【前沿】如何在 GPU 上加速数据科学

【导读】我们认为使用大型模型架构和相同数据在XLNet 和BERT之间进行公平的比较研究具有重要的科学价值。
数据科学家需要算力。无论您是用 pandas 处理一个大数据集,还是用 Numpy 在一个大矩阵上运行一些计算,您都需要一台强大的机器,以便在合理的时间内完成这项工作。
在过去的几年中,数据科学家常用的 Python 库已经非常擅长利用 CPU 能力。
GPUs vs CPUs:并行处理
有了大量的数据,CPU 就不会切断它了。
一个超过 100GB 的数据集将有许多数据点,数据点的数值在数百万甚至数十亿的范围内。有了这么多的数据点要处理,不管你的 CPU 有多快,它都没有足够的内核来进行有效的并行处理。如果你的 CPU 有 20 个内核(这将是相当昂贵的 CPU),你一次只能处理 20 个数据点!
CPU 在时钟频率更重要的任务中会更好——或者根本没有 GPU 实现。如果你尝试执行的流程有一个 GPU 实现,且该任务可以从并行处理中受益,那么 GPU 将更加有效。

多核系统如何更快地处理数据。对于单核系统(左),所有 10 个任务都转到一个节点。对于双核系统(右),每个节点承担 5 个任务,从而使处理速度加倍
深度学习已经在利用 GPU 方面发挥了相当大的作用。许多在深度学习中完成的卷积操作是重复的,因此在 GPU 上可以大大加速,甚至可以达到 100 次。
今天的数据科学没有什么不同,因为许多重复的操作都是在大数据集上执行的,库中有 pandas、Numpy 和 scikit-learn。这些操作也不太复杂,无法在 GPU 上实现。
用 Rapids 加速 GPU
Rapids 是一套软件库,旨在利用 GPU 加速数据科学。它使用低级别的 CUDA 代码实现快速的、GPU 优化的算法,同时它上面还有一个易于使用的 Python 层。
Rapids 的美妙之处在于它与数据科学库的集成非常顺利,比如 pandas 数据帧就很容易通过 Rapids 实现 GPU 加速。下图说明了 Rapids 如何在保持顶层易用性的同时实现低层的加速。
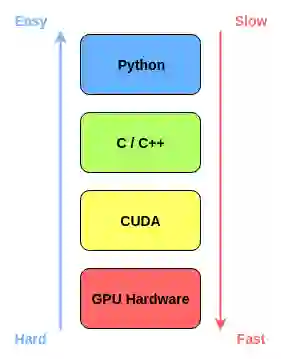
Rapids 利用了几个 Python 库:
cuDF-Python GPU 数据帧。它几乎可以做 pandas 在数据处理和操作方面所能做的一切。
cuML-cuGraph 机器学习库。它包含了 Scikit-Learn 拥有的许多 ML 算法,所有算法的格式都非常相似。
cuGraph-cuGraph 图处理库。它包含许多常见的图分析算法,包括 PageRank 和各种相似性度量。
如何使用 Rapids
安装
现在你将看到如何使用 Rapids!
要安装它,请访问这个网站,在这里你将看到如何安装 Rapids。你可以通过 Conda 将其直接安装到你的机器上,或者简单地使用 Docker 容器。
安装时,可以设置系统规范,如 CUDA 版本和要安装的库。例如,我有 CUDA 10.0,想要安装所有库,所以我的安装命令是:
conda install -c nvidia -c rapidsai -c numba -c conda-forge -c pytorch -c defaults cudf=0.8 cuml=0.8 cugraph=0.8 python=3.6 cudatoolkit=10.0
一旦命令完成运行,就可以开始用 GPU 加速数据科学了。
对于本教程,我们将介绍 DBSCAN demo 的修改版本。我将使用 Nvidia 数据科学工作站和 2 个 GPU 运行这个测试。
DBSCAN 是一种基于密度的聚类算法,可以自动对数据进行分类,而无需用户指定有多少组数据。在 Scikit-Learn 中有它的实现。
我们将从获取所有导入设置开始。先导入用于加载数据、可视化数据和应用 ML 模型的库。
import osimport matplotlib.pyplot as pltfrom matplotlib.colors import ListedColormapfrom sklearn.datasets import make_circles
make_circles 函数将自动创建一个复杂的数据分布,类似于我们将应用于 DBSCAN 的两个圆。
让我们从创建 100000 点的数据集开始,并在图中可视化:
X, y = make_circles(n_samples=int(1e5), factor=.35, noise=.05)X[:, 0] = 3*X[:, 0]X[:, 1] = 3*X[:, 1]plt.scatter(X[:, 0], X[:, 1])plt.show()

使用 Scikit-Learn 在 CPU 上运行 DBSCAN 很容易。我们将导入我们的算法并设置一些参数。
from sklearn.cluster import DBSCANdb = DBSCAN(eps=0.6, min_samples=2)
我们现在可以通过调用 Scikit-Learn 中的一个函数对循环数据使用 DBSCAN。在函数前面加上一个「%」,就可以让 Jupyter Notebook 测量它的运行时间。
%%timey_db = db.fit_predict(X)
这 10 万个点的运行时间是 8.31 秒,如下图所示:
GPU 上带 Rapids 的 DBSCAN
现在,让我们用 Rapids 进行加速!
首先,我们将把数据转换为 pandas.DataFrame 并使用它创建一个 cudf.DataFrame。pandas.DataFrame 无缝转换成 cudf.DataFrame,数据格式无任何更改。
import pandas as pdimport cudfX_df = pd.DataFrame({ fea%d %i: X[:, i] for i in range(X.shape[1])})X_gpu = cudf.DataFrame.from_pandas(X_df)
然后我们将从 cuML 导入并初始化一个特殊版本的 DBSCAN,它是 GPU 加速的版本。DBSCAN 的 cuML 版本的函数格式与 Scikit-Learn 的函数格式完全相同:相同的参数、相同的样式、相同的函数。
from cuml import DBSCAN as cumlDBSCANdb_gpu = cumlDBSCAN(eps=0.6, min_samples=2)
最后,我们可以在测量运行时间的同时运行 GPU DBSCAN 的预测函数。
%%timey_db_gpu = db_gpu.fit_predict(X_gpu)
GPU 版本的运行时间为 4.22 秒,几乎加速了 2 倍。由于我们使用的是相同的算法,因此结果图也与 CPU 版本完全相同。
我们从 Rapids 获得的加速量取决于我们正在处理的数据量。一个好的经验法则是,较大的数据集将更加受益于 GPU 加速。在 CPU 和 GPU 之间传输数据有一些开销时间——对于较大的数据集,开销时间变得更「值得」。
我们可以用一个简单的例子来说明这一点。
我们将创建一个随机数的 Numpy 数组并对其应用 DBSCAN。我们将比较常规 CPU DBSCAN 和 cuML 的 GPU 版本的速度,同时增加和减少数据点的数量,以了解它如何影响我们的运行时间。
下面的代码说明如何进行测试:
import numpy as npn_rows, n_cols = 10000, 100X = np.random.rand(n_rows, n_cols)print(X.shape)X_df = pd.DataFrame({ fea%d %i: X[:, i] for i in range(X.shape[1])})X_gpu = cudf.DataFrame.from_pandas(X_df)db = DBSCAN(eps=3, min_samples=2)db_gpu = cumlDBSCAN(eps=3, min_samples=2)%%timey_db = db.fit_predict(X)%%timey_db_gpu = db_gpu.fit_predict(X_gpu)
检查下面的 Matplotlib 结果图:
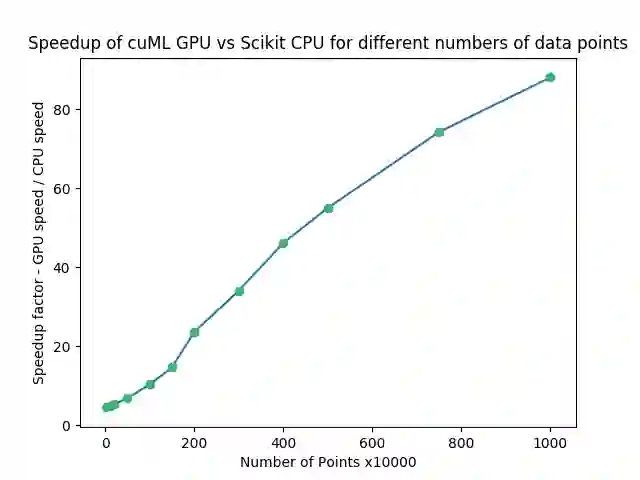
当使用 GPU 而不是 CPU 时,数量会急剧增加。即使在 10000 点(最左边),我们的速度仍然是 4.54x。在更高的一端,1 千万点,我们切换到 GPU 时的速度是 88.04x!
Via:https://www.kdnuggets.com/2019/07/accelerate-data-science-on-gpu.html
来源:AI科技评论

【重要通知】关于开展2019年度中国自动化学会会士候选人提名工作的通知
【重要通知】关于2019年度CAA科学技术奖励推荐工作的通知
【重要通知】关于开展2019年度中国自动化与人工智能创新团队奖推荐工作的通知
【CAA】中国自动化学会选举产生第十一届理事会领导机构(内附名单)
热烈祝贺中国自动化学会常务理事、火箭军工程大学教授胡昌华荣获中共中央军委通令记功
地址:北京市海淀区中关村东路95号
邮编:100190
电话:010-82544542(综合)
010-62522472(会员)
010-62522248(学术活动)
010-62624980(财务)
传真:010-62522248
邮箱:caa@ia.ac.cn
官方微信公众号(英文)
名称:CAA OFFICIAL
微信号:caaofficial

会员微信公众号
名称:CAA会员服务
微信号:caa-member






