【nlp入门了解】自然语言处理—关系抽取
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要11分钟
跟随小博主,每天进步一丢丢


https://www.cnblogs.com/vpegasus/p/re.html
Author: Vpegasus
E-mail: pegasus.wenjia@foxmail.com
编辑:泛音(公众号DLCV)
信息抽取在自然语言处理中是一个很重要的工作,特别在当今信息爆炸的背景下,显得格外的重要。从海量的非结构化的文本中抽取出有用的信息,并结构化成下游工作可用的格式,这是信息抽取的存在意义。信息抽取又可分为实体抽取或称命名实体识别,关系抽取以及事件抽取等。命名实体对应真实世界的实体,一般表现为一个词或一个短语,比如曹操,阿里巴巴,中国,仙人掌等等。关系则刻画两个或多个命名实体的关系。比如马致远是《天净沙 · 秋思》的作者,那么马致远与《天净沙 · 秋思》的关系即是“创作”(author_of )关系,邓小平是党员,那么邓小平与共.产.党则“所属”(member_of)关系。
关系抽取可分为全局关系抽取与提及关系抽取。全局关系抽取基于一个很大的语料库,抽取其中所有关系对,而提及关系抽取,则是判断一句话中,一个实体对是否存在关系,存在哪种关系的工作。
关系抽取分两步,一步是判断一个实体对是否有关系,而另一步则是判断一个有关系的实体对之间的关系属于哪种。当然这两步可变成一步,即把无关系当作关系的一种(特殊的),来进行多类别分类。
在监督学习的模式下,传统的关系分类方法为基于特征的方法与核方法,耗时,费事,准确度不高。
远程监督:
人工标注费事耗时还伤钱,2009年Mintz等人提出了远程监督方法。远程监督是借助外部知识库为数据提供标签,从而省去人工标注的麻烦。Mintz提出一个假设,如果知识库中存在某个实体对的某种关系,那么所有包含此对实体的数据都表达这个关系。理论上,这让关系抽取的工作大大简化。但远程监督也有副作用,因为不用人为的标注,只能机械地依赖外部知识库,而外部知识库会将同一对实体的所有情况都会标注一种关系,其标签的准确度就会大大的降低。比如‘汉武帝封卫青为大将军’,外部知识库中有关系:君臣_(汉武帝, 卫青)。,在这句中,'君臣'关系完全正确,但在另一句‘汉武帝是卫青姐姐的丈夫’,这里表达的关系可以是:亲属_(汉武帝, 卫青),而不是’君臣‘,此时外部知识库提供的信息就是不准确的,从而引入大量的噪声。因此目前在远程监督这个方向上的研究几乎都是聚焦在如何降噪。
2010年Riedel对Mintz的远程监督方法进行改进,提出EALO(Expressed-at-least-once)假设:如果知识库中存在某个实体对的某种关系,那么至少有一个提到此对实体的数据表达此种关系。这个假设相对之前的假设确实温和了许多,也确实更贴近实际。但这假设也将抽取工作变得复杂,人们并不知道有哪些数据表达了知识库中提到的关系,而哪些为噪声。因此Riedel引入另一个技术称为多示例学习(multi-instance learning). 多示例学习第一次引入机器学习中是在1997年,Dietterich在研究药物活性预测中遇到到一个问题,即大多数时候,人们知道哪种药物分子有活性,适合制药,但因为药物分子大多是同分异构体,同种药物分子会有多种分子结构,其只可能只有一种结构真正地有药物活性。
多示例学习是一种监督学习模式,虽然因此信息不充足,没有办法为每个数据样本打标签,但可以对具有某种特征的数据样本集合打标签,这样的样本集合称为袋(bag). 即在多示例学习中,每个bag有标签,而每个bag中含有多个数据样本,每个样本即为一个示例(instance)。
正式地,设示例集, 根据某种映射f,将示例集映射到bag空间, 然后,将经过某种映射f2,将bag空间映射到标签空间。
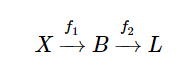
比如在关系抽取中表示的一般为将同一实体对放在同一个bag中。而映射则是要学习的机器学习模型,将每个bag正确地打上标签。
当前主流的关系抽取模型几乎都在使用引入多示例学习的远程监督方法,再结合深度学习。目前自然语言处理的大部分工作都在深度学习中完成,关系抽取也不例外,当深度学习方法大幅优于传统方法时,深度学习理所当然的成为研究热点。在关系抽取中,卷积神经网络(convolutional neural networks, CNN)肩负着主要任务。
2014年Zeng将CNN引入关系抽取中,也将position encoding(PE)引入其中。并在2015年提出PCNN(piecewise CNN)。所谓PCNN即是对CNN在关系抽取任务上的改进。CNN作为特征提取器在各个领域中都非常常用且成功,在关系制取过程中,作者认为在CNN之后的max-pooling层对整个卷积层的输出进行操作,不够精细,而且对关系与实体的结构提取的效率不高,因此,提出max-pooling层不再对整个卷积层输出进行处理,而是把每个卷积核输出的结果分成三段,分别进行max-pooling操作。分段规则是根据两个实体的位置,在两个实体位置处切成三段:
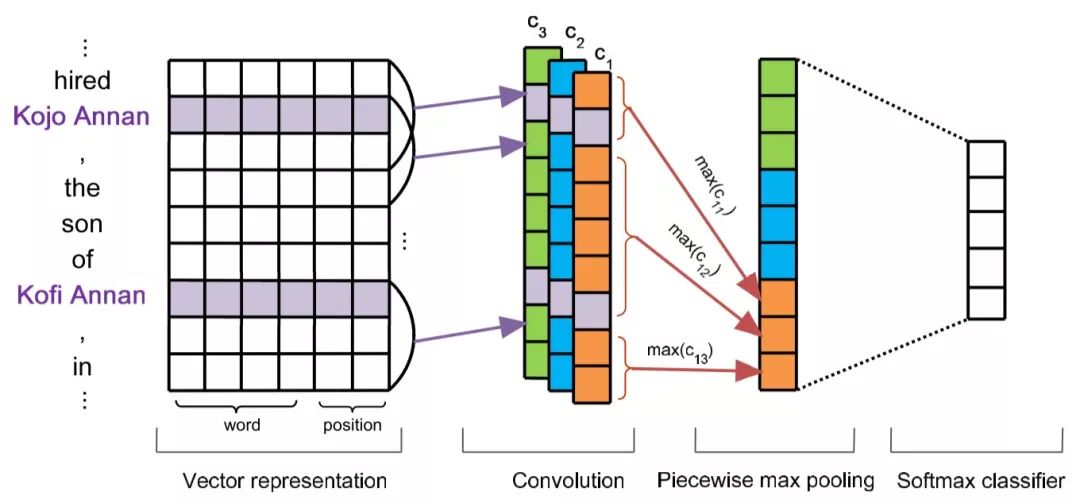
而且作者对目标函数进行了优化,不再使用整个bag作为更新依据,因为每个bag中都是有噪声的,而且很多bag中的噪声示例远远多于正确示例。而是在训练过程中,对依据softmax对每个bag中的示例进行条件概率评估,即每个示例能正确预测出bag标签的概率。然后只选择其中概率最大的示例作为参数更新依据。这个方式的好处是很大程度上遏制噪声对模型参数的影响。PCNN一经提出,PCNN的分切max-pooling思想就成为后续关系抽取模型的基本要素之一,对关系抽取的意义重大。
不过,缺点也非常明显,就是其数据的利用效率过低,一个bag中只有一个示例参与模型参数更新,而其他示例基本上在浪费计算资源,非常的不环保。于是有多篇文献对此提出改善方法。
Lin等人在2016年毫无意外地将attention 机制引入关系抽取中,attention机制在自然语言处理中已然成为基本模块。Lin引入attention 机制是对噪声数据进行建模。Zeng在PCNN中,每个bag只有一个示例被真正利用,造成资源浪费,Lin使用attention将每个bag中的所有示例利用起来,依据attention为每个示例赋予权重,可信的示例得到较大的权重,对参数的更新贡献就大,反之,可信度低的数据因其权重较小,对参数更新贡献小,即使其为噪声数据,对结果的影响也会很小。具体地,每个示例(embedding vector)经过PCNN得到一个新的向量,此向量作为attention机制的输入,attention机制在每个bag中发挥作用:

其中 M为关系矩阵,而d为偏置。
Jiang等人在2016提出另外一种解决数据利用率过低的情况,称为多示例多标签CNN(multi-instance multi-label CNN, MIML CNN). 同样的在使用PCNN后,不是对bag中所有的示例进行attention操作,而是转而采取一种称为cross-sentence max-pooling 的方式:
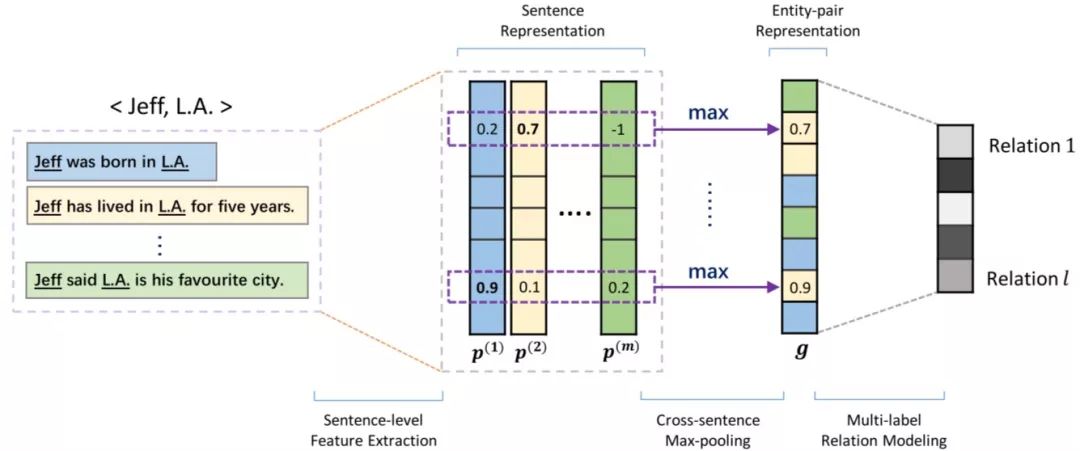
如上图所示,当一个bag中的所有示例都进行PCNN的特征提取操作得到特征向量后,将所有的向量排成一行,形成一个矩阵,然后,对这个特征矩阵按行最行max-pooling操作,得到这个bag的特征向量。作者这样的原因是,他同样认为每次更新只有一个示例在浪费,于是修改了Zeng的EALO假设:
一个实体对的关系可以被明确表达,也可以从所有提到的数据中推测出来。即作者认为根据所有提及实体对的数据人们或模型可以推测出其之间的某种关系。而这种推理则由cross-sentence max-pooling 来完成。不止于此,作者发现在常用的数据集中,18%以上的数据有重叠的关系,即一个实体对有多个关系。而这个在之前的远程监督是无法解决的。作者改变了最后的softmax层,将前一层的输出传给多个logistic function,每个logistic function为每个种关系的存在与否作01判断。
2017 Luo等人从另一个角度来解决远程监督的噪声问题。
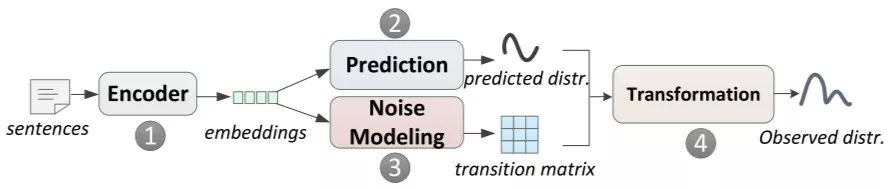
首先,同样地,每个示例都要经过PCNN或CNN的特征提取器;然后,示例的特征向量输入到predictor来预测关系的概率分布,并且同时输入到噪声建模模块,产生转移概率矩阵。而转移概率矩阵也是经过softmax来得到的:

其中 p 为predictor输出的关系分布, 其中o随后要做归一化。这样最后的损失函数需要加T的迹(Trace)作为正则项。直觉上,当数据很干净时,T几乎是一个对角阵,那么迹相应的就大,反之迹相应的就小。于是,损失函数应该减去示例转移概率矩阵的迹。另外作者在训练过程引入课程学习(curriculum learning)来提高转移概率矩阵的训练效率。
2018年Zeng等人,直接引入强化学习,将每个bag作为一个episode, 将关系作为action,将sentence作为state, reward则是命中正确关系与否,命中为1,反之为0,最终每个bag的reward为其内所示例的reward之和
Feng提出的强化学习模型分为两个模块,一个是instance selector,另一个是relation classifier, instance selector从bag中选择高质量示例,然后再预测每个示例的关系。state为当前示例及之前所有所选示例,而action则为是选择某一示例,而Reword则在处理过完某个bag之后,所有之前示例的预测对数概率之和。
Qin 等人在2018年基于强化学习提出一个新去噪方式:动态选择策略,即对每个示例进行判断其是否是正例,如果是,将其保留,否则将其放入负例的bag中。作者将当前示例与之前被移入负例bag中的示例作为state,而将是否保留作为动作,而将模型的表现作为Rewards。作者声称,他们的模型可以作为模型块加入到任何模型当中以提高模型表现。
Takanobu基于强化学习的层级关系抽取模型来解决重叠关系问题与共现噪声问题,本文提出的是一种联合学习的方式,即不但发现关系而且还要抽取实体。而且他们是先发现关系再发现实体,即认为,实体对是关系的参数。




