【KDD2020】 增量移动用户分析:用于事件流建模的空间知识图谱强化学习方法
论文专栏: KDD2020知识图谱相关论文分享
论文解读者: 北邮 GAMMA Lab 博士生 马昂

题目: 增量移动用户分析:用于事件流建模的空间知识图谱强化学习方法
会议: KDD 2020
论文地址: https://dl.acm.org/doi/pdf/10.1145/3394486.3403128
推荐理由: 这篇论文研究了用于增量移动用户分析的强化学习和空间知识图谱的集成,旨在通过从混合用户事件流中进行创造性学习。这篇论文提出了将强化学习框架应用于增量移动用户分析中,利用用户与空间知识图谱的交互,模拟智能体与环境的交互,制定用户与空间KG之间的相互更新策略,并结合时间上下文,以量化随时间演变的状态表示。
1 引言
经典的移动用户分析是先收集大规模的时空事件数据,然后利用收集的用户配置文件来表征用户模式和偏好。这种方法忽视用户配置文件的动态性。增量移动用户分析(Incremental Mobile User Profiling,IMUP),旨在通过从事件流中逐步学习来产生更准确的动态更新的用户配置文件。
移动用户分析中的现有工作大致可以分为3类:(1)显式配置文件提取,(2)基于分解的方法(3)基于深度学习的方法。但是,这些研究大多数都不能直接应用于混合用户事件流,也无法实现多用户增量分析。
在本篇文章中,我们将使用强化学习框架解决增量移动用户分析问题。在此框架中,Agent是下一次访问计划者,它试图完美地模仿一组移动用户。环境、状态是由用户和空间知识图谱所构成。动作是给定移动用户将访问的POI,它是由Agent根据环境状态估算做出的决策。用户采取行动访问POI的行为将改变环境,从而更新用户和空间知识图谱的状态,以便于Agent更好地估计下次访问。行动的好坏可以使用Agent的活动模式和实际用户的活动模式之间的差距来进行衡量。本文的目标是利用强化学习框架,通过从事件流中进行增量学习来提取环境状态下各种用户的动态表示。
基础知识
Spatial KG. 在空间知识图谱中,存在三种类型的实体:POI,POI类别和位置(即功能区);两种关系:“属于”和“位于”。空间KG被定义为以下三组事实组:(1)<POI,“属于”,POI类别>,和(2)<POI,“位于”,位置>。
Temporal Context. 给定某个区域,我们对其进行网格划分。对于给定的网格,我们计算内部流量inner traffic,流入流量in-flow traffic和流出流量out-flow traffic。然后,可以构建流量矩阵
强化学习:
(1)Agent:下次访问计划者。
(2)Action:动作空间是由所有的POI构成, 假设用户在第 步,访问了某个POI ,则策略将采取操作 。
(3)Environment:环境定义为所有用户和空间KG的组合。
(4)State:状态也是由用户和空间KG所构成,第 步得状态记为 ,
(5)Reward:奖励是由3部分的加权平均计算得到。(i) ,POI访问的真实位置与预测位置之间的距离的倒数;(ii) ,实际和预期访问类别之间的相似性;(iii) 预测的POI访问是否为真实访问。
给定用户和空间KG,我们的目标是找到一个映射函数 𝑓,将环境状态作为输入(即,用户和空间KG的表示),并在下一步中输出状态,形式化的表示为,
2 方法
方法框架如下图所示,分为两部分:Policy learning、State update.
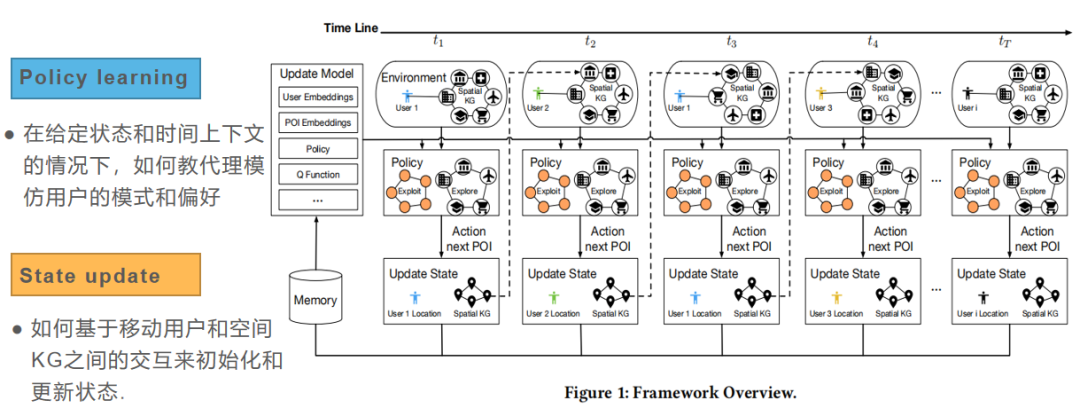
2.1 策略学习
-
网络结构
策略学习这一部分网络结构使用强化学习领域的Deep Q-Network(DQN),由于DQN无法将图形结构状态(即空间KG)作为输入。因此,我们提出了如图2所示的分层池化模块。
由于DQN仅将向量/矩阵作为输入,因此我们要图池化操作来将空间知识图谱的图结构状态G转换为向量。当前的图池化操作不适合空间KG的异构性。因此,我们以分层方式设计图池化操作。
-
首先,依据两种类型关系“属于”、“位于”将空间KG分为两个图:“位置图”、“所属图”。 -
然后,针对“位置图”、“所属图”利用图平均池化分别生成图的向量化表示。 -
最后,对两个图的向量化表示进行平均池化,以获得空间KG的单个统一向量化表示 。
在分层池化模块之后,我们将用户的表示与空间KG的表示拼接起来,作为全连接(FC)层的输入。然后,FC层会将给定状态 映射为空间KG中每个POI的一组 。该策略选择具有最高 的POI作为预测结果。
-
在经验回放中改进采样策略
由于POI的访问的空间很大,因此所提出的强化学习框架计算量会很大。因此,我们提出了一种基于经验回放的训练策略,以加快exploration过程。训练策略包括两个阶段:优先级分配、采样策略。
(1)优先级分配
为每个数据样本分配优先级分数,我们设计两种类型的优先级分数,基于奖励和基于时间差异。
-
直观上,POI访问操作的奖励越高,agent模仿用户的能力就越强。
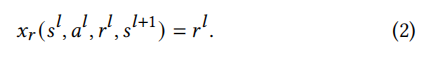
-
最初设置TD-error是为了更新DQN。TD误差越大,代表agent学习的数据样本就越有价值和有用。
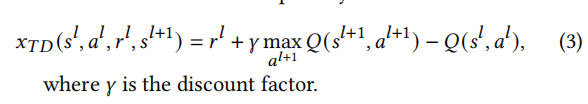
(2)采样策略
从内存中选择数据样本进行训练,在获得优先级得分 之后,我们需要根据优先级得分构造一个分布用于采样数据。
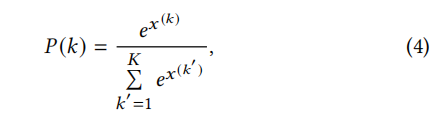
然后,我们基于分配的概率从内存中抽样一批数据。
2.2 状态更新
状态更新为两部分,状态初始化、状态更新。
-
状态初始化
(1) 针对用户,我们利用StructRL初始化用户状态(表示),StructRL的详细介绍请参考论文Adversarial Substructured Representation Learning for Mobile User Profiling,下载地址:https://dl.acm.org/doi.org/10.1145/3292500.3330869。
(2)针对空间KG,我们利用TransD初始化空间KGstate(表示),TransD的详细介绍请参考论文Knowledge Graph Embedding via Dynamic Mapping Matrix,下载地址:https://www.aclweb.org/anthology/P15-1067.pdf。
-
状态更新
(1)针对用户,我们基于用户和空间知识图谱POI之间的交互来更新用户状态。
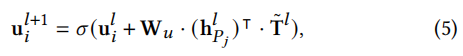
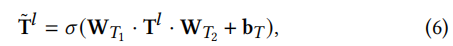

3 实验
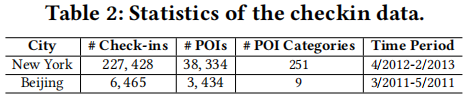
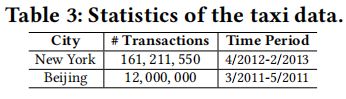
实验数据分为两类,签到数据集、交通数据集。
-
签到数据集
-
交通数据集
评价指标:
-
Precision on Category (Prec_Cat),度量POI类别预测的准确度
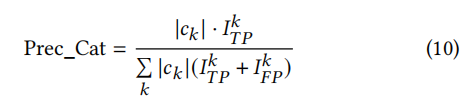
-
Recall on Category (Rec_Cat),度量POI类别预测的召回率
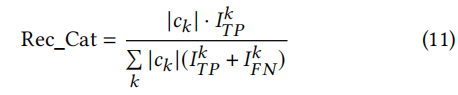
-
Average Similarity (Avg_Sim),度量POI类别的相似性程度
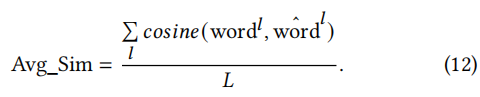
-
Average Distance (Avg_Dist),度量预测POI与用户实际访问POI之间的距离
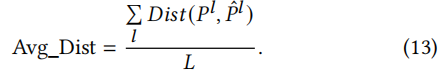
实验评价了3个方面,实验结果如下图所示。
(1)所提方法(IMUP-r、IMUP-TD分别表示采取基于奖励的优先级得分、基于TD-error的优先级得分)与基线方法的效果比较。实验表明,基于𝑇𝐷的优先级的性能比基于奖励的优先级稍好,𝑇𝐷错误更直接地证明了由某些数据样本引起的下次访问预测的改进。𝑇𝐷误差越大,DQN改善的越多。
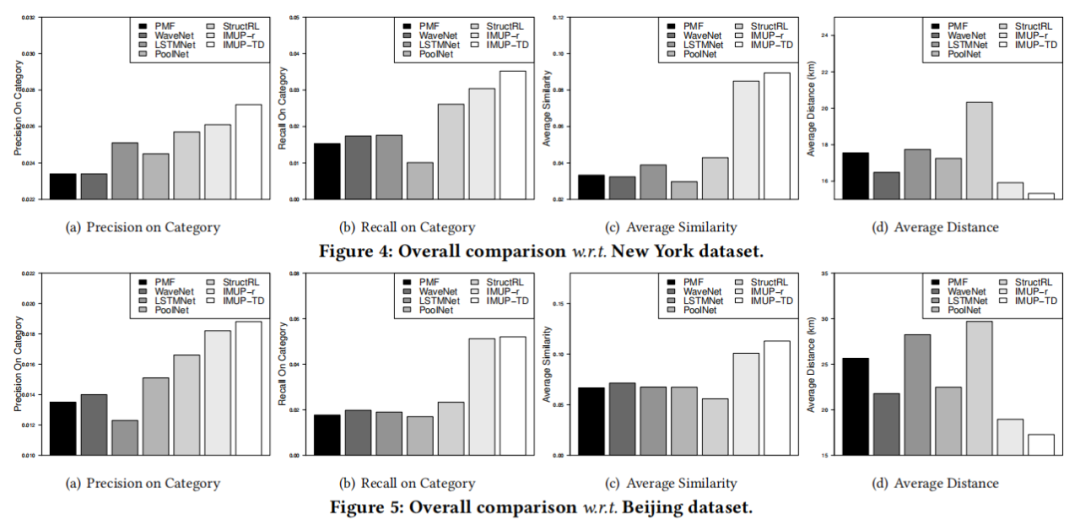
(2)空间知识图谱在建模用户表示方面的贡献(IMUP-表示仅将用户和POI表示作为环境状态,而其他组件保持不变)。实验表明,“ IMUP”的性能都优于“ IMUP-”。结果证实,来自空间KG的语义集成确实增强了访问事件中用户偏好的建模。同时,增量更新的下次访问计划者(代理)被强制从空间KG引入语义,以模仿个性化的用户模式,并与增量更新的用户表示(状态)保持同步。
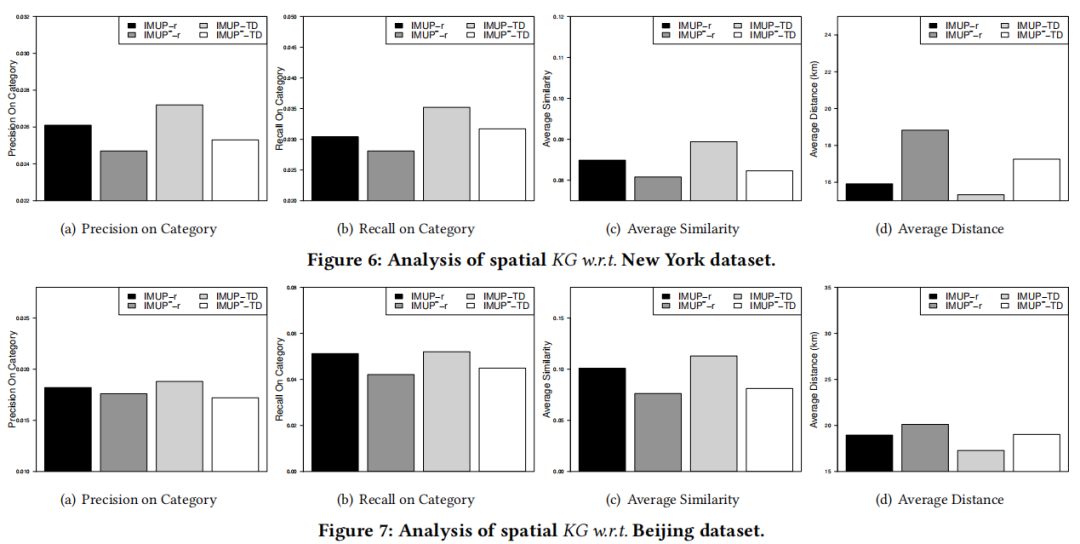
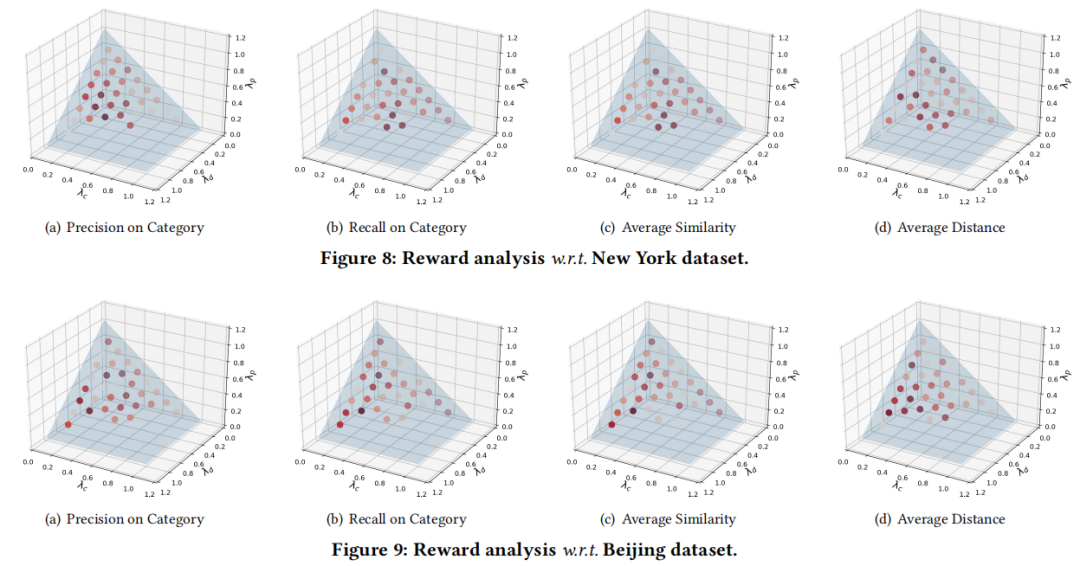
(3)奖励不同部分权重的影响。一个有趣的观察结果是,在“类别精确度”,“类别召回”和“平均相似度”的情况下,类别相似度 的贡献高于其他两个因素,但在“平均距离”情况下 ,距离 和POI 是否访问 的贡献超过类别相似度 。原因很直观,类别相似度 直接决定了策略训练的方向,以探索更多相似的POI类别,而 和 则指导策略找到与用户意图尽可能接近的POI。
4 总结
我们研究了增量移动用户分析问题。将空间KG集成到强化学习中,以逐步学习用户表示并生成下次访问预测。具体来说,我们将状态表述为用户和空间KG的组合,其中建模了用户与空间KG的交互,以基于时间上下文增量更新用户和空间KG的表示。实验观察到空间KG引入的语义信息,改进了用户表示的建模,以更好地理解用户模式和偏好。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“KGME” 就可以获取《【KDD2020】 增量移动用户分析:用于事件流建模的空间知识图谱强化学习方法》专知下载链接





