独家 | 用Python Featuretools库实现自动化特征工程(附链接)

作者:Prateek Joshi
翻译:张玲
校对:李润嘉
本文约4000字,建议阅读10分钟。
本文简要介绍特征工程的基本组成部分,并用直观的示例理解它们,最后给出使用Python Featuretools库实现自动化特征工程的操作过程。
简介
在机器学习黑客马拉松和竞赛中,特征工程的质量通常是进入排行榜10强和无缘50强的重要区别,因此,所有参赛过的人都可以证明特征工程的重要性。
自从我意识到特征工程具有巨大的潜力以来,我一直是它的大力倡导者。但当手动完成时,这可能是一个缓慢而艰难的过程。我必须绞尽脑汁来思考有哪些特征存在,并从不同的角度分析它们的可用性。现在,整个FE(Feature Engineering,特征工程)流程都可以实现自动化,我将在本文中向您展示。
我们将使用一个名为Featuretools的Python特征工程库,来实现这一流程。但是在深入研究之前,我们首先了解下FE的基本组成部分,并用直观的示例理解它们,最后利用BigMart Sales数据集来深入了解自动化特征工程这一精彩世界。
目录
1. 什么是特征?
2. 什么是特征工程?
3. 为什么需要特征工程?
4. 自动化特征工程
5. Featuretools简介
6. Featuretools实践
7. Featuretools的可解释性
1. 什么是特征
在机器学习的背景下,特征是用来解释现象发生的单个特性或一组特性。 当这些特性转换为某种可度量的形式时,它们被称为特征。
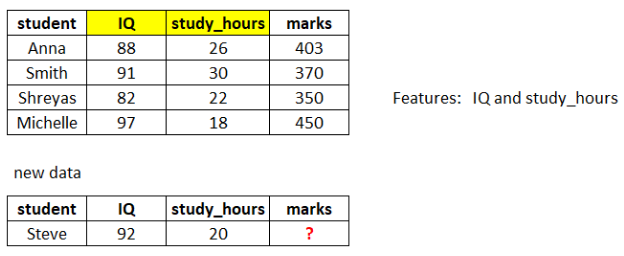
举个例子,假设你有一个学生列表,这个列表里包含每个学生的姓名、学习小时数、IQ和之前考试的总分数。现在,有一个新学生,你知道他/她的学习小时数和IQ,但他/她的考试分数缺失,你需要估算他/她可能获得的考试分数。
在这里,你需要用IQ和study_hours构建一个估算分数缺失值的预测模型。所以,IQ和study_hours就成了这个模型的特征。
2. 什么是特征工程?
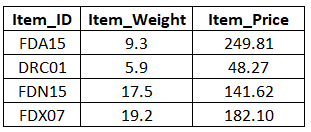
特征工程可以简单定义为从数据集现有特征中构造新特征的过程。假设我们有一个样本数据,里面含有一些商品的细节信息,例如重量和价格。
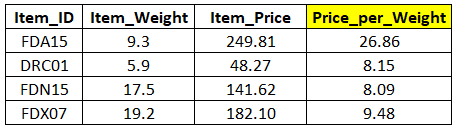
现在,我们可以用Item_Weight和Item_Price来构造名为Price_per_Weight的新特征。它仅是用商品的价格除以商品的重量而已。这样的过程称为特征工程。
这只是一个从现有特征中构造一个新特征的简单示例,但实际上,当我们有相当多的特征时,特征工程可变得非常复杂和繁琐。
再看另一个例子,在常用的Titanic数据集中,存在一个乘客名字的特征,下面是这个数据集中的一些名字:
Montvila, Rev. Juozas
Graham, Miss. Margaret Edith
Johnston, Miss. Catherine Helen “Carrie”
Behr, Mr. Karl Howell
Dooley, Mr. Patrick
这些名字实际上可以分解成另外几个有意义的特征。例如,将相似的称谓提取出来,合并成一个类别。让我们来看一看乘客姓名中这些称谓的不同个数。
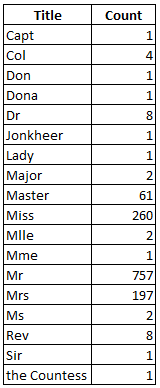
从上图可以看出,“Dona”、“Lady”、“the Countess”、“Capt”、“Col”、 “Don”、“Dr”、“Major”、“Rev”、“Sir”和“Jonkheer”这些称谓是十分少见的,可以将它们放在一个标签下,即rare_title。除了这些,称谓“Mlle”和“Ms”可归到“Miss”下,而“Mme”可以用“Mrs”来代替。
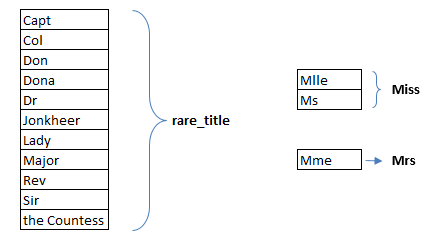
因此,如下图所示,这个新称谓的特征只有5个不同的值:

这就是我们借助特征工程从特征中提取有用信息的过程,即使是像乘客名字这样乍一看毫无意义的特征。
3. 为什么需要特征工程?
预测模型的性能在很大程度上取决于用于训练该模型的数据集特征的质量。如果你能够构造出可提供更多有关模型目标变量的信息的新特征,那么模型的性能将会提升。所以,当数据集中没有足够多的高质量特征时,我们必须依靠特征工程。
在Kaggle上最受欢迎的竞赛之一,自行车租赁需求预测中,参赛者需要根据与天气、时间和其他数据相关的历史使用模式来预测华盛顿特区的租赁需求。
正如本文所述,智能化特征工程有助于参赛者获得排行榜前5%的排名。一些构造的特征如下:
Hour Bins:借助于决策树,通过切分hour特征构造的新特征
Temp Bins:相似地,是temperature变量的切分特征
Years Bins:通过8等分2年时间构造的新特征
Day Type:Days分成“工作日”、“周末”和“节假日”
构造这样的特征并非易事,因为它需要大量的头脑风暴和广泛的数据探索。特征
工程不能通过读书和看视频来学习,因此,不是所有的人都擅长它。这就是特征工程也被称为艺术的原因。如果擅长它,那么你在竞赛中就占据优势。就像罗杰·费德勒(Roger Federer),在网球得分上,他就是特征工程的大师。

4. 自动化特征工程

分析上面两张图片,左图显示了20世纪初一群人正在组装汽车,右图则显示了当今一群机器人在做同样的工作。自动化任何流程都可以使其变得更加高效和经济。同样,特征工程也是如此。而且,在机器学习中,特征工程已经实现自动化。
构建机器学习模型通常是一个艰苦而乏味的过程,涉及许多步骤。因此,如果我们能够自动化执行一定比例的特征工程任务,那么数据科学家或领域专家就可以专注于模型的其他方面。听起来简直太棒了,但难以置信,对吧?
既然我们已经明白自动化特征工程的发展亟需帮助,那么下一个要问的问题就是,如何实现?嗯,我们有一个很好的工具可以用来解决这个问题,它叫Featuretools。
5. Featuretools简介

Featuretools是一个开源库,用来实现自动化特征工程。它是一个很好的工具,旨在加快特征生成的过程,从而让大家有更多的时间专注于构建机器学习模型的其他方面。换句话说,它使你的数据处于“等待机器学习”的状态。
在使用Featuretools之前,我们应该了解程序包中的三个主要组件:
实体(Entities)
深度特征综合(Deep Feature Synthesis ,DFS)
特征基元(Feature primitives)
一个Entity可以视作是一个Pandas的数据框的表示,多个实体的集合称为Entityset。
深度特征综合(DFS)与深度学习无关,不用担心。实际上,DFS是一种特征工程方法,是Featuretools的主干。它支持从单个或者多个数据框中构造新特征。
DFS通过将特征基元应用于Entityset的实体关系来构造新特征。这些特征基元是手动生成特征时常用的方法。例如,基元“mean”将在聚合级别上找到变量的平均值。
了解、熟悉Featuretools的最佳方法就是将其应用于数据集。因此,在下一节中,我们将使用BigMart Sales实践问题中的数据集来巩固我们的概念。
6. Featuretools实践
BigMart Sales面临的挑战是构建一个预测模型来估算特定门店中每种商品的销售额,这将有助于BigMart的决策者找出每一个产品或门店的重要属性,这对提高整体销售起着关键性作用。请注意,在给定的数据集中,有跨10个门店的1559种商品。
下表给出了数据提供的特征:
变量 |
描述 |
Item_Identifier |
商品编号 |
Item_Weight |
商品重量 |
Item_Fat_Content |
是否是低脂商品 |
Item_Visibility |
该商品展示区域占门店中所有商品展示区域的比例 |
Item_Type |
商品所属分类 |
Item_MRP |
商品最高售价 |
Outlet_Identifier |
门店编号 |
Outlet_Establishment_Year |
门店建立年份 |
Outlet_Size |
门店占地面积 |
Outlet_Location_Type |
门店所在城市类型 |
Outlet_Type |
门店类型(杂货店或超市) |
Item_Outlet_Sales |
门店商品销售额 |
你可以从这里下载数据。
6.1 安装
Featuretools适用于Python 2.7,3.5和3.6,可以使用pip轻松安装Featuretools。

6.2 下载需要的库和数据

6.3 数据准备
首先,我们将Item_Outlet_Sales存储在变量sales中,id特征存储在test_Item_Identifier和test_Outlet_Identifier中。

接着,我们将训练集和测试集组合起来,避免执行两次相同步骤的麻烦。

检查一下数据集中的缺失值。


变量Item_Weight 和 Outlet_size中有非常多的缺失值,我们快速处理一下:

6.4 数据预处理
我不会做大量的预处理操作,因为本文的目的是让你开始使用Featuretools。
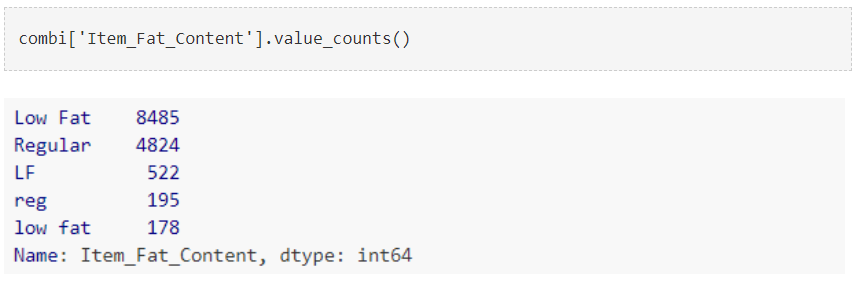
似乎Item_Fat_Content只包含两个类别,即“低脂肪”和“常规”,其余值被视为是多余的。 所以,让我们把它转换成二元变量。

6.5 使用Featuretools实现特征工程
现在,我们可以开始使用Featuretools来实现自动化特征工程了! 数据集中必须具有唯一标识符的特征(我们的数据集现在没有任何这样的特征)。 因此,我们将为组合数据集创建一个唯一ID。 如果您注意到,数据中有两个ID -一个用于商品,另一个用于门店。 因此,简单地连接两者就可以为我们提供唯一的ID。

请注意,由于不再需要特征Item_Identifier,我删除了这个特征。但是,保留了特征Outlet_Identifier,因为我打算稍后使用它。
在继续之前,我们将创建一个特征EntitySet,它是一种包含多个数据框及其之间关系的结构。那么,让我们创建一个EntitySet并将数据框组合添加进去。

数据中包含两个级别的信息,即商品级别和门店级别的信息。而且,Featuretools提供了将数据集拆分为多个表的功能。所以,我们根据门店ID Outlet_Identifier从BigMart表创建了一个新表'outlet'。
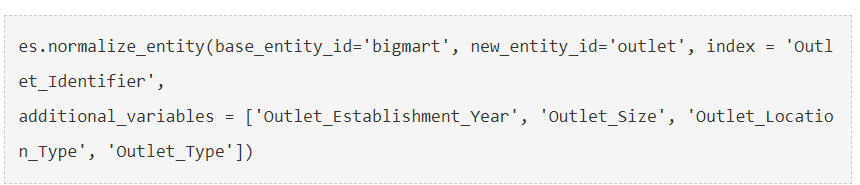
让我们检查一下EntitySet的摘要。
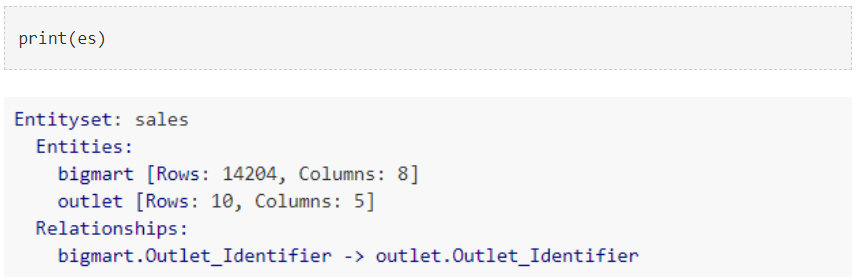
如上所示,它包含两个实体,bigmart和outlet。两个表之间也形成了一种由Outlet_Identifier连接的关系。这种关系将在新特征的生成中发挥关键作用。
现在我们将使用深度特征综合(Deep Feature Synthesis)自动创建新特征。回想一下,DFS使用Feature Primitives和EntitySet中存在的多个表来构造新特征。
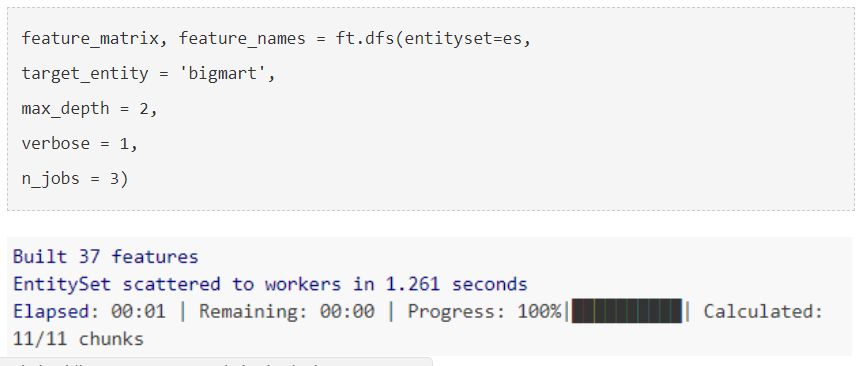
target_entity是目标实体的ID,目标实体指的是我们希望为其构造新特征的实体(在这种情况下,它是实体'bigmart')。参数max_depth控制由叠加特征基元方式生成的特征的复杂性。参数n_jobs则是通过使用多个核的方式来帮助进行并行特征计算。
这就是你用Featuretools所做的一切,它自己构造了许多新特征。
让我们来看看这些新构造的特征:


DFS在如此短的时间内构造了29个新特征。这令人震惊,因为手动操作需要更长的时间。 如果你的数据集包含多个相互关联的表,那么Featuretools仍然有效。
在这种情况下,您不必对表进行规范化,因为多个表已经可用。
让我们看看feature_matrix的前几行。
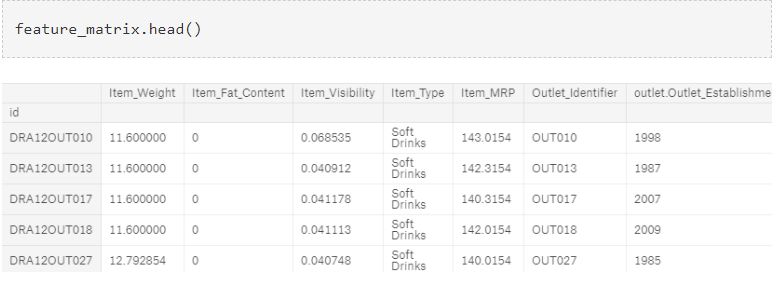
这个数据框存在一个问题,它并没有进行恰当的排序。我们将根据combi数据框中的id变量对其进行排序。

现在,数据框feature_matrix的排序正确。
6.6 构建模型
现在是检测这些生成特征的有效性的时候了!我们将使用它们来构建模型,预测Item_Outlet_Sales。由于最终的数据(feature_matrix)里具有许多类别特征,我决定使用CatBoost算法。它可以直接使用类别特征,并且本质上是可扩展的。
你可以参考这篇文章来阅读有关CatBoost的更多信息。

CatBoost要求所有类别变量都采用字符串格式。因此,我们首先将数据中的类别变量转换为字符串:

然后重新把feature_matrix拆回训练集和测试集。

将训练集拆成训练和验证两部分,以便在本地测试算法的性能。

最后,训练模型。采用RMSE(Root Mean Squared Error,均方根误差)作为衡量指标。


1091.244
验证数据集的RMSE得分是~1092.24。
同一模型在公共排行榜上得分为1155.12。在没有任何特征工程的情况下,验证集和公共排行榜的得分分别为~1103和~1183。 因此,Featuretools构造的特征不仅仅是随机特征,而且还非常有价值的。最重要的是,它使特征工程节省了大量时间。
7. Featuretools的可解释性
使我们的数据科学解决方案通俗易懂是演示机器学习非常重要的一个方面。Featuretools生成的特征可以很容易地解释给非技术人员听,原因是它们均基于易理解的特征基元。
例如,特征outlet.SUM(bigmart.Item_Weight)和outlet.STD(bigmart.Item_MRP)分别表示每家门店所有商品重量的总和以及商品成本的标准差。
这使得不是机器学习专家的人员同样能够在自己领域专业有所贡献。
尾记
Featuretools包真正改变了机器学习的游戏规则。虽然它在行业中的应用仍然受制,但是已经风靡于黑客马拉松和ML竞赛。它所节省的时间以及其生成特征的实用性已经真正赢得了我的青睐。
下次处理任何数据集时请尝试一下,并在评论部分告诉我这个过程是如何进行的!
原文标题:
A Hands-On Guide to Automated Feature Engineering using Featuretools in Python
原文链接:
https://www.analyticsvidhya.com/blog/2018/08/guide-automated-feature-engineering-featuretools-python/
译者简介

张玲,在岗数据分析师,计算机硕士毕业。从事数据工作,需要重塑自我的勇气,也需要终生学习的毅力。但我依旧热爱它的严谨,痴迷它的艺术。数据海洋一望无境,数据工作充满挑战。感谢数据派THU提供如此专业的平台,希望在这里能和最专业的你们共同进步!
翻译组招募信息
工作内容:将选取好的外文前沿文章准确地翻译成流畅的中文。如果你是数据科学/统计学/计算机专业的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友,数据派翻译组欢迎你们加入!
你能得到:提高对于数据科学前沿的认知,提高对外文新闻来源渠道的认知,海外的朋友可以和国内技术应用发展保持联系,数据派团队产学研的背景为志愿者带来好的发展机遇。
其他福利:和来自于名企的数据科学工作者,北大清华以及海外等名校学生共同合作、交流。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派THU ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。


点击“阅读原文”拥抱组织




