2021 年模式识别与机器智能前沿研讨会于 10 月 29 日上午在线上举行,来自中山大学的林倞教授分享了题为《视觉语义理解的新趋势:从表达学习到知识及因果融合》的主旨演讲。
2021 年模式识别与机器智能前沿研讨会于 10 月 29 日上午线上举行。会议由中国自动化学会模式识别与机器智能(Pattern Recognition and Machine Intelligence,PRMI)主办,旨在将从事模式识别与人工智能各个方向的顶尖学者与研究人员聚集在一起进行技术分享,以便开展相关领域的交流与合作。在研讨会中,
来自中山大学的林倞教授分享了关于《视觉语义理解的新趋势:从表达学习到知识及因果融合》的报告
。表达学习和知识推理一直是模式识别与计算机视觉中的核心研究内容,两者的有效结合将成为打开当代通用人工智能的第一扇门。然而在机器视觉的背景下,如何将认知推理、知识表示与机器学习等多个领域的技术融会打通,依然是一个极具挑战和迫切的难题。
在报告中,
林倞教授首先简要回顾了计算机视觉领域从传统到现代的研究发展趋势,然后分享了他在表达学习和知识融合方面的一系列代表性工作
。林倞教授认为目前绝大部分的知识融合表达学习工作依然无法完全实现两者的有效融合,主要原因是高维度的视觉大数据难以避免地夹杂了各种混淆因子,导致深度学习模型难以从这些数据中提取无偏误的表征与因果相关的知识。鉴于此,林倞教授提出融入因果关系理解的知识表达学习的新视角和新方法。与现有因果推断作用于固定的低维度统计特征的做法不同,融合因果关系理解的表达学习往往需要结合复杂的多模态结构知识,以因果关系指导表达学习,再用学习到的表征反绎因果关系。
最后林倞教授分享了他所带领的中山大学人机物智能融合实验室(以下简称 HCP 实验室)最近在因果表达学习领域的研究进展
,并展示了如何将因果表达学习与多模态结构知识融合实现去数据偏见的解释性和优越模型性能。
![]()
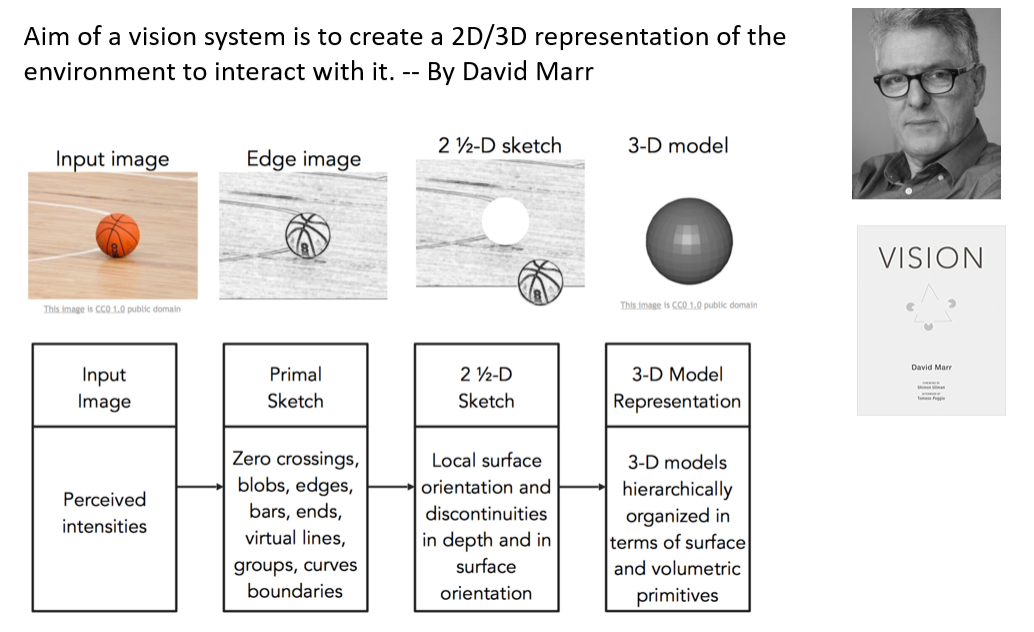
图 1.David Marr 首次对计算机视觉系统应该要做什么给出了观点。
计算器视觉奠基人之一的 David Marr 在他的著作《视觉》[1]一书中提出了视觉理解研究的核心问题(见图 1):视觉系统应以构建环境的二维或三维表达,使得我们可以与之交互(这里的交互意味着学习,理解和推理)。David Marr 把计算视觉表达分成几个层面,从单纯的二维视觉图像,然后到代表边缘结构和轮廓信息的原始简约图(Primal Sketch),再到包含一定程度深度信息的模态 2.5 维简约图(2.5-D Sketch),最后到完整的三维表达。长期以来,计算视觉领域都围绕这样一个脉络来开展研究工作。
![]()
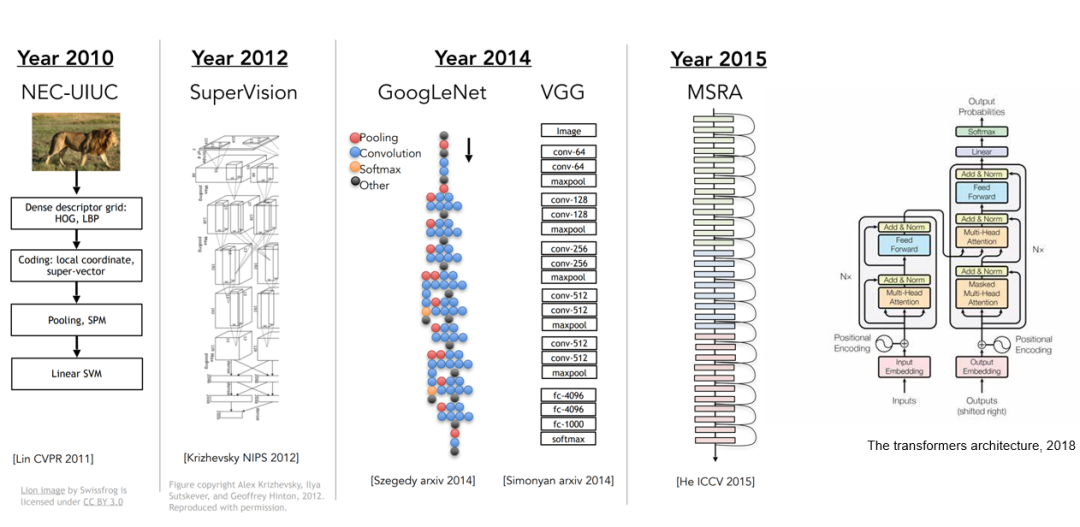
图 2. 神经网络架构随着研究的深入变得越来越复杂
后续的视觉研究越来越多地跟机器学习,特别是深度学习相关。2010 年,当时的主流做法是利用特征工程,比如 HOG[2],LBP[3],来提取图像的统计特征,再结合一些如特征金字塔等的特征增强方法,最后利用支持向量机等判别器来完成识别任务。自 2012 年起,深度卷积神经网络在 ImageNET 图像识别大赛中大放异彩,其技术本质上是舍弃了人工构建特征时造成的信息丢失,转而直接从图像中学习并提取判别性更强的视觉表达。于是越来越多的研究者开始关注如何利用更强的深度模型去提升视觉表达的学习能力,从残差网络到今天的 Visual Transformer 架构[4,5],近十年来的计算机视觉研究围绕着如何构建强大的表达学习模型这个主题。在深度学习蓬勃发展的过程中,各类视觉任务(如物体识别,检测,图像分割等)的性能不断提升。然而,该研究路线也逐渐遇到了瓶颈,这是因为仅仅通过设计神经网络模型,很多关于计算机视觉理解的问题无法得到根本解决。
![]()
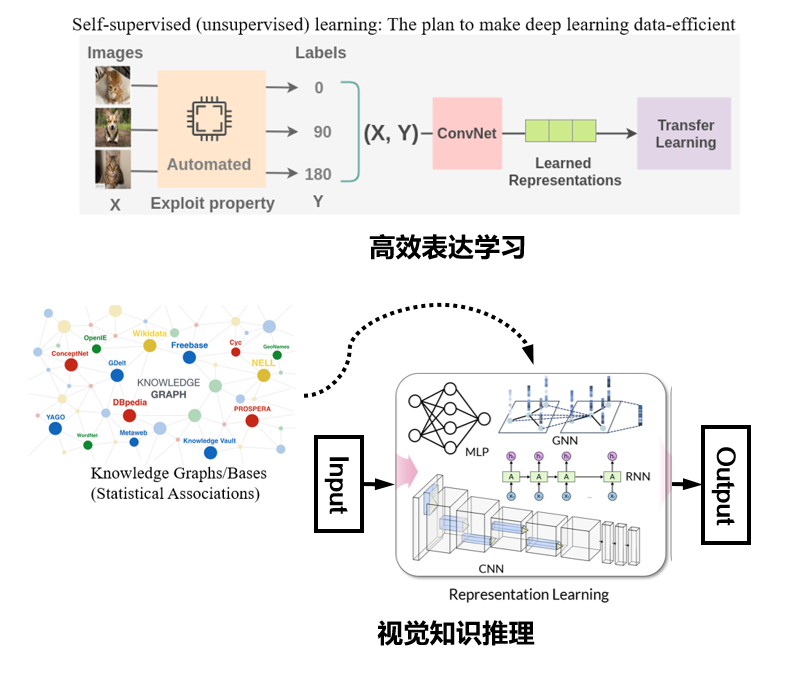
图 3. 计算机视觉研究的两大新出路:高效的视觉表达学习与视觉知识推理
这些问题我们可以归纳为两大方面(图 3)。第一是强调训练"性价比"(Cost-effective)的高效表达学习。图灵奖得主 Yan Lecun 在三年前的神经信息处理系统大会上的专题报告中,曾拿蛋糕作为比喻,其大意是如何利用无标注数据或者挖掘无标注信息,才是人工智能目前最值得关注的研究方向。这个方向包括了无监督学习,迁移学习或者自监督学习等[6,7],其技术核心是发掘图像视频数据中的一些内在属性和先验信息,通过预训练的方法先得到归纳偏置再拓展到下游任务中去,从而提升整个深度神经网络模型的训练效率,这类方法在自然语言理解、计算机视觉等领域有着诸多成功的应用,被认为是最近主流的一种研究和工程实践方法。第二,当我们试图跳出视觉表达学习的框架,用宏观的角度去看数据拟合的时候,我们会发现有很多领域上的问题,由于数据并没有很好地呈现完整的知识,通过拟合数据得到的模型往往无法排除数据带来的偏见。因此不论采用的是卷积神经网络,图神经网络或者是最近大热的 Transformer 模型,最终模型学习到的知识可能是错误的,并且无法解释。于是从 18 年开始,就有许多工作便试图将知识图谱、常识库等一些结构化、符号化的知识表达与表达学习相结合,转向更高理解层面的视觉知识推理研究。这些知识规则有两个核心作用。首先,在有标注样本缺乏的一些情况下,可以用这种知识规则去改善模型的学习能力。其次,知识规则指导的学习也可以让训练出来的深度神经模型与人类认知保持一定程度的一致,增强其可解释性。
基于上述两个方面问题,本人分享一下我们实验室最近的几个研究工作。
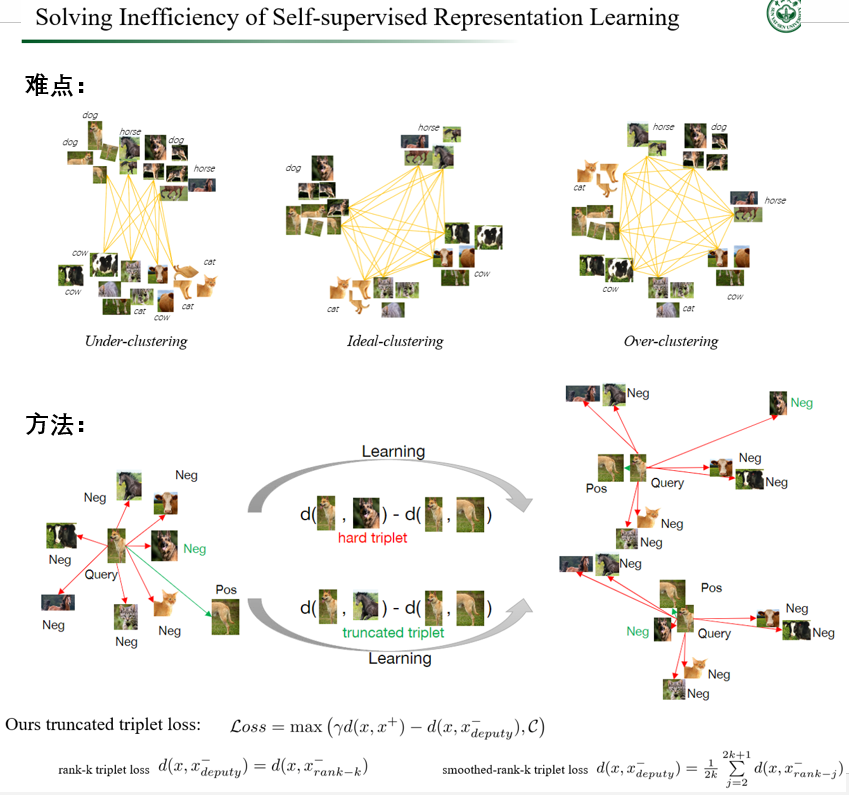
针对第一个问题,我们今年有一个与牛津大学 Philip Torr 合作的 ICCV 工作[9],内容是关于如何有效地构建训练样本组合,来实现高效的自监督表达学习,从而促进模型训练(见图 4)。更具体地说,现有的研究表明,即使自监督对比学习能够让预训练模型取得逼近甚至超越全监督预训练模型的效果,其代价是需要超过十倍的训练量。而我们的研究揭示了对比学习中的两个矛盾现象,我们称之为欠聚类和过度聚类问题:欠聚类意味着当用于对比学习的负样本对不足以区分所有实际对象类时,模型无法有效地学习并发现类间样本之间的差异;过度聚类意味着模型无法有效地从过多的负样本对中学习特征,迫使模型将实际相同类别的样本过度聚类到不同的聚类中。欠聚类和过度聚类是造成自监督学习效率低下的主要原因,而我们提出了一种高效的截断三元组样本对组合方法,采用三元组损失趋于最大化正对和负对之间的相对距离来解决聚类不足问题;并通过从所有负样本中选择一个负样本代理来构建负对,来避免过度聚类。从实验结果来看,我们的方法基本上能够在两倍于全监督训练量下达到其预训练模型水平,比起现有的自监督训练方法提高了 5 倍的效率。然后在下游任务的迁移上,如物体检测和行人再识别,在主流的大型数据集上都验证了这种方法的高效性,该方法训练出来的模型性能甚至优于一些全监督方法。
![]()
图 4. 中山大学 HCP 实验室关于研究高效自监督表达学习的最新成果,可以节省 80% 训练量的情况下,达到同样的模型性能。
![]()
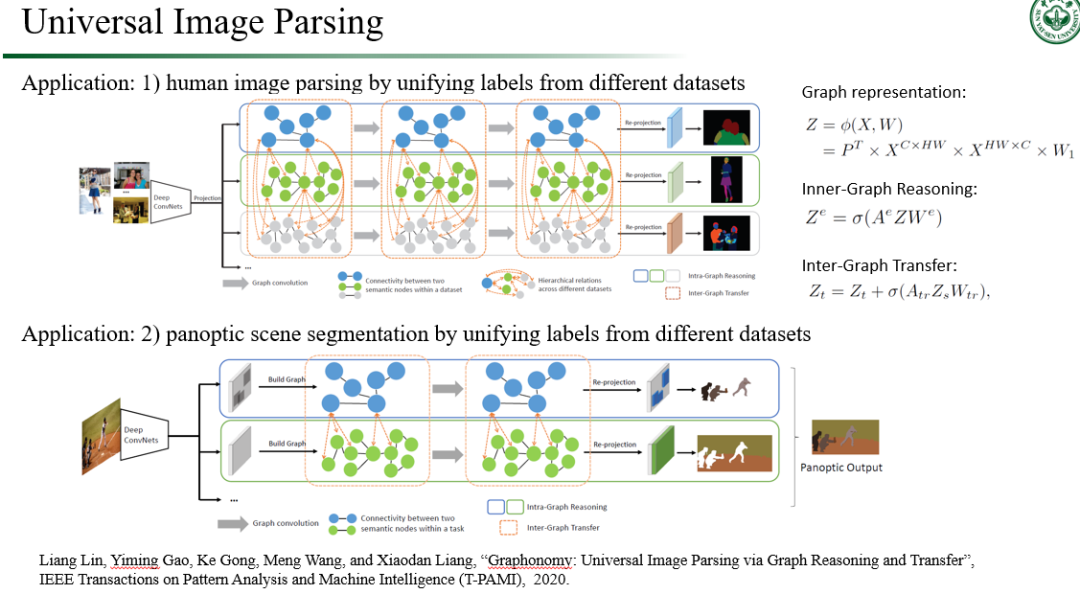
图 5. 中山大学 HCP 实验室在视觉推理方向上的代表性工作:通用图像解析。
而在视觉理解中的知识推理这一方面问题,我们实验室早在 2017 年就开展了相关研究,取得的成果也比较多。我首先介绍一下我们团队利用知识推理去辅助高层视觉语义理解的两个工作。第一个工作是关于如何实现通用的图像解析(Image Parsing,可看作是一种精细化的语义分割任务)模型[10] (见图 5)。通常要实现在某个领域上的图像解析,我们是要利用大量本领域上的图像数据参与模型训练的,这一方面往往不符合高效表达学习的设定,而另一方面,要让其实现在另一个领域上面的图像解析,模型则必须重新进行训练,因为新领域的图像分布和类别跟旧领域不一样。为了摆脱这些局限,我们的工作利用跨领域之间的知识共通性作为桥梁,将人类知识和标签分类法纳入到图卷积网络中构造新的迁移学习跨领域推理算法,再通过语义感知图推理和传输在多个域中保持一致性,实现跨域图像解析的语义包融和互补。我们的方法在著名人体解析数据集 LIP(顺带一提,该数据集也是由我们团队于 2017 年的 CVPR 工作中首次提出,在用于数次研讨会的专项比赛后,其已成为人体解析领域里面的著名基准数据集)中表现出非常优秀的跨领域人体解析效果。另外,在全景分割任务中,我们的方法也在跨领域迁移情况下达到了当前最先进的性能。
![]()
图 6. 中山大学 HCP 实验室在视觉推理方向上的代表性工作:融合知识推理的视觉问答。
第二个工作是关于如何融入外部知识去完成视觉问答任务[11](见图 6)。具体来说,视觉问答任务的技术本质需要实现对图像和对应语言的同步理解,这需要在完备的知识空间里面进行推理。然而现存的大部分视觉问答的推理是通过配对封闭领域下的问答数据而实现的,其训练的模型极容易产生偏误,难以泛化到开放世界下的问答场景中。我们的工作提出了第一个融合外部知识进行多段推理的数据集,该数据集衍生于真实的问答情况,同时提供了从数据领域到知识图谱的推理路径标签。这有助于衡量视觉问答过程的模型推理可解释性,同时也比较容易应对未出现过的提问情况。我们基于树层次结构提出了针对该问题的模块化视觉推理问答网络,能够灵活结合结构知识库进行视觉表达学习,高效地推演出问题答案。
除了高层视觉语义理解外,基于知识的视觉推理也可以被应用到一些传统的视觉任务当中,突破现有模型的性能瓶颈。接下来我简要介绍一下我们团队在这方面的四个工作。
![]()
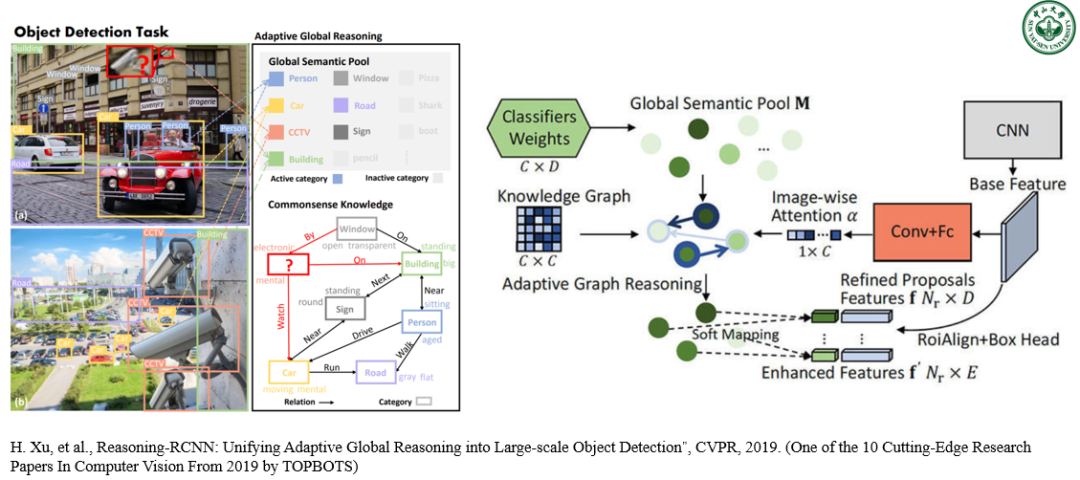
图 7. 中山大学 HCP 实验室利用视觉推理技术提高复杂场景下大规模物体检测的性能。
第一个是我们在 CVPR-19 提出的 RCNN 系列衍生模型 Reasoning-RCNN,将基于知识图谱的常识推理技术整合到神经符号模型中,从而让物体检测网络在所有对象区域上具备自适应全局推理的能力,能有效应对大规模物体检测问题中的长尾数据分布,严重的遮挡和类别模糊性等挑战。Reasoning-RCNN 不仅能在视觉层面上传播信息,同时也在全局知识范围内学习所有类别的高级语义表示。基于检测网络的特征表示,Reasoning-RCNN 首先通过收集每个类别先前的分类层权重来生成全局语义池,然后通过联系全局语义池中上下文的不同语义来自适应地强化每个对象特征的信息。这让 Reasoning-RCNN 具备可扩展集成任何知识的能力。在三个大规模物体检测的基准数据集(物体种类可以多达数千个)中,Reasoning-RCNN 实现了 15%-37% 的最优性能提升。该研究也被全球人工智能行业战略研究公司 TOPBOTS 评选为 2019 年计算机视觉领域最前沿的十个工作之一。
![]()
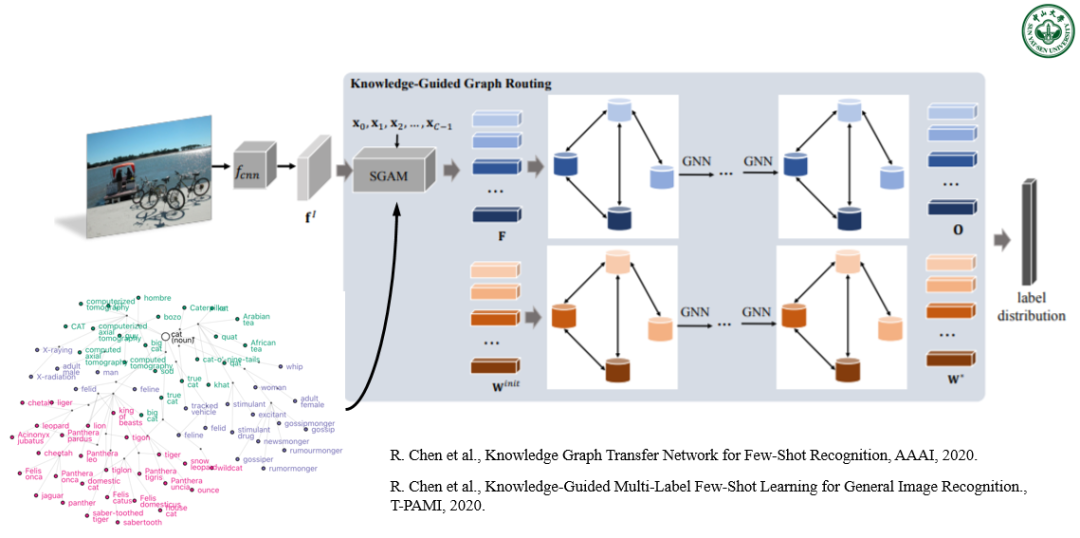
图 8. 中山大学 HCP 实验室利用视觉推理技术去解决大规模类别数量下的小样本单分类和多分类视觉物体识别问题。
我们第二个工作专注于利用外部知识推理去辅助小样本分类的建模。现有基于元学习的解决办法在不同的小样本类别的子任务之间的偏差较大,而我们的工作通过外部知识构建小样本类别和多数类别之间的全局联系,其优势在于稳定小样本分类模型训练和提高其分类鲁棒性。具体来说,它首先构建一个结构化的知识图谱,通过推理不同的类别的共现概率去建模所有类别的全局联系,然后引入标签语义来指导学习特定于语义的特征初始化标签。我们将知识图谱中每一个节点看作某个类别的单分类模型,并通过图神经网络推理去实现它们的消息传播机制从而进行语义关联的模型训练。该方法能有效解决超大规模类别的单分类小样本物体识别问题,同时也能够轻易扩展到多标签小样本分类问题当中。
![]()
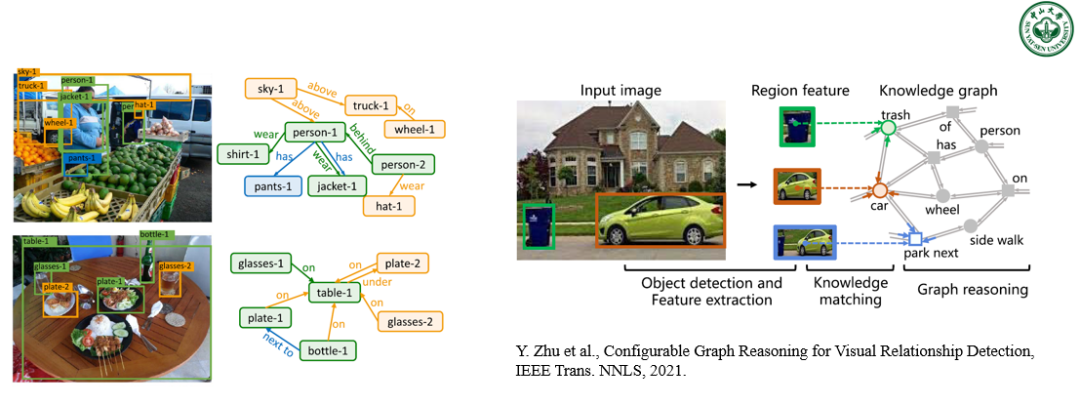
图 9. 中山大学 HCP 实验室利用视觉推理技术去解决视觉关系分类中的长尾问题。
我们第三个工作研究的是以判别对象和关系标签为目的的长尾视觉关系分类。当前大多数方法通常通过遵循 {主体,客体} 的固定推理路径来识别低频率出现的关系三元组。然而,这种固定的依赖路径的知识整合往往忽略了常识知识和真实场景之间的语义差距,容易受到对象和关系标签的数据集偏差影响。为了缓解这种情况,我们提出了可配置图推理来分解视觉关系的推理路径,并结合外部知识,实现对每幅图像中每种关系类型的可配置知识选择和个性化图推理。给定常识知识图,可配置图推理网络学习匹配和检索不同子路径的知识,并有选择地组合知识路由路径,弥合了常识知识与现实场景之间的语义鸿沟。大量的实验表明,可配置图推理网络在几个流行的基准测试中始终优于以前的最新方法。
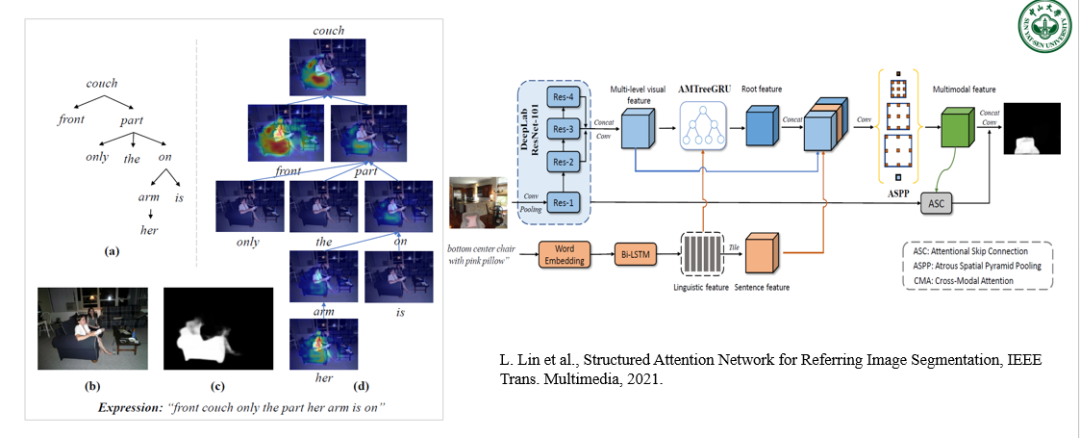
在第四个工作中,我们专注于图像描述分割问题。该任务的实质是在给定某个自然语言描述下作出跟该表述相关的图像分割,而难点在于如何在抽象的语言表述中实现精细化的分割结果。我们试图通过解析给定语言表述的依赖树结构去实现多模态推理结果。技术上来说,我们提出了基于树结构的多模态循环神经网络模块,将低层特征通过语义引导融合到高层特征中,贯彻自底向上的语义一致性。实验证明了我们这个方法能够有效学习语言描述的粗粒度语义与像素层面的精细语义的对应,从而在该任务中进行多模态推理实现优秀的分割效果。
![]()
图 10. 中山大学 HCP 实验室利用视觉推理技术去实现描述性图像分割中的多模态推理。
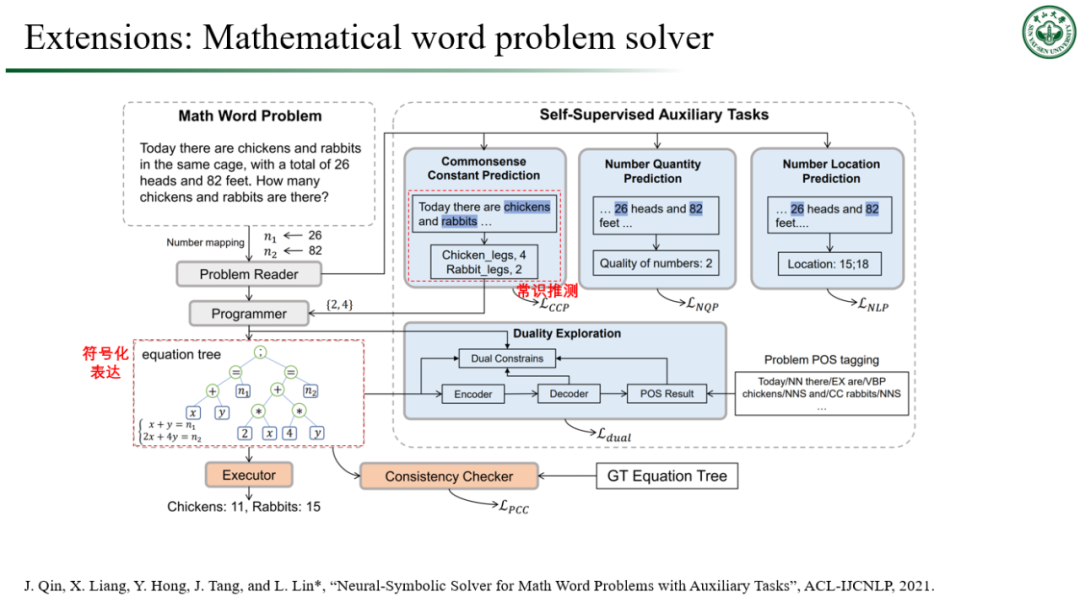
![]()
最后值得一提的是,我们基于高效自监督学习和知识推理的研究思想也可拓展到一些自然语言处理的领域。在今年 ACL 上(图 11),我们提出了一个基于自监督辅助任务学习进行推理,再实现数学应用题求解。每一个辅助任务所解决的都是关于应用题里条件的具体描述情况,而对这类信息的正确把握实际上是推理过程中的中间结果,对最终求解起着重要作用。我们利用神经符号模型将辅助任务信息和树结构推理模型结合起来,最后的模型在四个现有的基准数据集上达到了目前最优的效果。
![]()
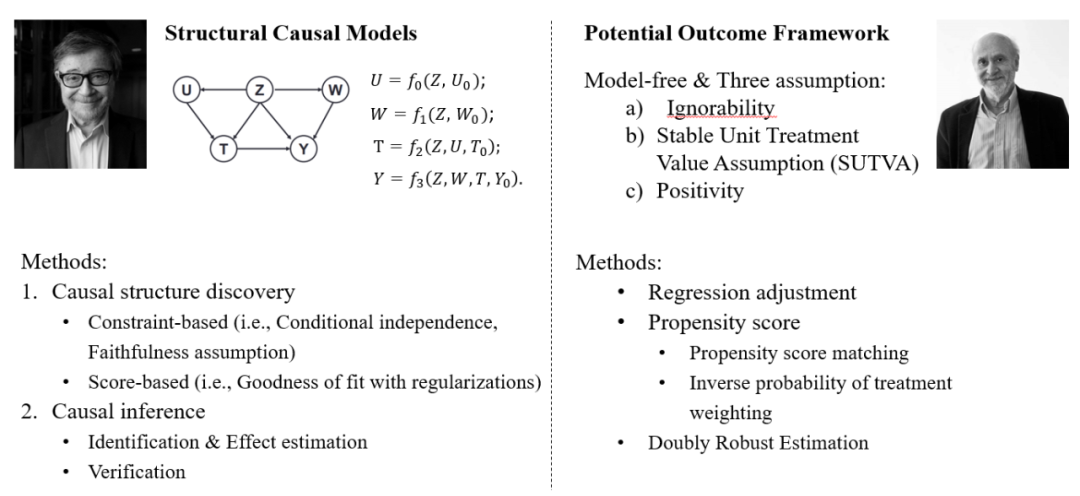
图 12. 因果推理的两大技术流派:以 Judea Pearl 为首的结构因果模型和以 Donald Rubin 为首的潜在结果框架。
结合知识与推理的表达学习,推动着视觉理解从下层感知逐渐往上层认知过渡,极大地促进了模式识别与人工智能学界的发展。然而要通往认知智能的终点,单纯依赖知识与表达学习仍然远远不够。一方面,现存的绝大部分深度学习技术无法避免的一个问题就是主要关注关联而忽略因果,因此其训练的模型在鲁棒性和解释性方面都会出现很多问题。另一方面,高维度视觉大数据的复杂性往往导致其模型训练难以避免各种混淆因子的影响,导致最后学习到的表征与知识蕴含难以预测的数据偏误。于是,相关研究工作开始考虑在视觉理解过程中去介入"反思"的机制,其本质就是试图将因果推理的思想融入到表达学习中,达到真正的"知其然,亦知其所以然"的目的。
有关"因果"两字的定义往往可以追溯到上古各个哲学流派的讨论,而近代的多个学科也有独立提出其见解的一系列研究。在统计学习与人工智能领域中,比较广为人知的有两个技术派系。第一个派系以 Jerzy Neyman 教授和 Donald Rubin 教授各自独立提出的潜在结果框架(Potential Outcome Framework)[12]为主要分析工具,基于不同的随机对照实验组作为研究对象,考察其条件个体受试作用(Conditional Individual Treatment Effect)作为判别不同变量之间是否存在因果关系的主要依据。而第二个派系则以 2010 年的图灵奖得主 Judea Pearl 教授为首,提倡从三个层次的因果阶梯出发去理解世事万物变量之间的因果关系 [13]。其阶梯的第一层"关联",指的是事物变量同时发生的联合概率,也正是目前深度学习能够解释的深层的变量统计关系。Reichenbach 教授[14] 明确指出统计相关性所蕴含的信息是严格小于因果关系的,因此要得到更深层次的因果关系信息我们必须把因果理解上升到第二层次的"干预",即对这个世界的我们感兴趣的事物做某种改变,那么有各种的可能性,而不同的改变会有不同的结果,从而让其反馈而获取更多信息。最后,由于现实世界并不允许我们能够进行任意的交互和改变,一个典型的例子是在固定某个时间变量下,我们往往只能做出一次干预和观察。因此,我们需要把因果关系的理解上升到第三层的"反事实",也就是对于每一次干预的发生,我们都能借助类似人类"反思"的过程,去比较其干预和不干预下的结果差异。基于对因果关系的深刻理解,Judea Pearl 教授进一步提出了因果图模型(Causal Diagram)和 Do 算子(Do-operator)作为其研究因果关系的理论框架和实现因果推理的工具。在其著作《为什么》一书中,他阐明了潜在结果框架和因果图模型之间的共通性,证明了真理纵使表现形式不同,其结论总是殊途同归的道理。
![]()
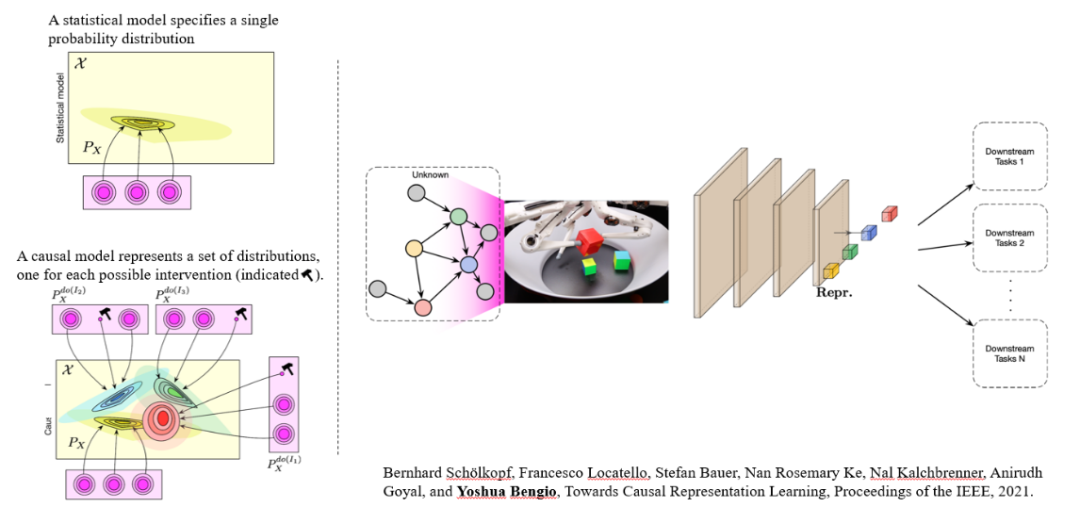
图 13. Joshua Bengio 教授对因果推理和表达学习的新理解。
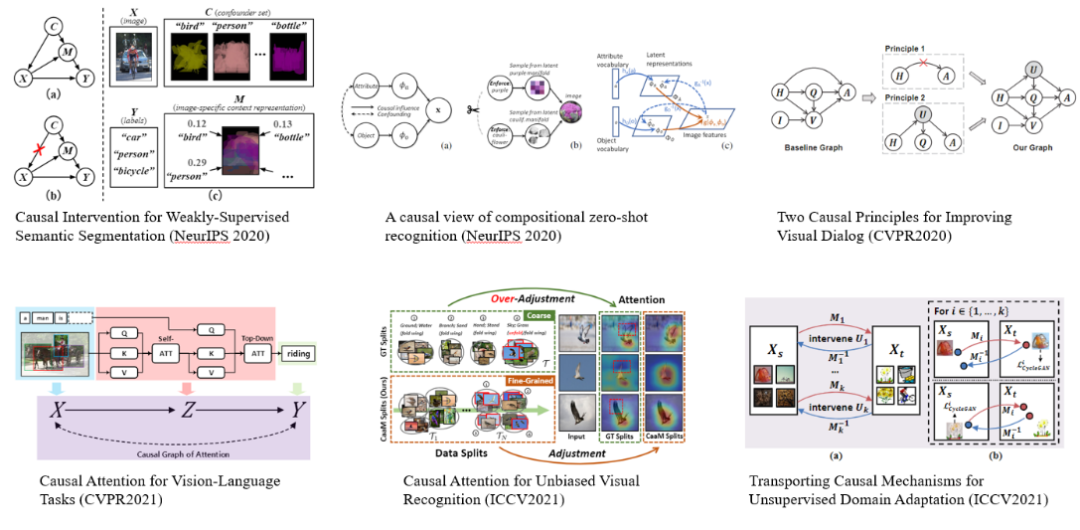
值得注意的是,纵使因果推理已有广泛的算法研究,要让其与深度学习模型结合指导复杂的视觉理解任务,依然存在不少挑战。一方面是该类算法假设的因果图往往是固定的,而且复杂度也比较低,另一方面则是其因果假设与推理的变量单元也经常是低维度变量,蕴含的信息量很少。但是,真实世界的推理单元往往是具有丰富语义信息的高维度变量(如物体),观测结果最初往往并未对推理进行结构化。有鉴于此,图灵奖得主,深度学习研究领域的泰斗 Joshua Bengio 教授在最近的研究中提出了他对深度学习和因果关系的独到见解[15]。他认为深度学习拟合的是一个单一的数据分布,其本意就是只有一个观测世界,而一般的深度学习则是去拟合该世界的唯一分布。但由于我们的世界是动态变化而且分裂通向多元未来的,这意味着现有的深度学习实际上是在过拟合我们的观测世界,而对未来的改变却显得无能为力。因此,Bengio 教授进一步提出了"因果表示学习"的概念,试图从数据中学习到这些变量表达以及建立结构关系,同时去学习,拟合不同世界,不同可能下的分布情况。这过程当中就会对应到因果理解中的干预和思,从而与不同的下游任务构建起关系。Bengio 教授的"因果表示学习"概念深深地影响了最近的计算机视觉领域的一些研究,如弱监督语义分割,视觉对话,零样本学习等(见图 14)。
![]()
图 14. 最近的一些关于计算机视觉结合因果表达学习的工作研究。
最后本人分享一下我们实验室最近在因果表达学习的一些研究进展,这包含了两个工作。第一个是计算机视觉的工作,研究的是如何结合因果图进行图像合成的;而第二个工作则跳脱计算机视觉的局限,研究医学诊疗数据下面的无偏推理问题:多轮对话下的自动医疗问诊。不同于现有大部分对因果表达学习的探索,我们这两个工作强调了如何利用外部知识或者数据中已有的结构信息,去辅助因果表达学习完成更加复杂的任务,对因果表达学习领域的未来研究具有一定的启发性。
![]()
图 15. 中山大学 HCP 实验室关于表达学习生成模型结合因果图推理的研究工作。
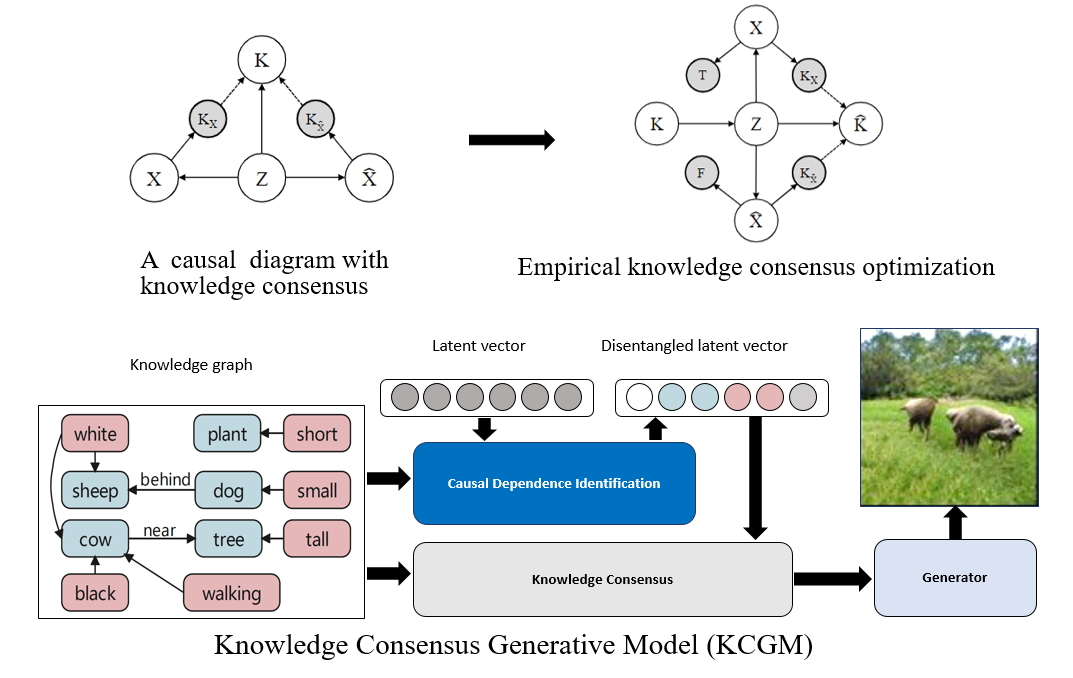
在第一个工作中,我们研究如何在给定一个语义场景图的情况下,实现从高层抽象语义到底层视觉数据的图像生成。这可以看成是场景图预测的反问题。而实现的过程中有两个难点:一个是如何保证生成的图像蕴含的语义信息与给定场景图的语义信息保持一致;另一个则是如何让生成图像的布局具有解耦性,就是修改布局的其中一部分语义不会引起整个图像的扭曲。而要实现这种结构上的布局解耦,实际上就是把相关变量看成是混淆因子来进行因果表达学习的过程。于是我们可以看到,从场景图到合成图像的生成过程,我们都可以用结合外部知识的因果图来表示。我们利用了生成对抗学习网络架构实现逼真的图像生成,同时采用变分自编码器的特性学习隐空间表达,使生成图像中对应的元素符合解耦性。而生成学习的目的则是在保持生成图像尽可能逼真的前提下,如何让生成的图像语义在结构因果关系的约束下,同时保持内在语义和外部知识的一致性。实验的结果也验证了,我们的方法不但能从场景图中生成语义一致的图像,还可以对其中的结构语义信息进行动态删减和增加,同时保持被编辑外的图像语义不会受到干扰和改变。
![]()
图 16. 中山大学 HCP 实验室利用因果推理技术实现可解释医疗自动诊断的研究工作。
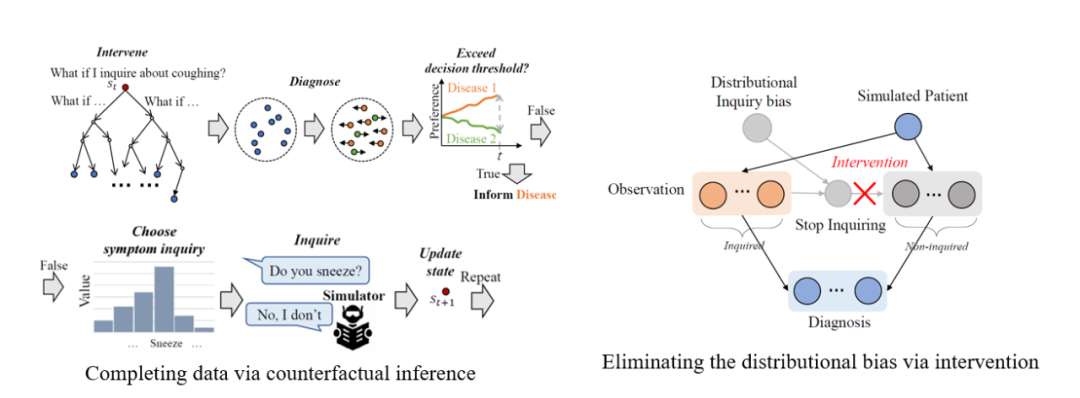
我们的第二个工作研究的是医疗自动诊断,即训练一个代理模型与患者进行动态交互问诊,在准确的前提下尽可能快地提前结束问诊并进行疾病的诊断。这本质上是一个数据挖掘建模结合机器学习的问题,现有的方法基本上是利用观测数据去构建一个患者模拟器,从而模拟交互问诊过程并对诊断代理模型进行训练。但这个医疗对话的模拟过程实际上使用的是观测的被动数据,这会造成两大因果类的偏误问题。第一个情况是,如果某一个病人的问诊记录存在从未被医生问起某种症状的时候,当问诊策略访问到该病人的记录进行交互训练的时候,患者模拟器只会返回 “不知道” 的空值回答,因而代理模型是无法构建针对该症状时的问诊策略的。这是因为该病人对于此症状的对话数据只存在于反事实世界中而没在真实世界中出现过。该问题被我们称为默认答案偏差,经常会发生在医疗诊断的数据中,原因非常好理解:真实世界中的医生往往都是通过先验知识去搜索最短的问诊路线,不存在试错的过程。而另外一个问题是,由于现存的患者模拟器是基于纯经验的,从因果推断的角度,它代表的数据往往只能反映出过去某一个观测。而基于这些观测训练出来的问诊代理模型,其策略也只会过拟合到这个观测世界中,而在面对医疗诊断的时候,这个分布查询偏差问题往往是致命的,因为这些信息在代理模型进行查询的过程中往往会带来数据偏见,使得最后的诊断结果产生错误。
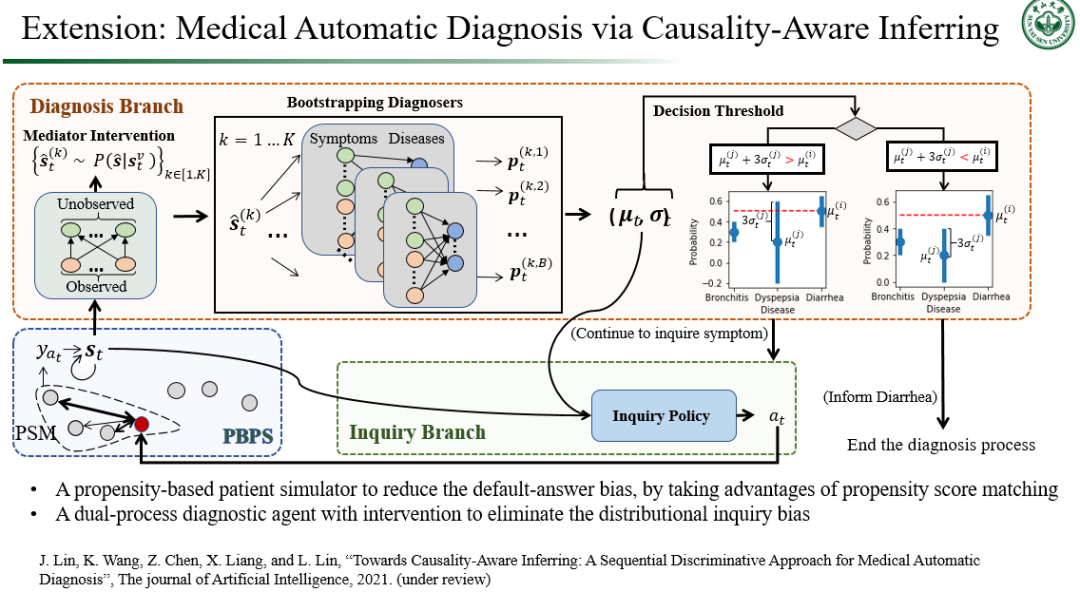
我们的工作试图利用因果结构图对不同症状和疾病因子进行分析,再结合潜在结果框架去消除这两类偏差,最终实现无偏,可解释的医疗自动诊断。受到潜在结果模型技术的倾向评分匹配启发,我们首先提出基于倾向分数的患者模拟器,其目的是取代受到数据偏见影响的观察数据患者模拟器,通过从其他记录中提取知识来有效回答未记录的询问(图 - 16 的左边子图)。更具体地说,我们的方法首先通过因果结构图去判定出每次询问过程中的哪些因素是对撞因子,接着基于每个观测数据中被询问的症状和疾病的关系,用倾向性评分匹配策略去计算每个记录的倾向性评分并聚类不同的询问记录。那么对于每个观测记录中不存在的症状询问,我们都可以通过其聚类的其他观测记录去寻找类似的答案,其询问结果满足潜在结果框架下的无偏估计。不但如此,这个方法可以被用于所有基于交互的自动问诊代理模型的训练中,让其克服由于交互方式不当造成的问诊答案偏差。另外,为了克服分布查询偏差,我们在利用基于倾向分数的患者模拟器同时,提出了一种渐进式代理网络模型,把策略分解为症状查询和疾病诊断的两部分(图 - 16 的右边子图)。询问过程由诊断过程以自上而下的方式驱动,以询问症状对患者的未知方面进行干预。其干预结果可以进一步推断多个在未来可能会产生的交互情景。基于交互对不同的未来发展轨迹进行聚类,我们可以依据不同的聚类结果对应到不同的疾病判断中。因此每个完成交互后的轨迹,并将对应不同的疾病诊断,而最大化不同聚类簇之间的距离,则能够增强结束对话时候的疾病诊断置信度。该诊断过程实际上可以被看作是到神经科学里面的发散模型:在心理和概率上描绘患者,并通过干预想象的问题(例如“如果患者咳嗽怎么办?”)在该心理表征中进一步解释原因,具有现有疾病诊断智能体不能比拟的可解释能力。通过上述干预,我们提出的代理能够根据症状的存在与否进行诊断,以消除分布询问偏差。
![]()
图 17. 基于因果推理医疗自动诊断的具体实现框架。
我们采纳了两个真实场景下采样的数据集对我们的工作进行评测。对于倾向分数的患者模拟器,由于真实场景的测试数据也是观测数据,我们基于反事实推断衍生的评价标注去衡量其是否能够有效实现反事实推断。另外再引入症状密度(symptom density)去测量我们的模拟器是否可以避免陷入回答 “不知道” 这些无意义的回答中。最后,我们雇佣了一部分来自中山医学院的学生去评价不同智能体代理的疾病诊断效果。我们的实验结果表明了现有基于观测数据进行交互训练的智能体,其诊断结果极容易受到现存交互记录数据影响,难以训练出在真实场景下可靠的问诊模型。而我们提出的患者模拟器则能够比较好地适应这种变化。同时,不论是基于观测测试数据的准确率还是专业人员评价,我们的代理策略模型也体现出了更优秀的疾病诊断效果。
我们从计算机视觉作为切入点,见证了人工智能从 David Marr 朴素的视觉理解概念开始,一路到今天以深度神经网络模型和表达学习为研究轴心的蓬勃发展。同时,我们也发现了该路线渐渐走到了奇点。不同于一些学派认为表达学习难以学习高层认知,我们主张目前的表达学习应该结合知识推理和因果模型去实现下一阶段的技术飞跃:因为知识推理可以实现从人类知识到机器认知的一致迁移,而因果模型则为理解机器推理提供严谨的技术手段。我们实验室关于知识推理和因果模型的一系列工作也从侧面验证了我们的观点。
[1].Stevens K A. The vision of David Marr[J]. Perception, 2012, 41(9): 1061-1072.
[2].Dalal N, Triggs B. Histograms of oriented gradients for human detection[C] 2005 IEEE computer society conference on computer vision and pattern recognition (CVPR'05). Ieee, 2005, 1: 886-893.
[3].Ojala T, Pietikäinen M, Harwood D. A comparative study of texture measures with classification based on featured distributions[J]. Pattern recognition, 1996, 29(1): 51-59.
[4].Dosovitskiy A, Beyer L, Kolesnikov A, et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale[C] International Conference on Learning Representations. 2020.
[5].Liu Z, Lin Y, Cao Y, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C] Proceedings of the IEEE International Conference on Computer Vision, 2021.
[6].Ganin Y, Lempitsky V. Unsupervised domain adaptation by backpropagation[C] International conference on machine learning. PMLR, 2015: 1180-1189.
[7].He K, Fan H, Wu Y, et al. Momentum contrast for unsupervised visual representation learning[C] Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 9729-9738.
[8].Kenneth Marino, Ruslan Salakhutdinov, Abhinav Gupta; The More You Know: Using Knowledge Graphs for Image Classification [C] Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 2673-2681
[9].Wang G, Wang K, Wang G, et al. Solving Inefficiency of Self-supervised Representation Learning[C]. Proceedings of the IEEE International Conference on Computer Vision, 2021.
[10].Lin L, Gao Y, Gong K, et al. Graphonomy: Universal Image Parsing via Graph Reasoning and Transfer[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
[11].Qingxing Cao, Bailin Li, Xiaodan Liang, Keze Wang, and Liang Lin, “Knowledge-Routed Visual Question Reasoning: Challenges for Deep Representation Embedding”, IEEE Transactions on Neural Networks and Learning Systems (T-NNLS)
[12].Sekhon, Jasjeet S. "The Neyman-Rubin model of causal inference and estimation via matching methods." The Oxford handbook of political methodology 2 (2008): 1-32.
[13].Pearl, Judea, and Dana Mackenzie. The book of why: the new science of cause and effect. Basic books, 2018.
[14].H. Reichenbach. The Direction of Time. University of California Press, Berkeley, CA, 1956.
[15].Schölkopf B, Locatello F, Bauer S, et al. Toward causal representation learning[J]. Proceedings of the IEEE, 2021, 109(5): 612-634.
![]()
林倞,中山大学计算机学院教授 / 博导,国家优秀青年基金获得者,教育部超算工程软件工程研究中心副主任,IET Fellow,先后在美国加州大学洛杉矶分校、香港中文大学等机构工作或访问研究。长期致力于视觉计算与推理学习的基础研究,提出认知模型引导的视觉表征学习理论和方法体系,包括结构化视觉语法模型、长效自主学习等基础方法,深入探索面向海量复杂视觉数据的模型泛化和推广能力,迄今在国际知名学术期刊与会议上发表论文 200 余篇,论文被引用接近 2 万次。获得 ICME 2017 最佳论文钻石奖,Pattern Recognition 期刊年度最佳论文奖,ICCV 2019 最佳论文提名;指导学生获得 ACM 中国区优秀博士论文奖(每年度 2 名)、中国计算机学会优秀博士论文奖;作为第一完成人获得 2018 年度吴文俊人工智能自然科学奖、2019 年度中国图像图形学会科学技术一等奖。
2021 博世中国 x 机器之心 AIoT 线上黑客松,20万奖金等你来赢!
10月15日至11月27日,互联交通、互联工业、碳中和、互联生活四大赛道以科技之名,看AIoT从业者有哪些新创意!
获奖创业团队 / 个人与博世中国合作;博世中国千元大礼包、机器之心2022 年度1999元Pro会员;博世中国实习机会、机器之心合作网络企业实习推荐等,更多优厚福利等你来赛!
识别下方海报二维码,立即报名。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com