HyperparameterHunter 3.0:一文教你学会自动化特征工程
选自TowardsDataScience
本文介绍了一个 GitHub 开源项目——HyperparameterHunter 3.0。开发者可以使用这一工具自动化地进行特征工程。

使特征工程的语法清晰化、可定制的函数列表。
构建特征工程工作流的一致性框架,流程自动记录。
特征工程步骤优化,包括对过去实验的检测,以进行快速启动优化。
别再跟踪特征工程步骤的列表,以及它们与其他超参数一起工作的方式
手动特征创建
缩放/归一化/标准化
重采样 (参考我们的 imblearn 的例子)
目标数据转换
特征选择/消除
编码(one-hot,标签等等)
填补
二值化/合并/离散化

你几乎总是需要预处理你的数据。这是一个必须的步骤。
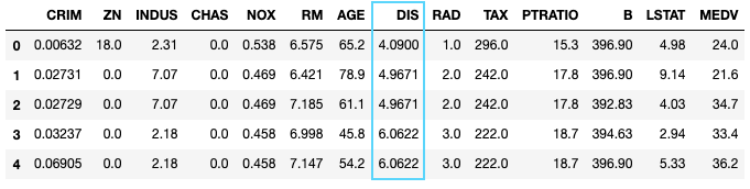
基线模型

但是,Hunter 中定义特征工程步骤的语法是如此的顺畅和合乎逻辑!我从来没想过 HyperparameterHunter 会以我早在使用的格式期待它们!真是太疯狂了!但是那又如何呢??? —你(也许你会这么说)



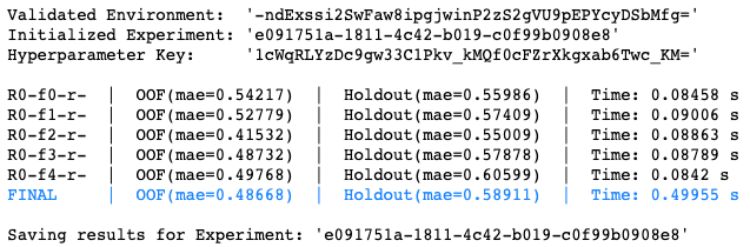
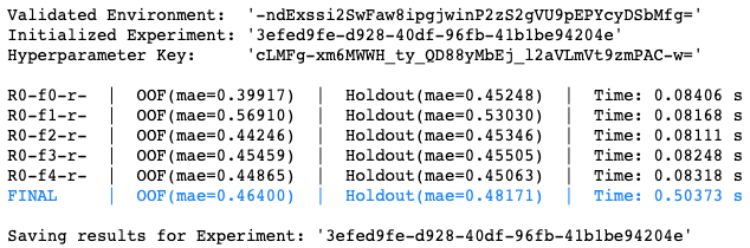



登录查看更多
相关内容
Arxiv
5+阅读 · 2019年1月24日
Arxiv
4+阅读 · 2018年6月20日



相关VIP内容
相关资讯
相关论文
Arxiv
5+阅读 · 2019年1月24日
Arxiv
4+阅读 · 2018年6月20日