清华&斯坦福提出深度梯度压缩DGC,大幅降低分布式训练网络带宽需求

作者简介
林宇鋆是清华大学电子工程系 NICS 实验室 2014 级本科生,于 2017 年暑假在斯坦福参加暑研期间同韩松博士一起出色完成了 DGC 的工作,收到 MIT, Stanford, CMU, UMich 等美国名校的博士项目录取,并将于 2018 年秋加入 MIT HAN Lab 攻读博士学位。
韩松博士于 2017 年毕业于斯坦福大学,师从 GPU 之父 Bill Dally 教授。他的研究涉足深度学习和计算机体系结构,他提出的 Deep Compression 模型压缩技术曾获得 ICLR 2016 最佳论文,ESE 稀疏神经网络推理引擎获得 FPGA 2017 最佳论文,引领了世界深度学习加速研究,对业界影响深远,于博士期间联合创立了深鉴科技。基于对一系列重要科研成果的继续深入探索,韩松博士将于 2018 年任职 MIT 助理教授,创立 HAN Lab。
大规模分布式训练可提升训练大型深度模型的训练速度。同步随机梯度下降(SGD)已被普遍用于分布式训练。通过增加训练节点数量,利用数据并行化的优势,我们能够极大地减少在相同规模的训练数据上做前向-后向传播的计算时间。然而,分布式训练中梯度交换的成本过高,尤其是在计算-通信比率较低的循环神经网络(RNN)等情况下;由并行训练带来的计算时间上的节省,可能将不足以补偿通信时间上代价的增长。因此,网络带宽成为了分布式训练规模化的最大瓶颈。特别是在移动设备上做分布式训练时,带宽问题变得更加显著,例如联合学习(federated learning)。因为具备更好的隐私性、个性化等特点,在移动设备上训练神经网络模型变得更加诱人,但其面临的重大挑战包括移动设备网络中的更低的带宽、不连贯的网络连接、价格昂贵移动数据流量等问题。
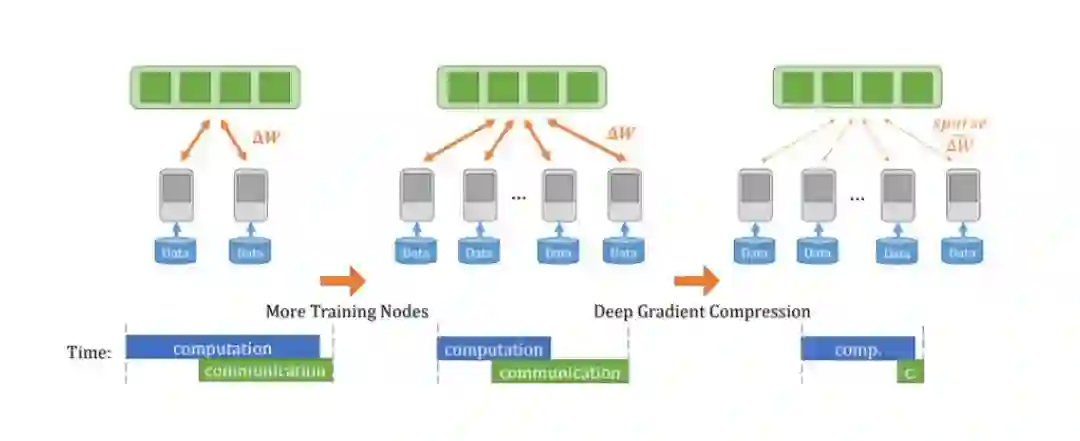
图 1:DGC 可以减少梯度交换时间,提高多节点训练的可扩展性,并对分布式训练进行加速。
深度梯度压缩(Deep Gradient Compression,DGC)通过压缩梯度解决了通信带宽问题,如图 1 所示。为了确保没有损失准确率,DGC 在梯度稀疏化之上应用了动量修正(momentum correction)和局域梯度修剪(local gradient clipping)方法。DGC 还应用了动量因子掩蔽(momentum factor masking)和预热训练(warm-up training)以克服通信量减少带来的陈化问题。
研究者通过实验在多种任务、模型和数据集上验证了 DGC 的有效性:
CNN 网络:图像分类任务,CIFAR-10 和 ImageNet 数据集;
RNN 网络:语言建模任务,Penn Treebank 数据集;
语音识别任务,Librispeech Corpus。
这些实验证明了我们可以对梯度进行 600 倍的压缩而不损失准确率,相比于之前的研究(Aji & Heafield, 2017),DGC 的性能提升了一个量级。
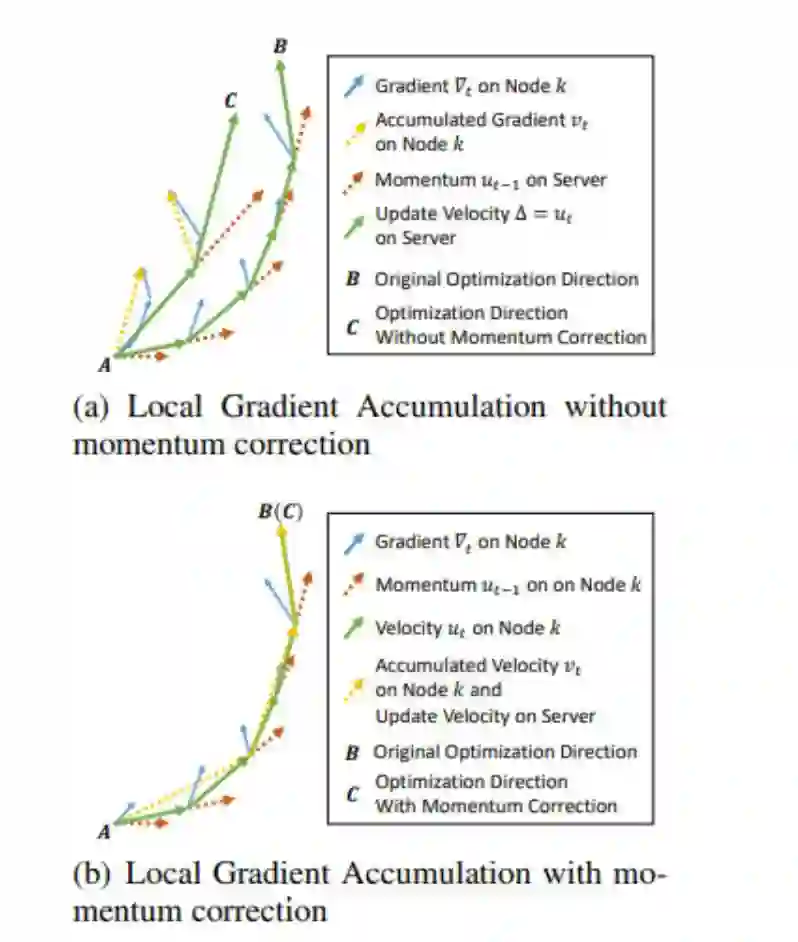
图 2:动量修正图示:(a)没有使用动量修正的局域梯度累积(Local Gradient Accumulation);(b)使用动量修正的局域梯度修正。
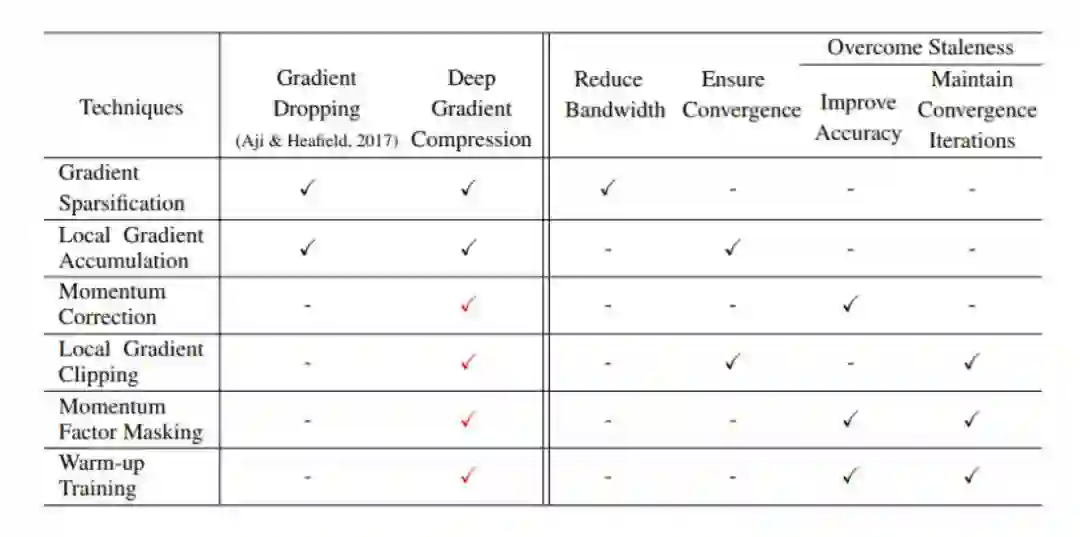
表 1:深度梯度压缩(DGC)中应用到的技术。
表 2:在 CIFAR-10 数据集上训练的 ResNet-110 的准确率结果,图中展示了基线模型、Gradient Dropping 方法和 DGC 方法优化后的结果对比。
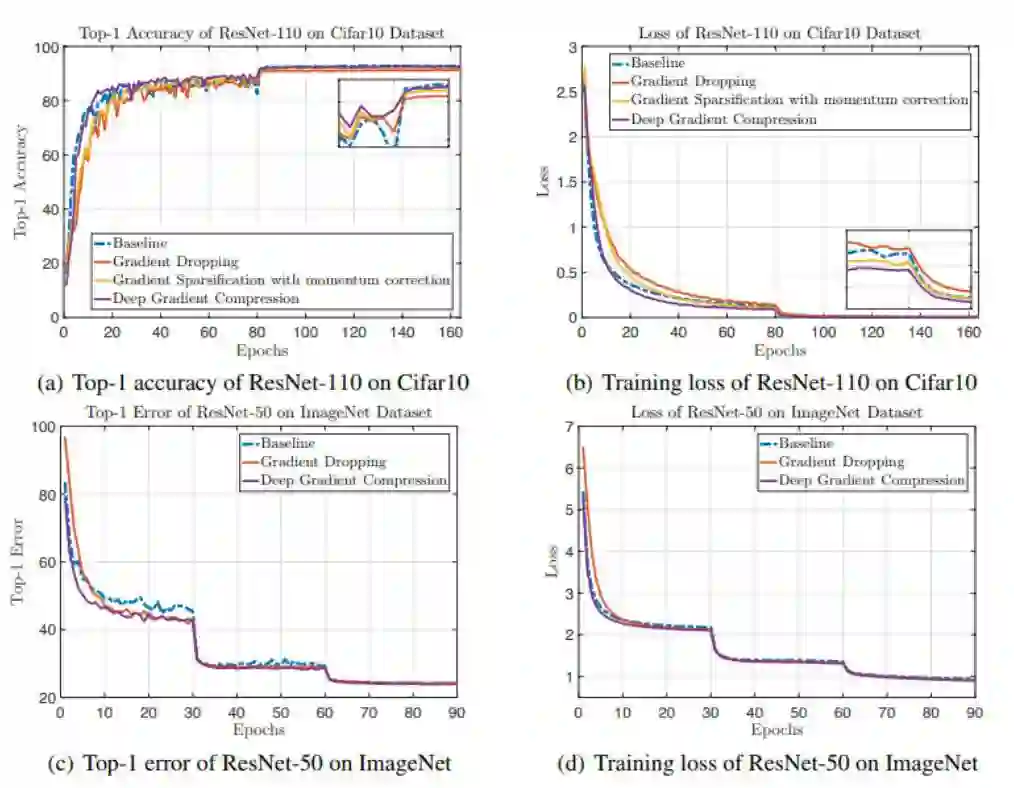
图 3:ResNet 在图像分类任务上的学习曲线(梯度稀疏度为 99.9%)。(a)ResNet-110 在 CIFAR-10 数据集上的 top-1 准确率;(b)ResNet-110 在 CIFAR-10 数据集上的训练损失;(c)ResNet-50 在 ImageNet 数据集上的 top-1 准确率;(d)ResNet-50 在 ImageNet 数据集上的训练损失。
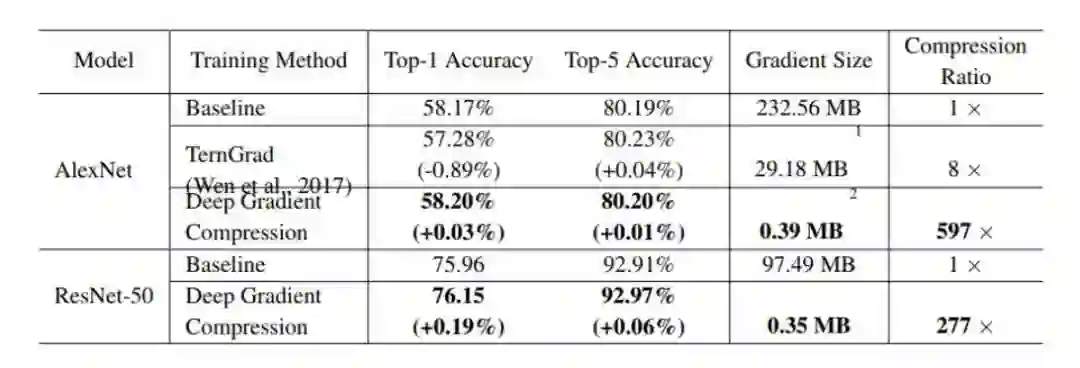
表 3:AlexNet 和 ResNet-50 模型的多种优化方法在 ImageNet 数据集上得到的梯度压缩率对比。
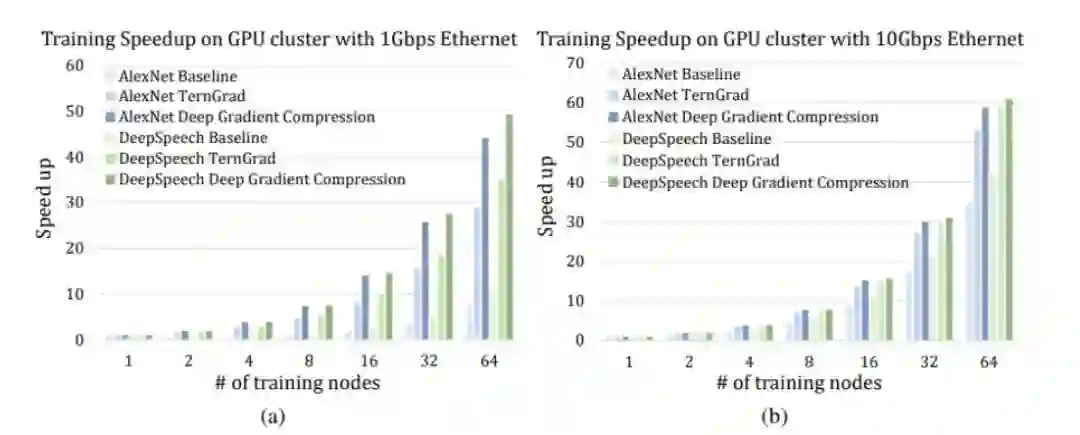
图 6:DGC 提升了分布式训练的加速性能和可扩展性。每一个训练节点有 4 个英伟达 Titan XP GPU 以及一个 PCI 交换机。
5. 系统分析和表现部署
DGC 需要对梯度进行 top-k 选择。给定目标稀疏系数为 99.9%,我们要从百万权重中选择最大的 0.1%。其复杂度通常为 O(n),n 是梯度单元(gradient element)的数量。我们提出使用采样法来减少 top-k 的选择时耗。我们只采样梯度的 0.1% 到 1%,然后在采样上的进行 top-k 选择来估算整个梯度矩阵的阈值。
如果被选出梯度的数量(远超期望地)超出了阈值,我们就可以从已选择的梯度中重新使用 top-k 算法计算精确的阈值。分层地计算阈值可以显著地减少 top-k 选择时间。在实践中,相比网络的通信时间,总的额外计算时间是可忽略的,通常为几百毫秒到数秒(取决于网络带宽)。
我们使用了 Wen 等人(2017)提出的性能模型来执行可扩展性分析,将单个训练节点上的轻量剖析和分析通信建模技术结合了起来。通过全归约(all-reduce)通信模型(Rabenseifner, 2004; Bruck et al., 1997),在最坏的情况下,稀疏数据的密度在每个聚合步骤翻一番。然而,即使考虑了这种效应,DGC 仍然能显著地减少网络通信时间,如图 6 中所示。图 6 展示了多节点训练和单节点训练的加速性能对比。传统的训练方法在 1Gbps(图 6(a))的以太网上的加速性能相比在 10Gbps(图 6(b))上的加速性能要差很多。尽管如此,DGC 可以将 1Gbps 以太网上的训练过程进行优化,并得到和 10Gbps 以太网训练相当的结果。例如,当将 AlexNet 在 64 个节点上训练时,传统的训练方法在 10Gbps 以太网上仅能达到约 30 倍的加速(Apache, 2016),而应用 DGC 时,仅仅在 1Gbps 以太网上训练就能获得 40 倍的加速。对比图 6 中的(a)和(b),当通信-计算比率更高,以及网络带宽更低时,DGC 的优势更加明显。
论文:Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training

论文地址:https://arxiv.org/abs/1712.01887
大规模的分布式训练需要为梯度交换提供很高的通信带宽,并依赖昂贵的高带宽网络基础设施,因而限制了多节点训练的可扩展性。当在移动设备上进行分布式训练时(联合式学习),情况将变得更加糟糕,导致更高的延迟、更低的吞吐量以及断续的连接状态。在本文中,我们发现在分布式 SGD 中 99.9% 的梯度交换都是冗余的,因此我们提出了深度梯度压缩方法(Deep Gradient Compression,DGC)以大幅压缩通信带宽。为了在压缩过程中保持准确率,DGC 使用了四个方法:动量修正(momentum correction)、局域梯度修剪(local gradient clipping)、动量因子掩蔽(momentum factor masking)以及预热训练(warm-up training)。我们将 DGC 应用到图像分类、语音识别和语言建模中,评估数据集包括 Cifar10、ImageNet、Penn Treebank 和 Librispeech Corpus。在这些场景中,DGC 在不降低准确率的情况下达到了 270 倍到 600 倍的梯度压缩率,将 ResNet-50 的梯度规模从 97MB 压缩到了 0.35MB,将 DeepSpeech 的梯度规模从 488MB 压缩到了 0.74MB。DGC 可以帮助我们在通用的 1Gbps 以太网上执行大规模的分布式训练,并能促进移动设备上的分布式训练开发。

媒体合作请联系:
邮箱:contact@dataunion.org

