AI当自强:独家揭秘旷视自研人工智能算法平台Brain++
机器之心原创
作者:一鸣
随着深度学习逐渐从实验室走向工业应用,各大企业都在探索构建算法架构、实现模型的工具和平台。和使用 TensorFlow 或 PyTorch 等开源框架的公司不同,旷视走向了一条自主研制的道路,建立了从算法研发到部署应用的全流程、一站式人工智能算法平台 Brain++。在 Brain++投入使用 5 年之际,机器之心在此为读者揭开 Brain++的神秘面纱。

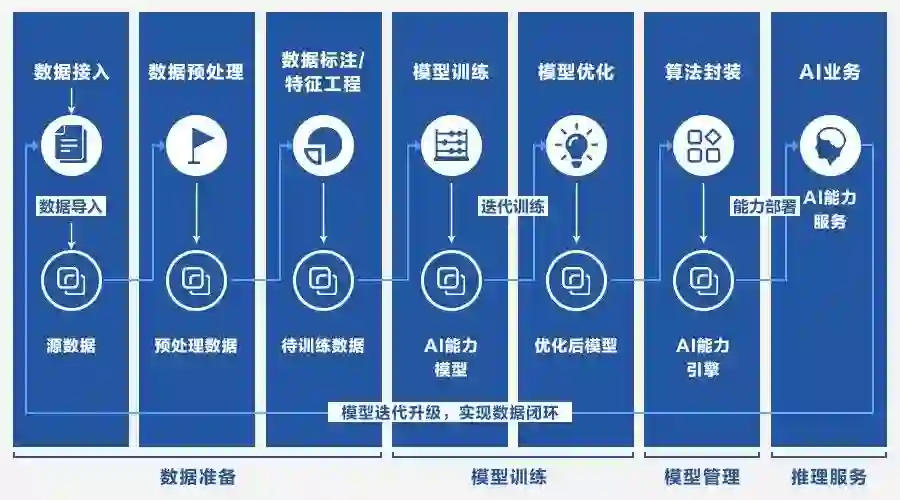
Brain++涵盖了深度学习算法开发的整个流程。

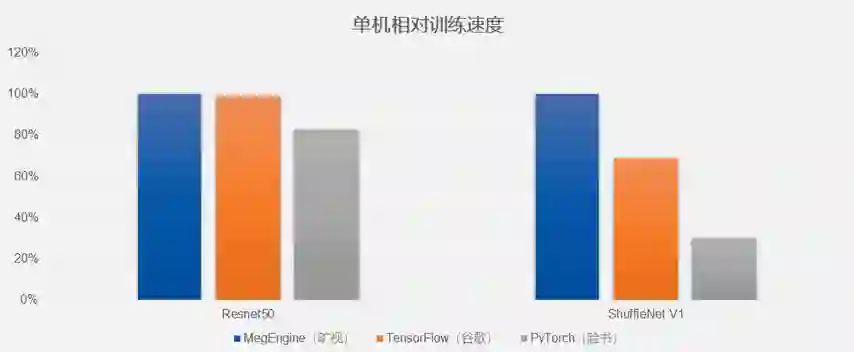
运算速度快:MegEngine 动态、静态结合的内存优化机制,因此速度比 TensorFlow 更快;
内存占用少:通过分析整个执行方案的内存使用情况,MegEngine 充分优化内存,特别是亚线性内存优化,可以支持复杂的网络结构,自动利用部分冗余计算缩减内存占用,可达两个数量级,从而支持更大规模的模型训练;
易用性好:MegEngine 封装了平台细节,易于新人用户快速上手;
支持多种硬件平台和异构计算:MegEngine 支持通用 CPU、GPU、FPGA 以及其他移动设备端硬件,可多卡多机进行训练;
训练部署一体化:整个框架既可用于训练又同时支持推理,实现模型一次训练,多设备部署,避免复杂的转换过程造成的性能下降和精度损失。
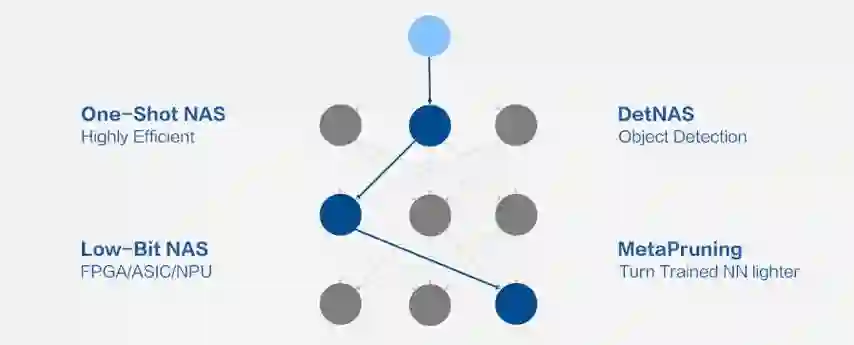
计算代价小。传统的 AutoML 技术常常需要多次训练模型甚至会遍历部分模型空间,计算代价巨大。旷视的 AutoML 技术只需训练一次即可得到整个模型空间的刻画,大大减小了计算代价,只是平常训练代价的 1-3 倍。
应用范围广。旷视 AutoML 技术提供了一套完整的解决方案,覆盖了大部分业务,包括活体检测、人脸识别、物体检测、语义分割等。
部署方便。旷视 AutoML 技术涵盖了数据处理、模型训练、模型压缩、模型量化等流程,自动处理从数据到落地。
精度高。旷视 AutoML 技术在诸多视觉任务上,超过人类手工设计,达到了业界最优。
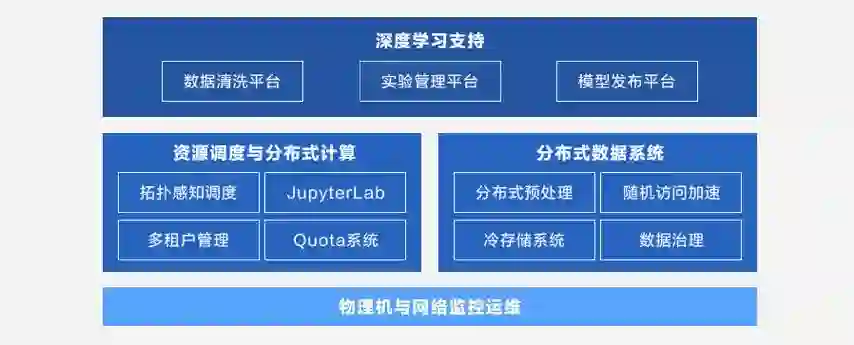
性能强大:MegCompute 有丰富的 GPU 计算资源,同时也支持各类硬件,可灵活高效地分配计算任务。
全流程覆盖:MegCompute 支持模型构建的全部流程环节,让研究人员能够实现一站式的业务应用服务,满足工业级的 AI 能力研发测试、部署上线和业务生产方面的工作。
弹性部署:MegCompute 采用了 Docker 容器技术,可以让用户弹性化地构建部署训练环境,在不需要使用的时候直接销毁,使得资源可以及时释放给其他用户,具有非常弹性的特点。
用户友好:用户使用过程中,通过可视化界面进行环境搭建和训练设计方面的工作,也可以通过可视化的方式查看模型测试的结果,不需要关注太多的底层技术细节,使用非常方便。
支持多种深度学习框架:除了和 MegEngine 自研深度学习框架紧密结合外,MegCompute 也支持使用 TensorFlow 和 PyTorch。