人类和机器感知比较中常见的三大陷阱,你中了几条?

深度神经网络(DNNs)已经在人工智能领域取得了极大的成功,它们以图像识别、自动化机器翻译、精确医疗和许多其他解决方案为载体,直接影响着我们的生活。
不仅如此,这些现代人工算法和人脑之间有许多相似之处:首先是两者在功能上的相似,(比如说,它们都可以解决非常复杂的任务),以及它们在内在结构上的相似性(比如它们包含许多具有层级结构的神经元)。
既然这两个系统很明显存在众多相似性,于是人们不禁提出许多问题:人类视觉和机器视觉到底有多大的相似性?我们可以通过研究机器视觉来理解人类视觉系统吗?或者从另一个角度来说:我们能从人类视觉的研究中获得一些启发来改进机器视觉的效能吗?所有这些问题都促使我们对这两个奇妙的系统进行比较研究。
虽然比较研究可以增进我们对这两个系统的理解,但实践起来并不那么容易。两个系统之间存在的众多差异可能会使研究工作变得十分复杂,同时也带来许多挑战。因此,谨慎地进行DNNs与人脑之间的比较研究就显得至关重要。

论文地址:https://arxiv.org/pdf/2004.09406.pdf
论文《The Notorious Difficulty of Comparing Human and Machine Perception》(《比较人类和机器感知中最难攻克的困难》)中,作者强调了容易得出错误结论的三个最常见的陷阱:
-
人们总是过于急切地得出结论:机器学习能够学会和人类类似的行为。这就好像我们仅仅因为动物的脸上可能有与人类类似的表情,就迅速得出结论认为动物也会和人类一样感到快乐或悲伤。 -
要得出超出测试架构和训练过程的一般性结论可能会很困难。 -
在比较人和机器时,实验条件应该是完全相同的。


我们假设卷积神经网络很难完成全局轮廓整合。就其性质而言,卷积在其大部分层中主要是处理大量的局部信息,而处理全局信息的能力相对要弱一些,这就使得在对象识别中,相对于形状,卷积更擅长处理纹理信息(相关工作可参考,Geirhos等人2018年的工作《ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness》,Brendel 和Bethge 2019年的工作《Approximating CNNs with Bag-of-local-Features models works surprisingly well on ImageNet》)。
我们用下面这组具有闭合和开放轮廓的图像训练模型:

为了测试DNN能否按有无闭合轮廓将图像分类,我们创建了自己的数据集。
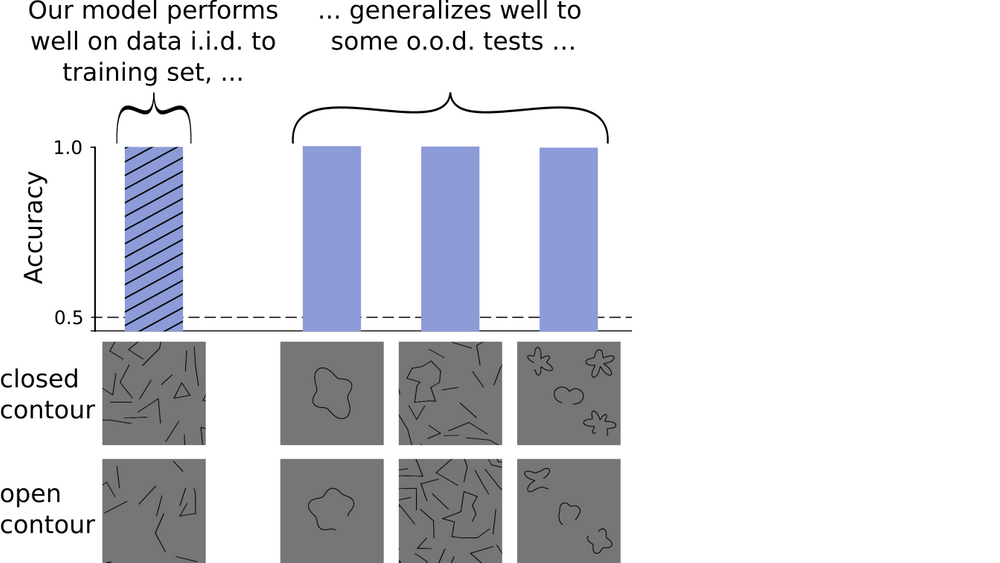
令人惊讶的是,经过训练的模型几乎完美地完成了这项任务:它可以很轻易地区分出图像中是否包含闭合轮廓。如下图所示,y轴表示准确度,即正确预测的分数,其值为1意味着模型正确地预测了所有图像,而0.5则是指模型的表现比较随机。

我们训练CNN,以让它按是否包含闭合轮廓进行图像分类。绘制的效果表明,它在和训练数据一样独立分布的测试集上表现良好。
这是否意味着DNNs可以像人类一样毫不费力地完成全局轮廓整合?如果是这样的话,即使不用新图像对模型进行任何训练,它也应该能够很好地处理不同的数据集。
遵循这一逻辑,我们继续用分布外(OOD.)图像测试模型的性能:与原始数据集不同的是,这个样本中大多数图形的轮廓包含更多的边缘,或者从原来的直线变成了曲线。
该测试应该能够揭示我们的模型是真正地学习了闭合的概念,还是只是在原始图像中提取了一些其他的统计线索(比如,封闭图像和开放图像可能包含不同数量的黑白像素等等)。
根据这些数据,我们可以得出结论,DNNs的确可以学习“闭合”这一抽象概念。然而,这还不是最后的结论。我们研究了更多不同的数据集。这一次,我们改变了线条的颜色或粗细。然而对于这些新图形,我们的模型就无法判断图像是否包含闭合轮廓了,其准确率下降到50%左右,相当于随机猜测。
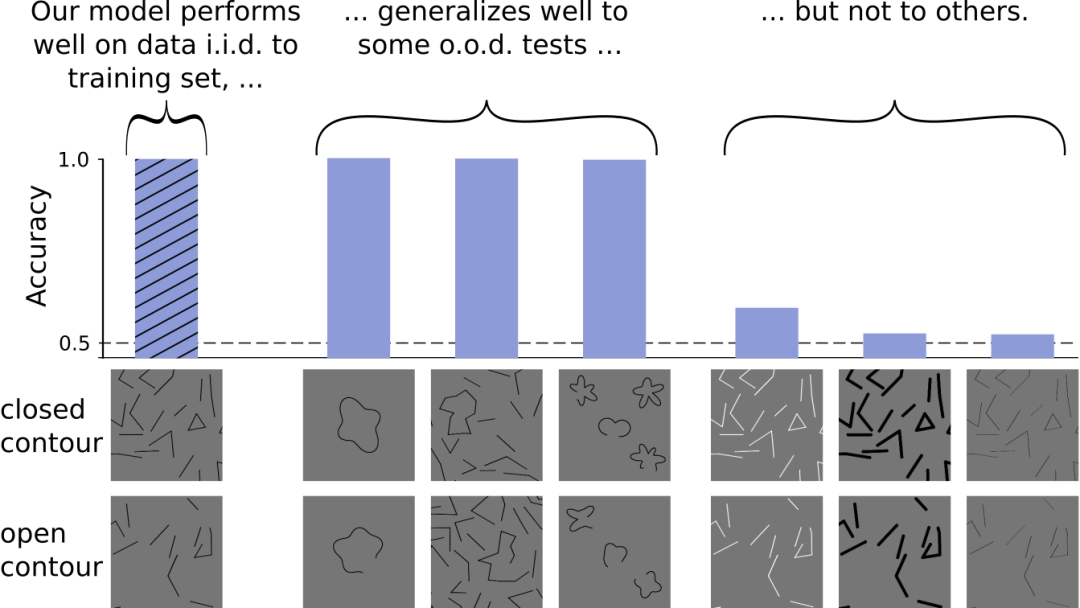
虽然我们的DNN可以泛化到一些不同的数据集,但对于其他变化则会出现问题
在这些新图形上出现的问题,表明DNN所学习的分辨图形的策略并不能处理所有不同的数据集。接下来一个自然的问题就是探究模型究竟学到了什么策略。
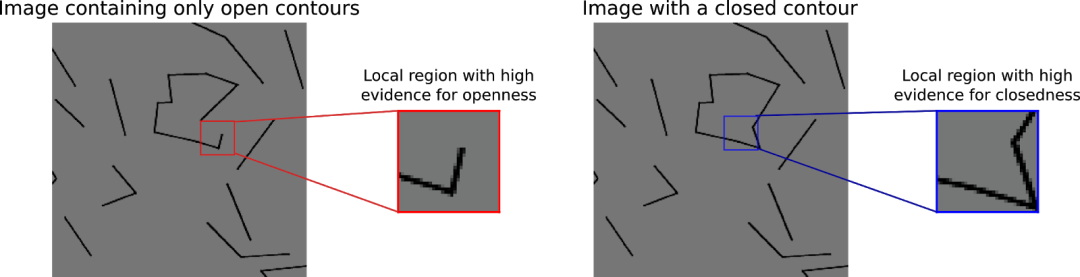
正如我们最开始所假设的那样,模型似乎需要全局信息,才能很好地完成我们的任务。为了验证这个假设,我们使用了一个只能访问局部区域的模型。
有趣的是,我们发现,即使提供给这个模型的图块小于闭合轮廓,DNN 仍然表现良好。这一发现表明,要让模型检测出我们所使用的这一组图像刺激中是否含有闭合轮廓,整体信息并不是必须的。下图展示了模型可能使用的局部特性:某些线的长度为正确的分类任务提供了线索。
陷阱2:很难得出超出测试架构和训练过程的一般性结论
下图显示了合成视觉推理测试(SVRT)的两个示例(Fleuret等人 2011年的工作《Comparing machines and humans on a visual categorization test》)。
你能解决下面的问题吗?
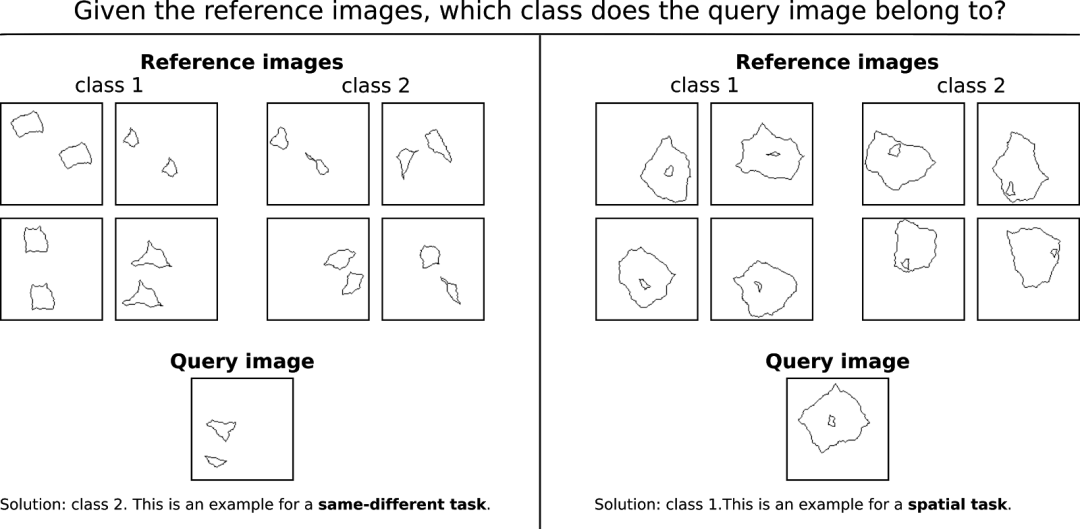
SVRT数据集的23个问题中,每一个问题都可以相应地分配到两个任务类别的其中之一。第一类称为“相同-不同任务”,需要模型判断形状是否相同。第二类称为“空间任务”,需要根据形状在空间上的排列方式做出判断,例如,根据一个形状是否位于另一个形状的中心做出判断。
人类通常非常擅长解决SVRT问题,只需要几个示例图像就可以学习潜在的规则,然后就能正确地对新图像进行分类。
曾有两个研究小组用SVRT数据集测试了深度神经网络。他们发现这两个任务类别的测试结果存在很大差异:他们的模型在空间任务上表现良好,但在“相同-不同任务”上却表现不佳。Kim等人在2018年提出,可能是人类大脑中像周期性连接这样的反馈机制,对于完成相同-不同任务来说至关重要。
这些结果已经被引证为更广泛的说法——DNNs不能很好地完成“相同-不同任务”。而下面我们将要提到的实验,将证明事实并非如此。
Kim等人使用的DNNs只包括2-6层,但通常用于对象分类任务的DNNs相比之下要大得多。我们想知道标准的DNNs是否也会出现类似的结果。为此,我们使用ResNet-50进行了同样的实验。
有趣的是,我们发现ResNet-50完成的所有任务(包括相同-不同任务)的准确率均达到90%以上,即使与Kim等人使用的100万张图像相比,我们只使用了28000张训练图像。这表明前馈神经网络确实可以在“相同-不同任务”上达到较高的精度。
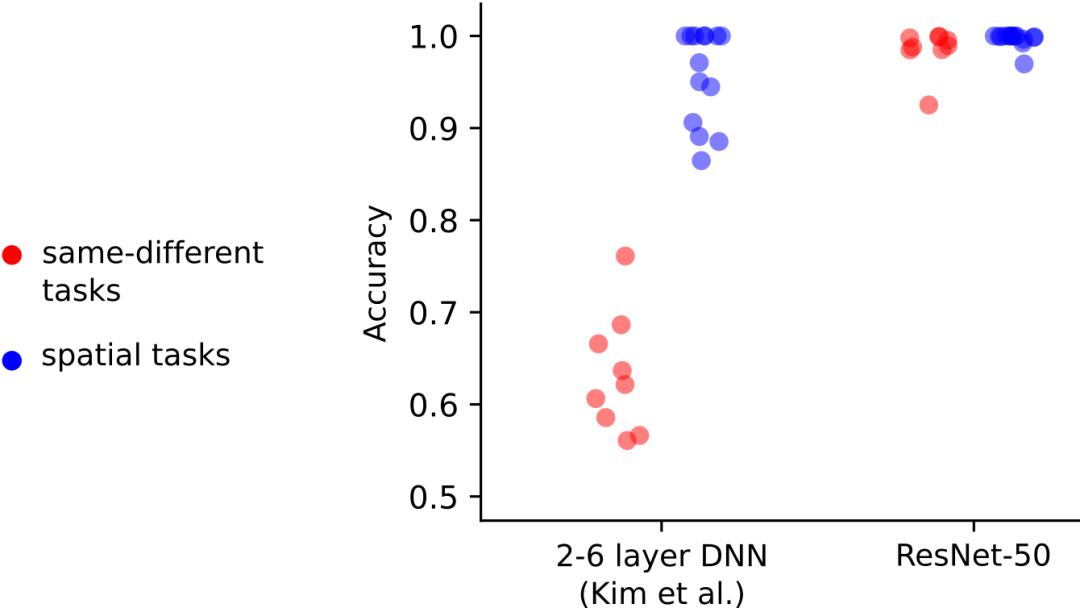
Kim等人的研究结果表明,只包含2-6层的DNNs可以很容易地解决空间任务,但是对“相同-不同任务”表现不佳。我们找到了一个模型(ResNet-50),它对两种类型的任务都能达到很高的准确率。这一发现表明,相同-不同任务对前馈模型没有固有的限制。


总结
AI 科技评论希望能够招聘 科技编辑/记者
办公地点:北京/深圳
职务:以跟踪学术热点、人物专访为主
工作内容:
1、关注学术领域热点事件,并及时跟踪报道;
2、采访人工智能领域学者或研发人员;
3、参加各种人工智能学术会议,并做会议内容报道。
要求:
1、热爱人工智能学术研究内容,擅长与学者或企业工程人员打交道;
2、有一定的理工科背景,对人工智能技术有所了解者更佳;
3、英语能力强(工作内容涉及大量英文资料);
4、学习能力强,对人工智能前沿技术有一定的了解,并能够逐渐形成自己的观点。



