MIT大神利用半监督or自监督学习,巧妙破解数据不平衡问题!


-
半监督学习 --- 也即利用更多的无标签数据;或者, -
自监督学习 --- 不利用任何其他数据,仅通过在现有的不平衡数据上先做一步不带标签信息的自监督预训练(self-supervised pre-training),
研究背景
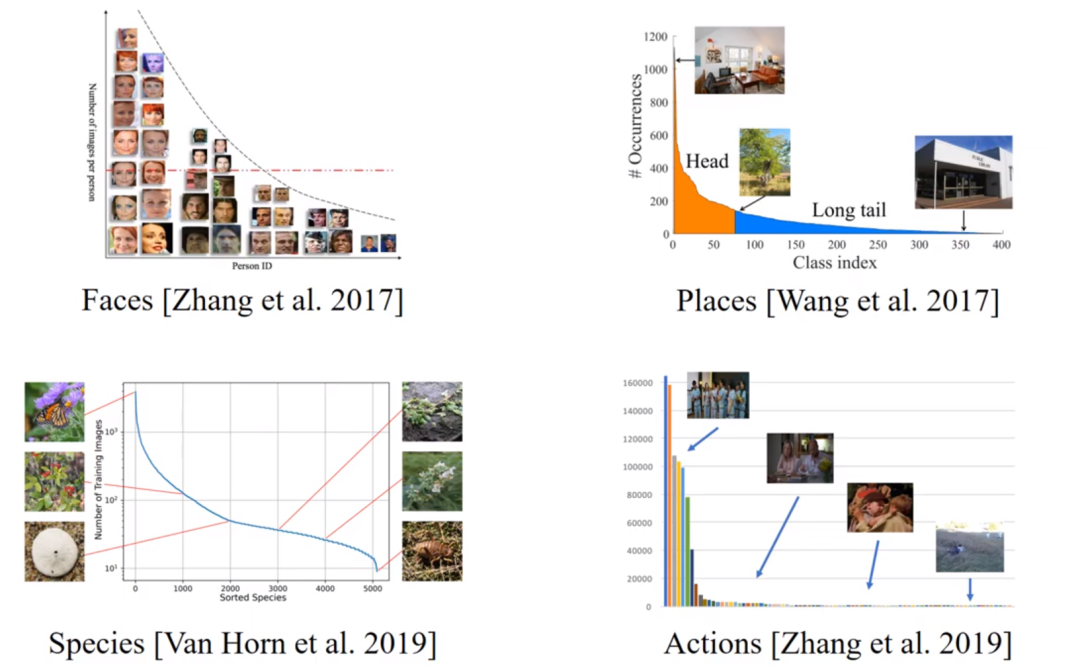
-
重采样(re-sampling): 更具体可分为对少样本的过采样,或是对多样本的欠采样[8]。但因过采样容易overfit到minor class,无法学到更鲁棒易泛化的特征,往往在非常不平衡数据上表现会更差;而欠采样则会造成major class严重的信息损失,导致欠拟合发生。 -
数据合成(synthetic samples): 即生成和少样本相似的“新”数据。经典方法SMOTE[9],思路简单来讲是对任意选取的少类样本,用K近邻选取其相似样本,通过对样本线性插值得到新样本。这里会想到和mixup[10]很相似,于是也有imbalance的mixup版本出现。 -
重加权(re-weighting): 对不同类别(甚至不同样本)分配不同权重。注意这里的权重可以是自适应的。此类方法的变种有很多,有最简单的按照类别数目的倒数来做加权,按照“有效”样本数加权,根据样本数优化分类间距的loss加权,等等。 -
迁移学习(transfer learning): 这类方法的基本思路是对多类样本和少类样本分别建模,将学到的多类样本的信息/表示/知识迁移给少类别使用。代表性文章有[13][14]。 -
度量学习(metric learning): 本质上是希望能够学到更好的embedding,对少类附近的boundary/margin更好的建模。有兴趣的同学可以看看[15][16]。 -
元学习/域自适应(meta learning/domain adaptation): 分别对头部和尾部的数据进行不同处理,可以去自适应的学习如何重加权,或是formulate成域自适应问题[18]。 -
解耦特征和分类器(decoupling representation & classifier): 最近的研究发现将特征学习和分类器学习解耦,把不平衡学习分为两个阶段,在特征学习阶段正常采样,在分类器学习阶段平衡采样,可以带来更好的长尾学习结果。这也是目前的最优长尾分类算法。
研究动机和思路
半监督框架下的不均衡学习
 和
和
 ,但是相同方差的Guassian mixture模型,我们可以很容易验证其贝叶斯最优分类器为:
,但是相同方差的Guassian mixture模型,我们可以很容易验证其贝叶斯最优分类器为:
 。因此为了更好的分类,我们希望学习到他们的平均均值,
。因此为了更好的分类,我们希望学习到他们的平均均值,
 。假设我们已有一个在不平衡的训练集上得到的基础分类器
。假设我们已有一个在不平衡的训练集上得到的基础分类器
 以及一定量的无标签的数据,我们可以通过这个基础分类器给这些数据做pseudo-label。令
以及一定量的无标签的数据,我们可以通过这个基础分类器给这些数据做pseudo-label。令
 和
和
 代表pseudo-label为正和为负的数据的数量。为了估计
代表pseudo-label为正和为负的数据的数量。为了估计
 ,最简单的方法我们可以通过pseudo-label给这些对应的没有标签的数据取平均得到
,最简单的方法我们可以通过pseudo-label给这些对应的没有标签的数据取平均得到
 。假设
。假设
 代表基础分类器对于两个类的准确度的gap。这样的话我们推出以下定理:
代表基础分类器对于两个类的准确度的gap。这样的话我们推出以下定理:
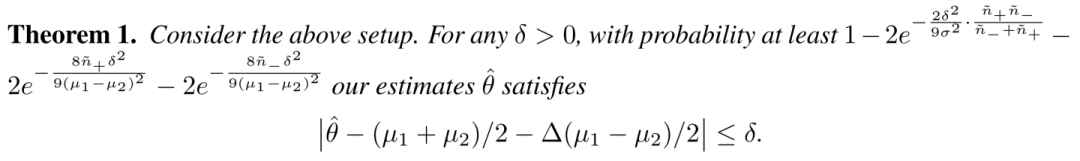
-
原始数据集的不平衡性会影响我们最后estimator的准确性 。越不平衡的数据集我们expect 基础分类器有一个更大的 。越大的
影响我们的estimator
到理想的均值之间的距离。
-
无标签数据集的不平衡性影响我们能够得到一个好的estimator的概率 。对于还不错的基础分类器, 可以看做是对于无标签数据集的不平衡性的近似。我们可以看到,当
,如果无标签数据很不平衡,那么数据少的一项会主导另外一项,从而影响最后的概率。


 上正常训练获得一个中间步骤分类器
上正常训练获得一个中间步骤分类器
 ,并将其应用于生成未标记数据
,并将其应用于生成未标记数据
 的伪标签
的伪标签
 ;通过结合两部分数据,我们最小化损失函数
;通过结合两部分数据,我们最小化损失函数
 以学习最终模型
以学习最终模型
 。
和
的学习策略,因此半监督框架也能很轻易的和现有类别不平衡的算法相结合。
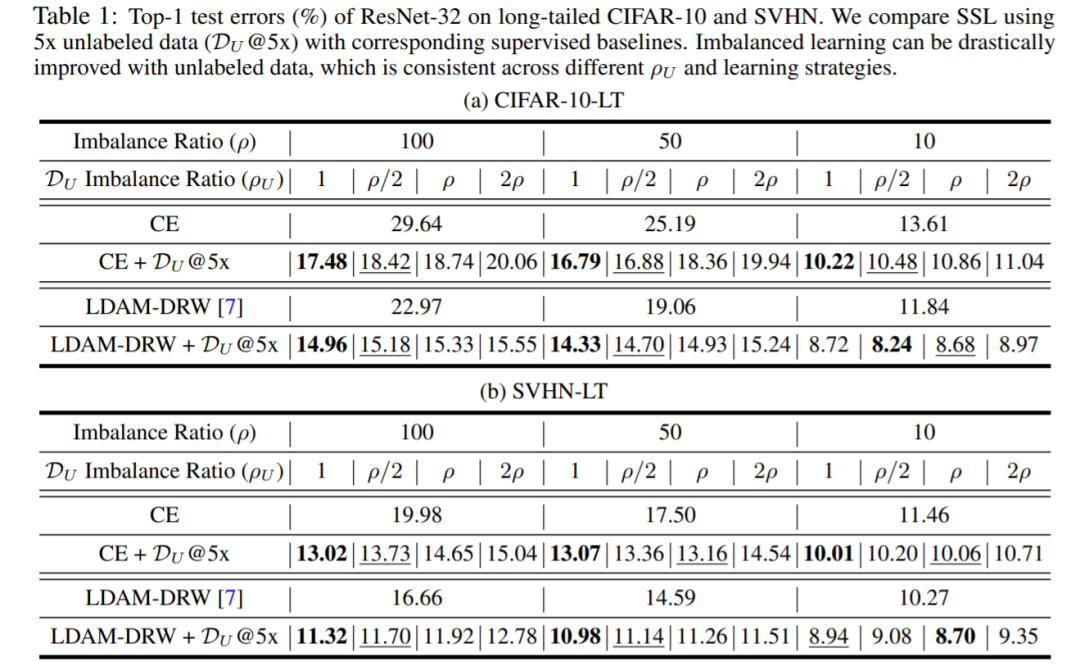
和
的典型分布如下):
。
和
的学习策略,因此半监督框架也能很轻易的和现有类别不平衡的算法相结合。
和
的典型分布如下):

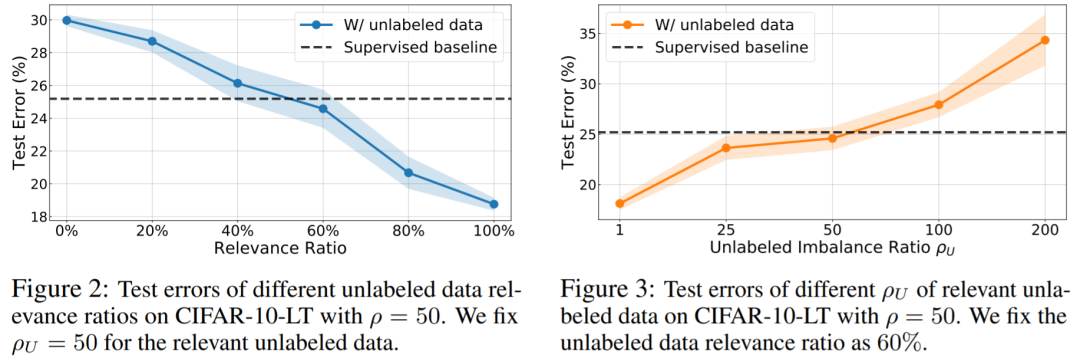
关于半监督不均衡学习的进一步思考
自监督框架下的不均衡学习
 维Guassian mixture的toy example。这次我们考虑两个类有相同的均值(都为0)但是不同的方差,
维Guassian mixture的toy example。这次我们考虑两个类有相同的均值(都为0)但是不同的方差,
 和
和
 。
。
 )。我们考虑线性的分类器
)。我们考虑线性的分类器
 ,
,
 ,并且用标准的error probability,
,并且用标准的error probability,
 ,作为分类器的衡量标准。在正常的训练中,公式里的feature代表的是raw data,
,作为分类器的衡量标准。在正常的训练中,公式里的feature代表的是raw data,
 。在这种情况下,我们可以首先证明上述的线性分类器一定会有至少
。在这种情况下,我们可以首先证明上述的线性分类器一定会有至少
 的error probability(详见文章)。接下来我们考虑当有self-supervision的情况。假设一个好的self-supervised task帮助我们学习到了新的representation,
的error probability(详见文章)。接下来我们考虑当有self-supervision的情况。假设一个好的self-supervised task帮助我们学习到了新的representation,
 ,
,
 。我们考虑用
。我们考虑用
 作为线性分类器的输入。在上述的分类器范围内, 我们可以得到一个分类器,
作为线性分类器的输入。在上述的分类器范围内, 我们可以得到一个分类器,


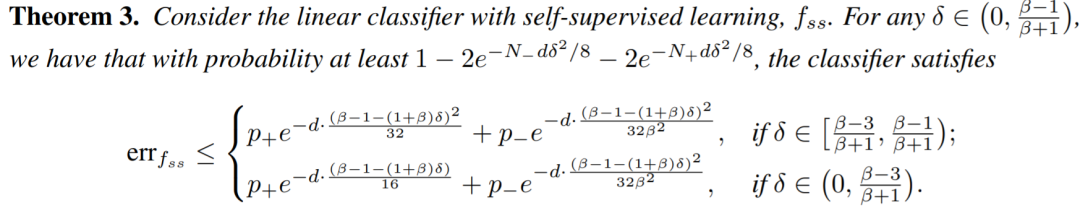
-
有很高的概率,我们能得到一个更好的分类器 。这个分类器的error probability随数据维度 的增加而指数型减小。对于如今常见的高维数据(如图像)这种性质是我们希望得到的。
-
训练数据的不平衡性会影响我们能够得到这样一个好的分类器的概率。 上文中, 和
代表训练数据里不同类的数量。从
和
这两项中我们可以发现,当数据越多且越平衡,我们就有更高的概率得到一个好的分类器。




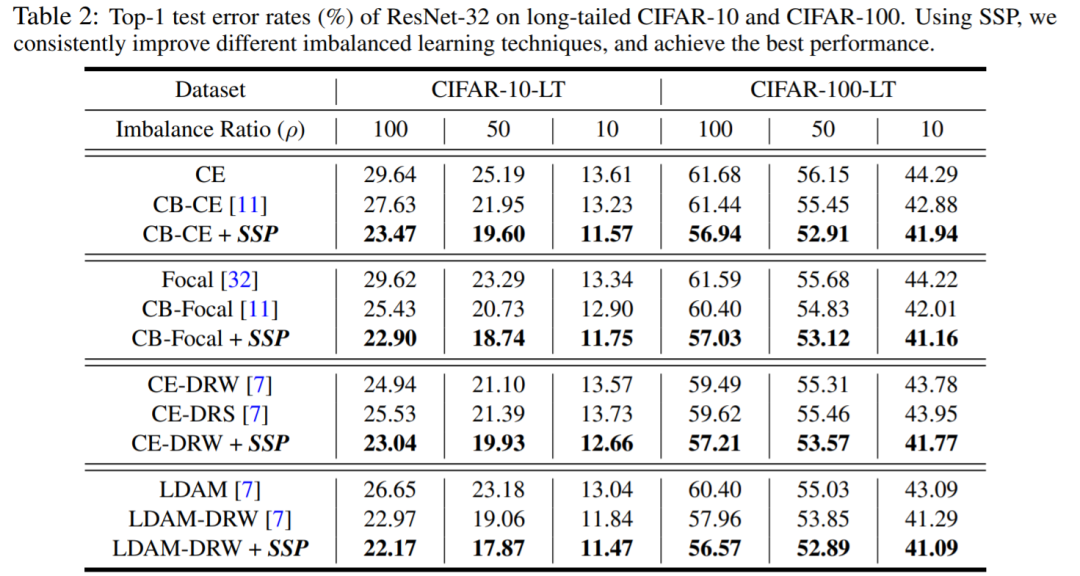
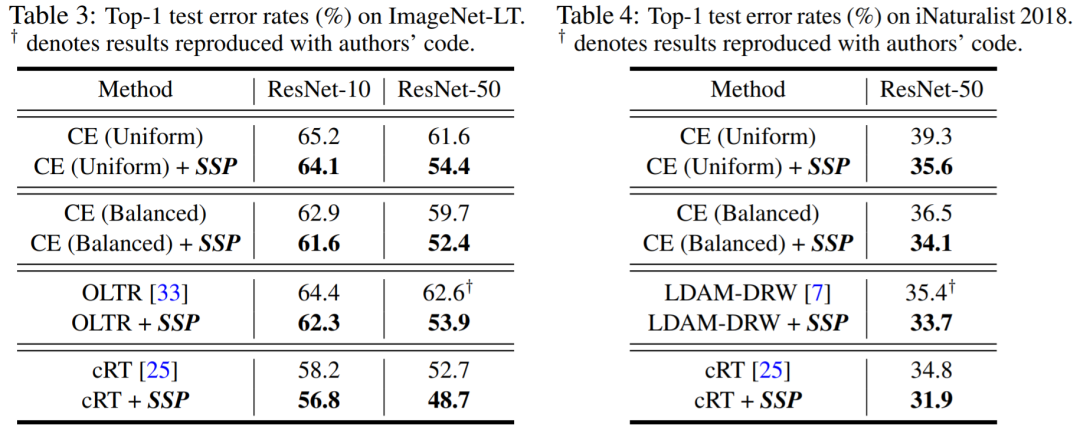
结语
在10月1日头条《秋天的第一本AI书:周志华亲作森林书&贾扬清力荐天池书 | 赠书》留言区留言,谈一谈你对这两本书的看法或有关的学习、竞赛等经历。
AI 科技评论将会在留言区选出15名读者,送出《阿里云天池大赛赛题解析——机器学习篇》10本,《集成学习:基础与算法》5本,每人最多获得其中一本。
活动规则:
1. 在留言区留言,留言点赞最高的前 15 位读者将获得赠书,活动结束后,中奖读者将按照点赞排名由高到低的顺序优先挑选两本书中的其中一本,获得赠书的读者请添加AI科技评论官方微信(aitechreview)。
2. 留言内容会有筛选,例如“选我上去”等内容将不会被筛选,亦不会中奖。
3. 本活动时间为2020年10月1日 - 2020年10月8日(23:00),活动推送内仅允许中奖一次。

点击阅读原文,直达NeurIPS小组~
登录查看更多
相关内容


相关VIP内容
相关资讯
相关论文