门牌路牌,让用户帮忙给数据库分类也是常见的形式之一。比如下图这种请用户“挑出所有有猫的图片”的验证码。
如今,Google AI已经能精确辨认路牌上的文字和数字,准确度和人眼不相上下。
当有一天我们终于用上Google的自动驾驶技术,依靠AI来辨识路牌和路灯时,这背后不能不说没有上千万用户无偿标注的苦劳。

对于这一目的,Google也并不避讳。在reCAPTCHA官网上,Google公开说明了reCAPTCHA集众人之力标注数据、训练AI的“众包”模式。

但是仍有用户对这一点感到不满。
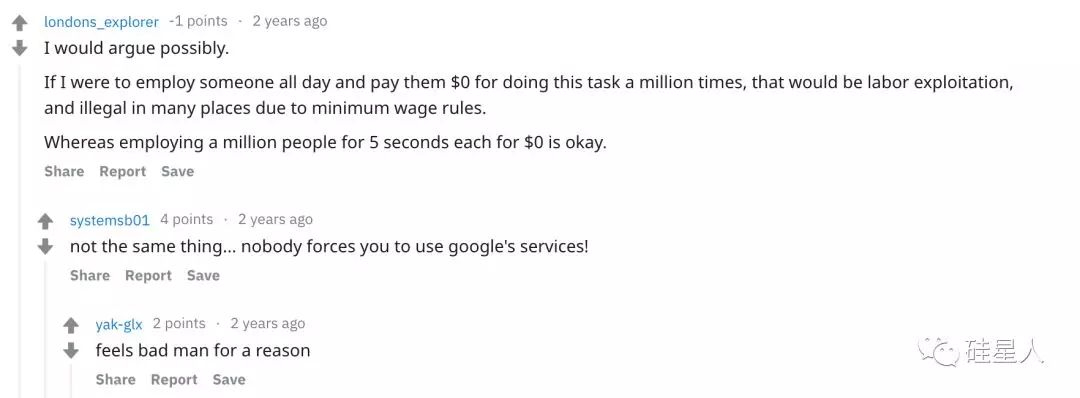
一位觉得验证码不道德的Reddit用户写到:“这就好像让几百万个人每人为你干5秒钟活儿,然后一分钱都不给一样,这合适么!”
3
验证码的前世今生
验证码提出之初,是为了解决一个特别实在的问题。
网络世界这么大,你怎么知道网线另一端是不是一条狗(或者机器人)?
在公开版面上,刷评机器人可以用大量垃圾评论和广告淹没真人用户留下的有价值的信息;在金融交易平台,脚本程序可以靠不停试验来暴力破解密码;在票务网站,我敢说你就算有十只手也抢不过自动刷票的黄牛……
如何确定网络请求是真人发送的,成了维护网络环境和保护用户安全的大问题。
2002 年,正是路易斯·冯·安提出了一种切实可行的解决方案,能分清网线对面“是人是狗”。
虽然计算机的算数和分析能力比人类强得多,但是当时的计算机连“一只小猫在奔跑”这种难不倒三岁小孩儿的图都认不出来。
基于这种思想,路易斯和其他同事合作开发了reCAPTCHA的祖宗CAPTCHA,也就是我们俗称的验证码。
初代验证码一般是一些经过扭曲变形的文字或数字。人类可以识别这些文字(尽管偶尔也会出现连人类也认不出的情况),但机器难以理解字符的含义。

之后,验证码也经历了算数题、选择题,甚至植入广告等类型的迭代,但都掩盖不住一个最致命的问题:虽然CAPTCHA已经是相对比较好的解决方案,但也并非铁板一块。
通过撞库、人工智能识别图像、甚至是把验证码图片返回给人工再批量输入等方法,黑客们总能为垃圾脚本找到可乘之机。
更别提有些验证码,连真人都搞不定!

附加题:请点击图中所有的范伟
正因为验证码浪费时间,辨识难度大,而且对于执行某些特定行为(比如爬数据或做学术研究)的人类用户而言极不友好,验证码长期在“互联网时代最烦人发明”榜上名列前茅。
于是, reCAPTCHA推出了更科学的验证系统。这种验证系统会检测用户的客户端环境,追踪用户的鼠标和键盘操作轨迹,提高了机器人的模拟成本。
用户再也不需要苦哈哈地识别歪歪扭扭的文字,只需要在对话框里点击“我不是机器人”,就能通过验证。
既然已经有了更简单、更安全的替代方式,那么伴随我们成长的验证码,是不是也该被淘汰了呢?这种能解决大问题的“众包模式”,又是否合理呢?
你是怎样看待用验证码“训练”机器这个举措的?
欢迎评论区留言,与大家分享。