2019年机器学习框架之争: PyTorch主导学术界,工业界首选TensorFlow
【导读】自从2012年深度学习重新流行以来,许多机器学习框架便成为研究人员和行业从业人员的新宠。从早期Caffe和Theano到行业新宠的PyTorch和TensorFlow,可选的框架太多,你或许很难很难抉择使用哪个框架。在2019年,机器学习框架之战还有两个主要竞争者:PyTorch和TensorFlow。 本文分析表明,研究人员正在放弃TensorFlow并大量涌向PyTorch。同时,在工业界中,Tensorflow当前是首选平台,但长期以来可能并非如此。
PyTorch在研究领域的主导地位不断提高
数据表明,在顶级研究会议上,使用PyTorch与Tensorflow的论文之间的比率。所有的线条都在向上倾斜,2019年的每个主要会议大多数论文都使用了Pytorch。
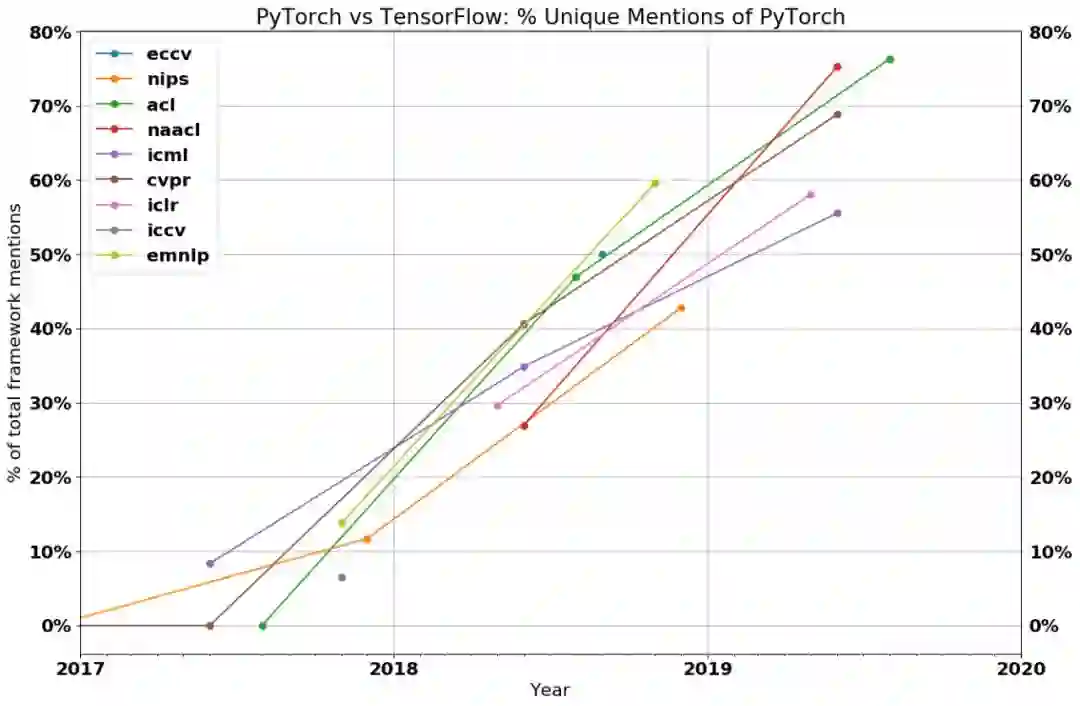

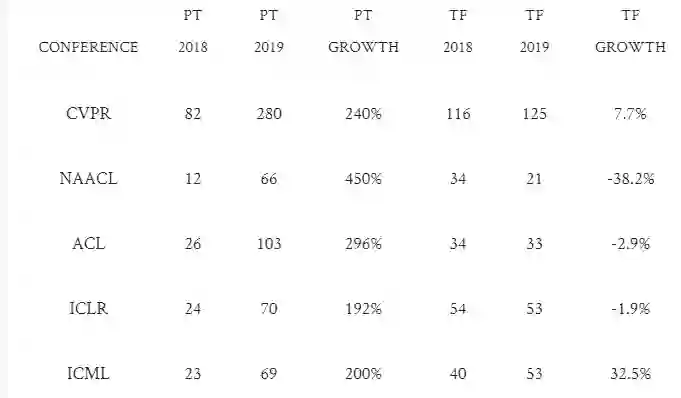
在2018年,PyTorch是少数派。现在,它是绝大多数。CVPR中,使用PyTorch占69%,NAACL和ACL中占75%以上,而ICLR和ICML中占50%以上。PyTorch不仅在视觉和语言会议上的统治地位最强,而且ICLR和ICML等常规机器学习会议上,PyTorch也比TensorFlow受欢迎。
除了ICML之外,没有会议上TensorFlow的增长甚至与总论文数增长保持同步。在NAACL,ICLR和ACL,TensorFlow今年的论文实际上少于去年。
TensorFlow才应该担心它的未来!
为什么研究人员喜欢PyTorch?
简单。它与numpy类似,非常具有python风格,并且可以轻松地与其他Python生态系统集成。例如,你可以在PyTorch模型中的任何地方简单地插入一个pdb断点,并用于调试。在TensorFlow中,调试模型需要Session,并且最终变得更加棘手。
很棒的API。与TensorFlow的API相比,大多数研究人员更喜欢PyTorch的API。部分原因是PyTorch的设计更好,部分原因是TensorFlow通过多次切换API(‘layers’ -> ‘slim’ -> ‘estimators’ -> ‘tf.keras’)而变得很复杂。
性能。尽管事实上PyTorch的动态图提供的优化机会很少,但有许多传闻称PyTorch的速度甚至快于TensorFlow。目前尚不清楚这是否真的成立,但至少,TensorFlow在这一领域还没有获得决定性的优势。
TensorFlow的研究前景如何?
即使TensorFlow在功能方面与PyTorch达到了同等水平,PyTorch也已经覆盖了大多数社区。这意味着PyTorch的实现将更容易找到,作者将更有动力在PyTorch中发布代码。因此,回迁到TensorFlow 2.0的任何迁移都可能很慢。
TensorFlow在Google / DeepMind中将始终拥有一定的受众群体,。即使是现在,Google想要招募的许多研究人员已经已经在不同层次上偏爱PyTorch,而且我听到有人抱怨说Google内部的许多研究人员都希望使用TensorFlow以外的框架。
此外,PyTorch的统治地位可能会开始切断Google研究人员与其他研究社区的联系。他们不仅很难在外部研究的基础上进行构建,而且外部研究人员也不太可能在Google发布的代码基础上进行构建。
TensorFlow 2.0是否能够吸引更多人用回TensorFlow还有待观察。尽管Eager模式一定会很吸引人,但Keras API却不能说同样的话。
PyTorch和TensorFlow用于生产
尽管PyTorch现在在研究中处于主导地位,但在工业界表明TensorFlow仍然是主导框架。
因此,如果PyTorch在研究人员中变得如此受欢迎,为什么它在工业上没有看到同样的成功呢?一个明显的第一个答案就是惯性。TensorFlow早于PyTorch出现,而且行业采用新技术的速度比研究人员要慢。另一个原因是TensorFlow在生产方面比PyTorch更好。
根本而言,研究人员和行业的需求是不同的。
研究人员关心他们能够以多快的速度进行研究,该研究通常是在相对较小的数据集(可以容纳在一台计算机上的数据集)上运行的,并且运行在<8个GPU上。通常,这不是由性能方面的考虑来决定的,而是由他们快速实施新想法的能力来解决的。另一方面,工业界认为性能是重中之重。尽管将运行时间提高10%对研究人员而言毫无意义,但这可以直接为公司节省数百万美元的费用。
另一个区别是部署。研究人员将在自己的计算机或专用于运行研究工作的服务器集群上进行实验。另一方面,行业有很多限制/要求。
没有Python。一些公司将运行服务器,这些服务器的Python运行时开销太大。
移动。您无法在移动二进制文件中嵌入Python解释器。
服务。功能全面,例如无停机更新模型,在模型之间无缝切换,在预测时进行批处理等。
TensorFlow是专门针对这些要求而构建的,并为所有这些问题提供了解决方案:图形格式和执行引擎本来就不需要Python,TensorFlow Lite和TensorFlow Serving服务分别解决了移动和服务注意事项。
从历史上看,PyTorch未能满足这些考虑,因此大多数公司目前在生产中使用TensorFlow。
框架“融合”
在2018年底附近,两个重大事件发生了:
PyTorch引入了JIT编译器和“ TorchScript”,从而引入了基于图形的功能。
TensorFlow宣布默认情况下它们将转为Eager模式。
显然,这些都是试图解决各自弱点的举动。那么这些功能到底是什么?它们必须提供什么?
PyTorch TorchScript
PyTorch JIT是PyTorch的中间表示(IR),称为TorchScript。TorchScript是PyTorch的“图形”表示。您可以使用跟踪或脚本模式将常规PyTorch模型转换为TorchScript。跟踪采用一个函数和一个输入,记录使用该输入执行的操作,并构造IR。跟踪虽然简单明了,但也有其缺点。例如,它无法捕获未执行的控制流。例如,如果执行条件块,则无法捕获条件块的错误块。
脚本模式采用一个函数/类,重新解释Python代码并直接输出TorchScript IR。这允许它支持任意代码,但是实际上它需要重新解释Python。
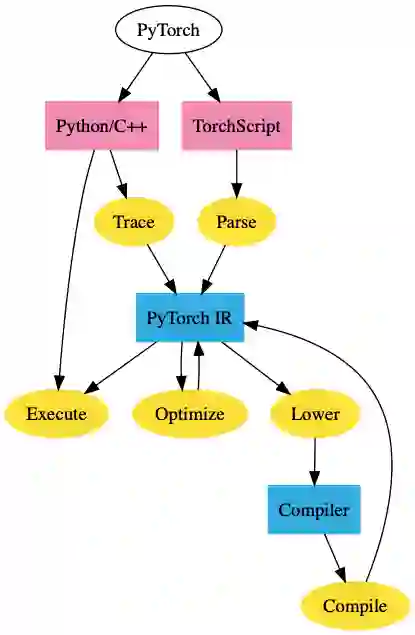
一旦PyTorch模型进入此IR,我们将获得图形模式的所有好处。我们可以在不依赖Python的情况下以C ++部署PyTorch模型,或对其进行优化。
Tensorflow Eager 模式
在API级别,TensorFlow Eager 模式与PyTorch的Eager 模式基本相同, 这为TensorFlow优势(易于使用,可调试性等)。
但是,这也给TensorFlow带来了同样的缺点。TensorFlow急切模型无法导出到非Python环境,无法优化,无法在移动设备上运行等。
这使TensorFlow与PyTorch处于同一位置,并且它们以基本上相同的方式解析它-您可以跟踪代码(tf.function)或重新解释Python代码(Autograph)。
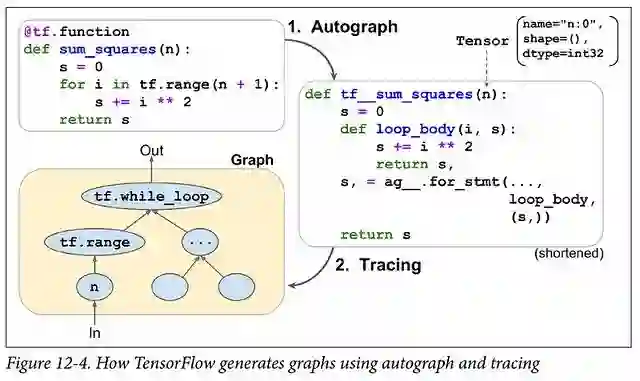
因此,TensorFlow的Eager模式并不能真正为您提供“两全其美”的体验。虽然确实可以使用tf.function批注将Eager的代码转换成静态图,但这绝不是一个无缝的过程(PyTorch的TorchScript也存在类似的问题)。跟踪从根本上受到限制,并且重新解释Python代码本质上需要重写许多Python编译器。当然,通过限制深度学习中使用的Python子集,可以大大简化范围。
默认情况下,在启用Eager模式时,TensorFlow会强制用户选择-使用急切执行以简化使用并需要重写以进行部署,或者完全不使用快切执行。尽管与PyTorch处于这种情况相同,但PyTorch的TorchScript的选择加入性质可能比TensorFlow的“默认情况下Eager”更可口。
机器学习框架的现状
PyTorch拥有研究市场,并且正在尝试将这一成功扩展到工业领域。TensorFlow试图在不牺牲太多生产能力的情况下,在研究界中尽其所能。PyTorch对行业产生有意义的影响肯定需要很长时间-TensorFlow根深蒂固且行业发展缓慢。但是,从TensorFlow 1.0到2.0的过渡将很困难,并且为公司评估PyTorch提供了自然点。
未来将取决于谁能最好地回答以下问题。
研究人员的偏好会在多大程度上影响行业?当前的博士学位开始毕业时,他们将带来PyTorch。这种偏好是否足够强大,以至于公司会出于招聘目的选择PyTorch?毕业生会创办基于PyTorch的创业公司吗?
TensorFlow的Eager模式能否赶上PyTorch的可用性?问题跟踪器和在线社区给我的印象是TensorFlow Eager严重遭受性能/内存问题的困扰,而Autograph拥有自己的问题份额。谷歌将花费大量的工程精力,但是TensorFlow受到历史包bag的困扰。
PyTorch可以多快达到生产状态?PyTorch尚有许多基本问题尚未解决-没有良好的量化指标,移动性,服务性等。在这些问题解决之前,PyTorch甚至不会成为许多公司的选择。PyTorch能否为公司提供足够引人入胜的故事来做出改变?注意:在本文发布之日,PyTorch宣布支持量化和移动技术。两者都仍处于试验阶段,但代表了PyTorch在这方面的重大进展。
Google在行业中的孤立会伤害到它吗?Google推动TensorFlow的主要原因之一是帮助其迅速发展的云服务。由于Google试图拥有整个ML垂直市场,这激励了与Google竞争的公司(微软,亚马逊,Nvidia)竞争,以支持唯一的替代机器学习框架。
下一步是什么?
多少机器学习框架会影响机器学习研究,这也许是值得赞赏的。它们不仅支持机器学习研究,还支持并限制研究人员能够轻松探索的想法。仅仅因为没有简单的方法可以在框架中表达它们而粉碎了多少个新生的想法?PyTorch可能已经达到了本地研究的最低要求,但是值得研究其他框架提供的内容以及它们可能带来的研究机会。
高阶微分:
PyTorch和Tensorflow的核心是自动分化框架。也就是说,它们允许人们采用某些函数的导数。但是,有许多方法可以实现自动分化,而大多数现代ML框架选择的特定实现称为“反向模式自动分化”,通常称为“反向传播”。事实证明,此实现对于采用神经网络的派生极为有效。
但是,计算高阶导数(Hessian / Hessian矢量乘积)的事情发生了变化。有效地计算这些值需要所谓的“前向模式自动分化”。如果没有此功能,则计算黑森州矢量积的速度可能会慢几个数量级。
输入Jax。Jax由制造原始Autograd的同一个人制造,并具有正向和反向模式自动分化功能。这使得高阶导数的计算速度比PyTorch / TensorFlow所能提供的快。
但是,Jax不仅提供高阶导数。Jax开发人员将Jax视为组成任意功能转换的框架,包括vmap(用于自动批处理)或pmap(用于自动并行化)。
最初的autograd拥有忠实的关注者(尽管没有GPU支持,ICML上有11篇论文使用了它),而且Jax可能很快就会建立一个类似的忠实社区,将其用于各种n阶导数。
代码生成
当您运行PyTorch / TensorFlow模型时,大多数工作实际上不是在框架本身中完成的,而是由第三方内核完成的。这些内核通常由硬件供应商提供,并且由高级框架可以利用的操作员库组成。这些就是MKLDNN(用于CPU)或cuDNN(用于Nvidia GPU)之类的东西。更高级别的框架将其计算图分成多个块,然后可以调用这些计算库。这些库代表数千个工作小时,并且经常针对体系结构和应用程序进行优化以产生最佳性能。
但是,最近对非标准硬件,稀疏/量化张量和新操作员的兴趣暴露了依赖这些库的主要缺陷:它们不灵活。如果您想在研究中使用像胶囊网络这样怎么办?如果要在ML框架没有很好支持的新硬件加速器上运行模型怎么办?现有的解决方案经常达不到要求。正如本文最近指出的那样,在GPU上使用Capsule Networks的现有实现比最佳实现要慢2个数量级。
每个新的硬件体系结构,张量类别或运算符,都会大大增加此问题的难度。有许多工具可以解决不同方面的问题(卤化物,TVM,PlaidML,张量理解,XLA,Taco等),但是正确的方法仍然不清楚。
如果没有更多的工作来解决这个问题,我们就有将ML研究过度适合于我们拥有的工具的风险。
ML框架的未来
这些是TensorFlow和PyTorch未来的激动人心的时刻。他们的设计已经趋于一致,以至于任何一个框架都不会凭借其设计获得决定性的胜利。每个国家都有自己的领土-一方拥有研究,另一方拥有产业。
就个人而言,在PyTorch和TensorFlow之间,我会给PyTorch带来优势。机器学习仍然是研究驱动的领域。工业界不能忽视研究成果,只要PyTorch主导研究,这将迫使公司做出选择。
但是,不仅仅是快速发展的框架。机器学习研究本身也处于不断变化的状态。框架不仅会发生变化,而且5年内使用的模型/硬件/范例可能与我们今天使用的模型/外观大不相同。随着另一种计算模型的普及,也许PyTorch和TensorFlow之间的战斗将变得无关紧要。
在所有这些利益冲突以及机器学习带来的所有金钱之中,最好退后一步。我们大多数人都不是为了赚钱或为了协助公司的战略计划而开发机器学习软件。我们从事机器学习的原因是,我们关心-关注推进机器学习的研究,使AI民主化,或者只是关注构建有趣的东西。无论您是喜欢TensorFlow还是PyTorch,我们都试图使机器学习软件达到最佳状态。
原文链接:
https://thegradient.pub/state-of-ml-frameworks-2019-pytorch-dominates-research-tensorflow-dominates-industry/
【Tensorflow】Keras作者François Chollet《Python深度学习》中文版便捷下载
后台回复“DLPY” 就可以获取新书《Deep Learning with Python》下载链接~

【Pytorch】请关注专知公众号(点击上方蓝色专知关注)
后台回复“DLPY” 就可以获取新书《Deep Learning with PyTorch》下载链接~