李飞飞CS231n项目:这两位工程师想用神经网络帮你还原买家秀

大数据文摘出品
编译:张秋玥、胡笳、Alieen
你有没有看过某个网红小姐姐穿了一件特别棒的衣服,然后急切地想找到同款?
你不是一个人——全球零售商都们都想用这个策略获利。
每当某个明星或者时尚博主在微博或者朋友圈po出一张图,这就是一次低成本的营销机会。随着网购与照片分享变得越来越流行,利用用户原创内容(UGC, User Generated Content)的市场营销策略已成为驱动流量与零售额增长的关键。通俗点说,一张漂亮的“买家秀”可能抵得过一票销售辛苦的游说。
相比于专业内容,“买家秀”的价值在于,以图像与视频为例,效果更加具有真实性。
然而,这也存在一定风险,因为很难控制内容质量及其产生的效果。
比如说:

来自微软的软件工程师Erika Menezes与Twitter软件工程师Chaitanya Kanitkar用AI工具建立一个深度学习模型,希望将买家衣物图像与网店中相同或相似的物品相匹配。
本项目为斯坦福大学2018年春季 CS231n课程作业的一部分。
链接:
http://cs231n.stanford.edu/
感兴趣的同学也可以查看大数据文摘在网易云专栏上的汉化版课程
网址:
http://study.163.com/course/courseMain.htm?courseId=1003223001&share=2&shareId=10146755
这个“买家秀”还原问题被通称为买家到商家(consumer-to-shop)或街道到商店(street-to-shop)衣物检索问题。

本文将具体展示如何使用微软的机器学习平台Azure机器学习(AML)与Azure数据科学虚拟机(DSVM)快速推动该项目的开发。
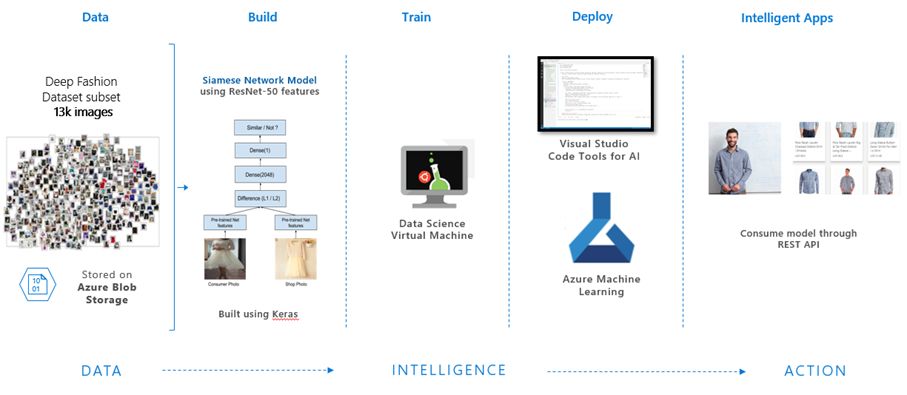
图1.建立,训练与配置跨领域视觉搜索模型的微软AI平台架构图
定义问题
在买家到商家衣物检索问题中,我们试图将用户拍的图片(即一种UGC)与同一件衣物但是由专业摄影师按既定要求拍摄的图片相匹配。用户的图片一般都是手机拍摄,质量比店家的专业商品展列图片差很多。
具体来说,对于每一张新输入的UGC图片,我们希望返回k个与该图片最为相似的商品图片,并从中得到一件最匹配的商品。我们将需要定义一个距离度量函数,来量化被搜索图片与所有商品品类图片之间的相似度,并且根据其值排序得到k个最相似图片。
数据
本文数据采用Deep Fashion数据集的一部分。该数据集包括UGC图片及多种衣物类别的商品品类图片。我们使用四个最主要的衣物类别来进行实验:连衣裙,半裙,上衣与下衣。详见下图。
Deep Fashion数据集:
http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion.html
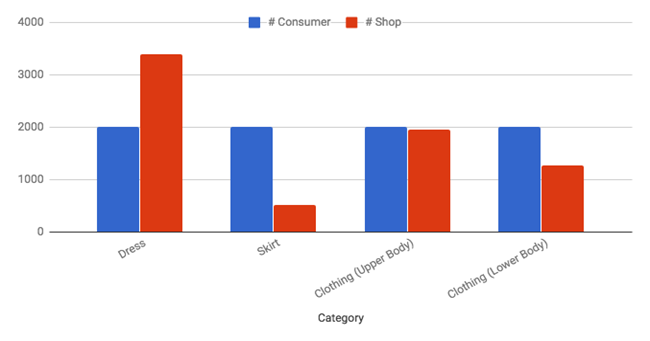
图2.各类衣物图片数据量
Deep Fashion数据集
http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion.html
图3与图4分别为买家与店家图片示例。这些例子展示了本任务的复杂性:匹配衣物的样式,但颜色不需要一致。

图3.(从左至右)图片1与2为买家衣服秀,图片3与4为同款店家衣服秀
从图3很容易看出,店家图片的质量较高,整件衣物都位于图片中央。买家数据集的挑战在于,每张图片都只对应唯一一个正确商品编码,所以有的与之非常相似但并不是同一商品的衣物就会导致模型精确度降低(请看图4)。为缓解此问题,我们使用Top-K准测来评估模型性能[QZ1](该方法也被用于衡量衣物相似度)。
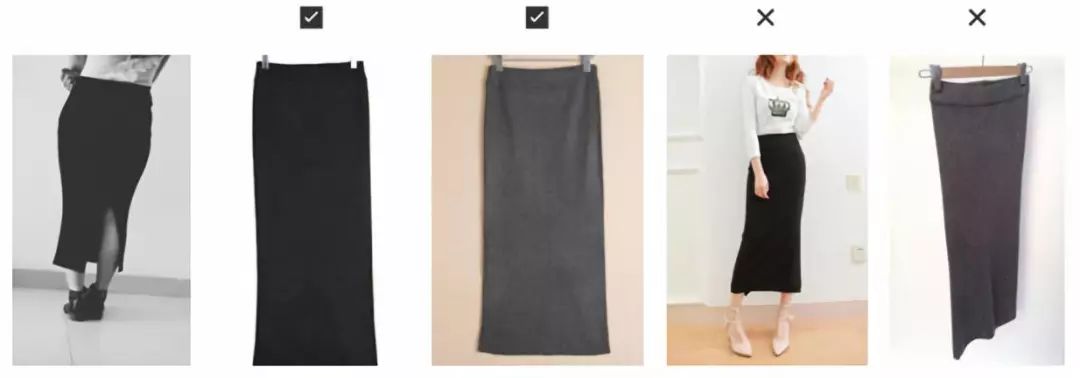
图4.左一为买家衣服图。左二与左三为同一件商品的店家图。左四与左五为另一件非常相似但却是不同商品的店家图。
t分布随机邻嵌入(t-Distributed Stochastic Neighbor Embedding, or t-SNE)是一种将高维数据映射到二维空间的常用可视化方法。我们使用t-SNE将预训练ImageNet模型从买家图片中提取出的特征进行可视化,结果如图5所示。裤子的图聚类于左下部,而半裙则聚类于右上部。左半边的图片多为包括腿部的买家图片,而右半边的则是放在平面上拍摄的衣物图片。

图5.t-SNE处理后的买家图片ResNet50分类特征结果
方法
我们尝试了三种方法:
白盒特征
预训练CNN特征
使用预训练CNN特征的孪生网络
下面详细介绍每一种方法。
1.白盒特征(White-Box Features)
我们第一个尝试的白盒特征图片提取器曾在计算机视觉上被广泛应用。特征先被提取,然后它们被连接起来以为每一张图片构造一种多特征的表述。我们在此提取了以下特征:
方向梯度直方图(Histogram of Oriented Gradients),计算图像的每一细分区块内各梯度方向的发生次数。
色彩直方图(Color Histograms),将图像中所有颜色划分为25个颜色区间并制作直方图以查看其分布。
色彩一致性(Color Coherence),衡量每一像素的色彩与其所属大区块颜色的相似度。颜色是衣物非常重要的一个属性,因此本特征提取器是用于补充色彩直方图信息的。
哈里斯边角侦测(Harris Corner Detection),提取图像中代表边角的特征点。
我们使用白盒特征计算了每一张买家图片的K近邻,并尝试了若干种标准距离度量函数(L1,L2,余弦函数)。结果如下图所示:
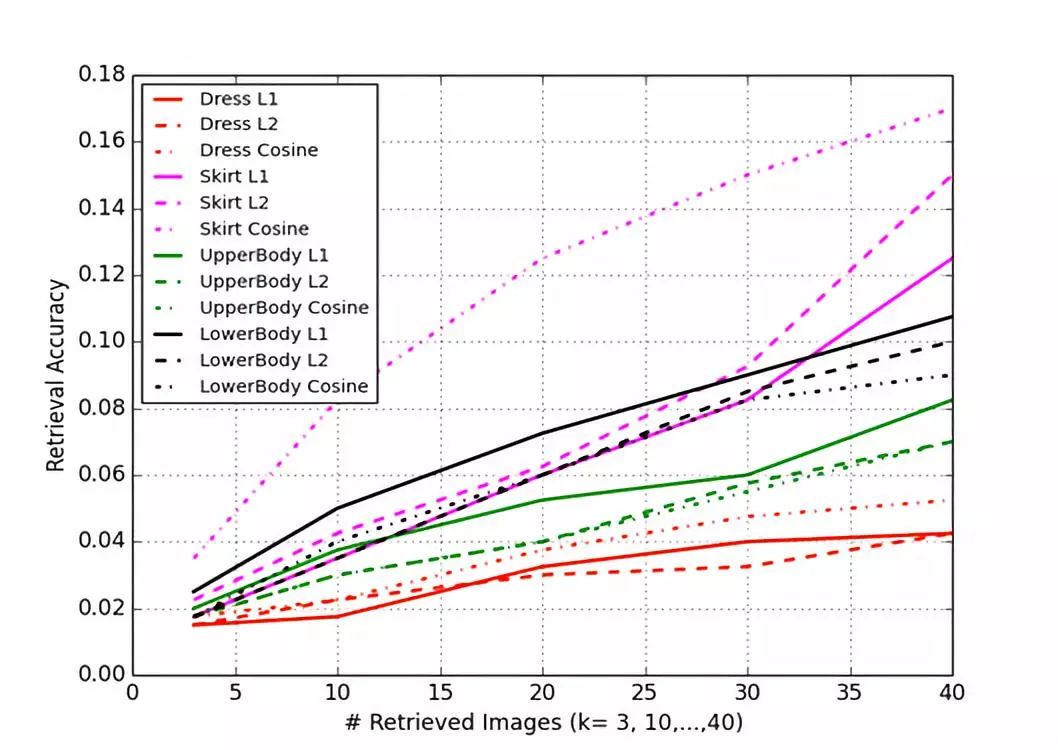
图6. 各类衣物白盒特征在不同距离函数下的表现
2.预训练CNN特征
在本方法中,我们使用预训练CNN模型对ImageNet上的1000个物体类别图像进行分类训练。
我们使用神经网络每层的激活函数作为特征表示。[w2] 我们在买家图像与店家图像上使用VGG-16,VGG-19,Inception v3和ResNet50进行训练,并且使用了L1作为度量函数。下图展示了上述模型的层数与参数数量。
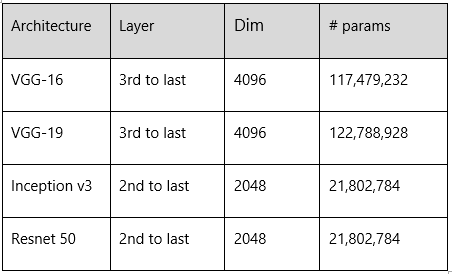
图7展示了模型结果。总体来说提取特征表现有了很大的提高,ResNet50提取的特征在所有类别上都具有最好的整体表现。半裙类别达到了最好的结果,使用Top-20准确率达到了17.75%。
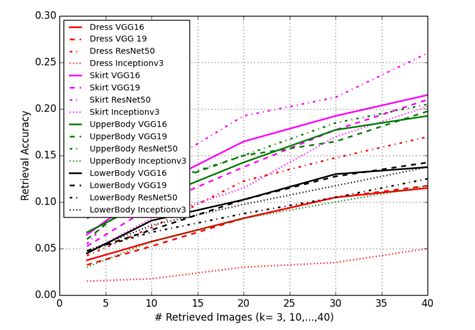
图7.各大类预训练CNN特征表现
在之前的方法中,我们分两步来计算距离函数。首先,我们使用低等级图像表征或预训练过的卷积神经网络最后一层隐藏层中提取出的特征,从图像中提取表征向量。然后将该向量代入标准化向量距离函数(如L1,L2与余弦函数)进行计算。然而在本方法中,我们使用提取出的买家与店家图像特征对来学习得到距离函数。这里我们使用孪生神经网络。
3.孪生网络
孪生网络包含两个或多个完全相同的子网络。这些子网络基本上拥有一致的结构与权重。输入值被分别传入这些网络,最后输出时再合成一个单独的输出值。该输出值衡量输入值之间的距离。该网络使用这些输出值进行训练,最小化相似输入值之间的距离,以及最大化不同输入值的距离。详见图8。
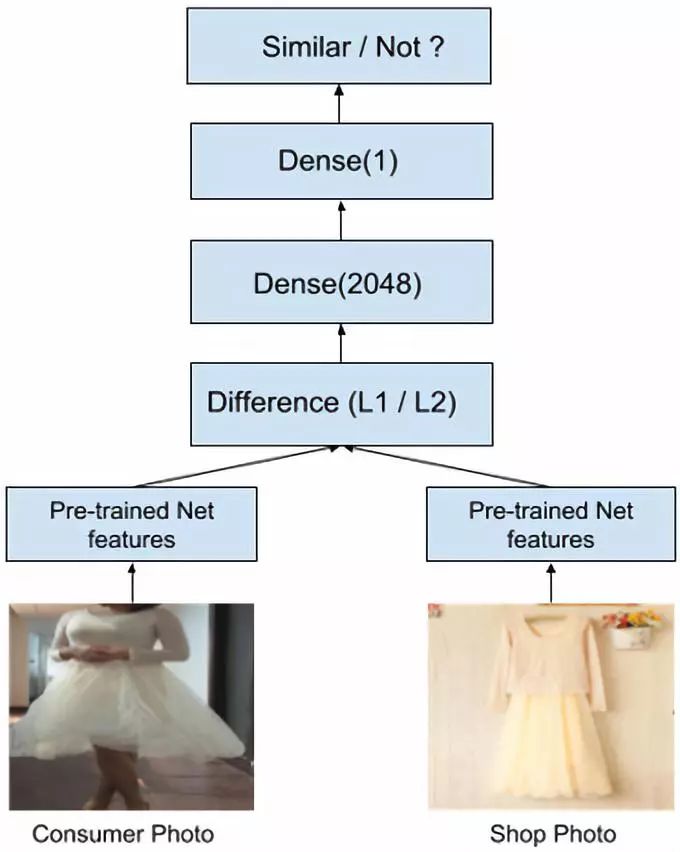
图8.模型结构
我们使用对数交叉熵损失函数,其表达式如下:
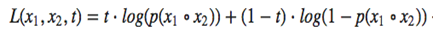
这里的X1与X2分别为买家与店家图像特征,t则为目标值——相似特征对则为1,不相似特征对则为0。使用孪生网络以及预训练ResNet50提取特征,结果在几乎所有类别上都有总体表现上的提升(除了连衣裙大类)。最佳表现来自于半裙类别,Top-20精确度为26%。
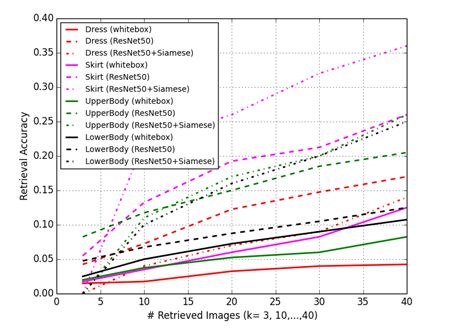
图9.三种方法在各类衣物图片的表现对比 1) 白盒特征 2) 预训练ResNet50特征 3) 使用孪生网络相似度的ResNet50特征
下图是模型能够正确匹配衣物的例子(见图10),其中排名前20的另外那些返回值也都直观上非常相似,他们基本都是同一件商品或相似商品不同颜色或不同材质。

图10. 前20位正确与错误匹配图(错误匹配中仅显示两张图)
应用数据科学虚拟机与Visual Studio AI集成开发工具
本部分中我们将展示如何使用数据科学虚拟机以及Visual Studio AI集成开发工具来开发深度学习模型。此外,我们还将解释如何使用Azure机器学习以通过类似API的方式操作模型。
数据科学虚拟机
数据科学虚拟机(DSVM)为Azure虚拟机镜像。它被预先安装、配置并测试。所用工具在数据分析、机器学习及人工智能训练中非常流行,如GPU 驱动以及深度学习框架(比如TensorFlow)。它帮助你在配置上节约大量时间,提高工作效率。
数据科学虚拟机:
https://azure.microsoft.com/en-us/services/virtual-machines/data-science-virtual-machines/
Visual Studio AI集成开发工具
Visual Studio AI集成开发工具是一个用来建立,测试并部署深度学习/人工智能应用的拓展功能。它与Azure机器学习无缝集成,并提供强大的实验鲁棒性——包括但不限于,向不同计算目标完全透明地提交数据准备与模型训练任务。此外,它还提供自定义衡量指标与历史记录追踪;实现了数据科学的可复用能力与审查能力。
Azure机器学习
Azure机器学习服务为数据科学家与机器学习开发者们提供了处理数据、开展实验、建立、管理并部署机器学习与人工智能模型等的一系列工具。它们允许使用任何Python工具与库。你可以在Azure上使用各种数据与计算服务来存储并使用数据。
训练
我们使用Azure机器学习命令行界面(Command Line Interface,CLI)和VS Code来将我们的数据科学虚拟机建立为一个远程计算目标,“my_dsvm”,并借此提交训练指令来运行实验。
部署
我们将模型与代码部署成网页服务的形式,从而可通过REST方式访问。为此,我们使用AML操作模型,结合Visual Studio AI集成代码工具以及Azure机器学习来进行部署,如下所示:
az ml service create realtime -f score.py –model-file model.pkl -s service_schema.json -n outfit_finder_api -r python –collect-model-data true -c aml_config\conda_dependencies.yml
这将使得任何使用REST API的用户都可以使用模型。
详细的部署指导:
https://blogs.technet.microsoft.com/machinelearning/2018/06/05/deep-learning-for-emojis-with-vs-code-tools-for-ai-part-2/
总结
本文中我们讨论了如何建立一个深度学习模型来对买家服装图像与网店相同或相似商品图像相匹配。我们展示了如何使用Azure的数据科学虚拟机与Visual Studio AI集成代码工具来快速开始建立、训练与部署模型。我们还展示了如何使用Azure机器学习来轻松操作模型。
代码链接:
https://github.com/ckanitkar/CS231nFinalProject。
编者注:Top-K Accuracy即,在返回的前K个结果中,只要出现了正确的预测结果,则该数据点被记为“正确预测”。
相关报道:
https://blogs.technet.microsoft.com/machinelearning/2018/07/10/how-to-use-siamese-network-and-pre-trained-cnns-for-fashion-similarity-matching/
【今日机器学习概念】
Have a Great Definition


志愿者介绍
回复“志愿者”加入我们










