案例分享 | 悦耳为君:使用机器学习对 Spotify 主页面进行个性化设置

文 / Spotify Engineering
机器学习是我们在 Spotify 所做一切的核心所在。特别是在 Spotify 的主页面上,它使我们能够提供个性化的用户体验,并为数十亿粉丝提供欣赏艺术家作品并从中获得启发的机会。这就是 Spotify 的独到之处。
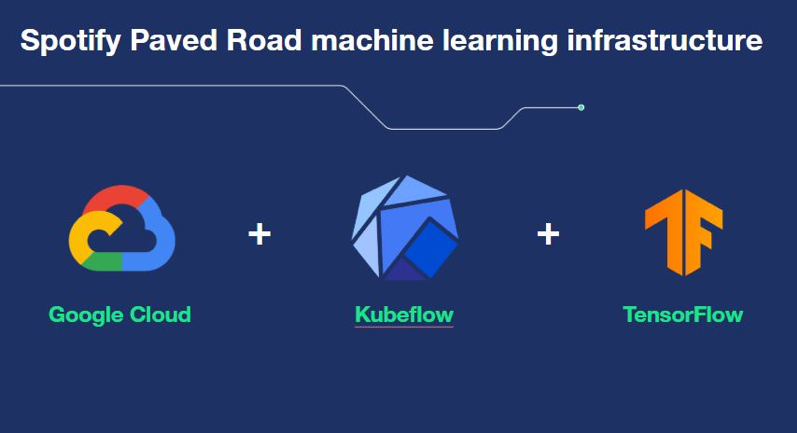
在我们的工程部门,我们正在努力联合自主团队,通过建立工具和方法上的最佳实践来提升工作效率。我们最近采用的标准化机器学习基础架构为我们的工程师提供了能够快速创建和迭代模型的环境和工具。我们称其为 “铺平道路” 方法,其中包括利用 TensorFlow,Kubeflow 和 Google Cloud Platform 的服务。
加入 Spotify 之前,我曾在 Netflix 从事个性化算法和主页面内容的工作。我以前的经验与现在我在 Spotify 担任工程副总裁兼机器学习负责人的工作非常相似。但是,个性化 Spotify 的主页面会带来一系列新的挑战,我将稍后分享。
机器学习使我们能够推荐艺术家,歌单和播客,从而使用户变得更佳活跃并更有可能长期订阅。理论上这些都很棒,但是怎样能使我们比竞争对手做得更好呢?毕竟,我们并不是唯一一家试图构建定制化着陆页,以其独特价值吸引用户的内容流媒体平台。

Spotify 的主页面
答案:个性化的力量
与 Netflix 一样,我们使用一系列的卡片和架子来组织主页面。卡片是用来展示歌单,播客,专辑,艺术家页面等内容的方形图像。架子是用来将这些卡片打包并排成一行。您可以将它想象为一个书橱(Spotify 主页面)在使用书架(架子)来保存和展示图书(卡片)。
以此类推,每个人的书架都会根据他们的兴趣和阅读历史来进行特别的布置。但是,与实体书架不同,Spotify 使用机器学习根据用户之前喜欢或可能喜欢的内容来个性化架子和卡片,并向数百万用户个性化地展示。
我们将机器学习与用户的数据相结合,包括他们的播放历史、音乐口味、播放时长以及他们对推荐内容的喜好程度。这样的结合使得我们拥有了高级别的个性化能力,能够实时创建个性化主页面满足多达 2.48 亿月活跃用户 (MAU, Monthly Active Users) 的需求。我们要说的是,并没有“一个”真正的 Spotify。实质上,该产品有 2.48 亿个版本,每个用户都在使用专属于他们的独特版本!
卡片和架子
参与度与基于研究的推荐
从机器学习的角度来看,我们使用 Multi-Armed Bandit 作为框架解决利用与探索的难题。在工程领域之外,“利用”可能具有负面含义。但是,在制造个性化内容体验的推荐系统中,“利用”表示应用程序会根据用户先前选择的音乐或播客提供推荐内容。“探索”通过推荐未知内容,根据用户与推荐内容的互动反馈以进一步了解用户的喜好。“利用”与“探索”大不相同,后者基于不确定的用户参与度,并且更多的被用作研究工具。这种平衡框架确保我们在面对无论是新用户还是老用户都能实现个性化设置。我们还采用反事实训练和推理来评估我们的算法,而无需 A/B 测试或随机实验。
利用与探索
https://dl.acm.org/doi/10.1145/3240323.3240354
借助来自用户的数据,我们得以呈现您喜欢的内容,这些数据包括最近播放的专辑,反复播放的曲目和订阅的播客等。同时,我们会根据收听历史记录推荐新的曲目和艺术家。这些曲目打包成歌单的形式,例如歌单“更加喜欢”,“为您推荐”和“为您定制”。尽管主界面看起来自然且连续,但是您看到的几乎所有内容都是由“利用与探索” (Exploitation and Exploration) 方法生成的。
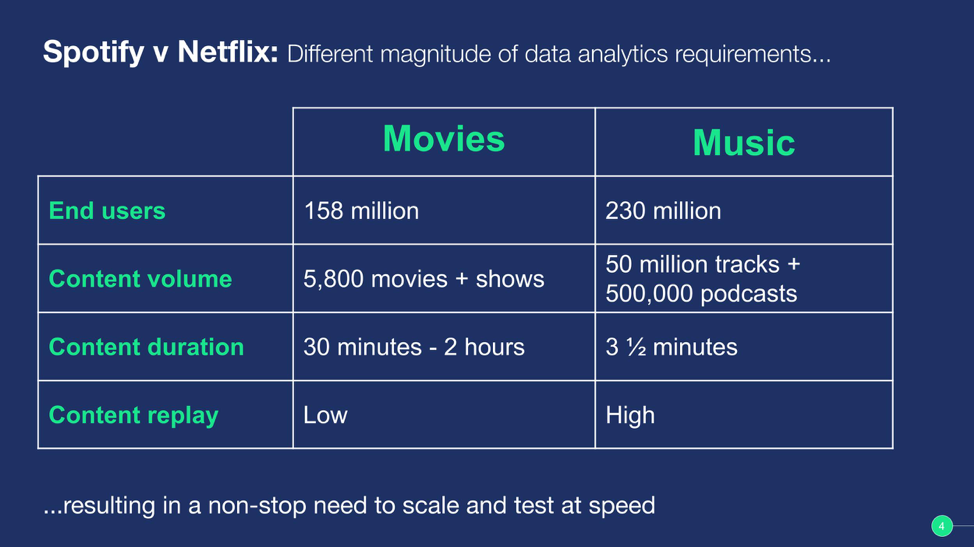
当然,只有在不间断地使用大量数据进行实验时,此方法才有效。为了让您直观地感受到规模上的差别,我们再次将 Spotify 主页面与 Netflix 的主页面进行比较。两个主页面都有相似的设置和挑战,对吗?不完全对。最大的区别在于用户和内容数据的规模大小,随之而来的便是我们必须扩展机器学习的规模以匹配如此大规模的需求。
数字说明了一切。Netflix 拥有约 1.58 亿用户,在 Spotify,我们有 2.48 亿用户。最重要的是,Netflix 在所有地区共计拥有约 5,800 部电影和节目,而 Spotify 却拥有超过 5,000 万首音乐曲目和 500,000 个播客电台。
还要注意的是,单集 Netflix 的内容的时长是从半小时(类似于情景喜剧)到长达几个小时(电影)。而 Spotify 上面的一支曲目的典型时长大概是三分半钟。考虑到需要索引的内容数据的频率和数量,这会导致在规模上的巨大差异。
结果呢?就是我们需要一个高度可扩展的环境,让我们可以运行大量、不间断的实时实验,从而使我们能够更好地利用我们的数据,为听众提供出色的体验。
从脆弱到牢不可破
在 Spotify 成立之初,我们编写了许多自定义资料库和 API,以推动我们的个性化工作背后的机器学习算法。这向机器学习团队提出了一些挑战。在尝试扩展我们的机器学习实践时,支持多个系统对于我们的工程师而言并不是理想的维护方式,并且与我们当前为提高工程师生产力所做的努力不符。
例如,我们需要研究 Multi-Armed Bandit 框架下的不同学习模型,包括逻辑回归,提升树 (Boosted Tree) 和更复杂的模型,如最新的深度神经网络体系结构。我们一直在不断重写代码,以使系统的各部分保持一致。完成一项实验后,留给我们的是一个有隐患而脆弱的系统,扩展性也很差,还需要在快速的生产环境中支持多个框架。在这种环境下是很难进行迭代和创新的。
这就是为什么我们转向标准化机器学习基础架构如此宝贵和及时的原因。TensorFlow Estimators 和 Tensorflow Data Validation 帮助我们最大程度地减少许多以前需要人工自定义的工作量。借助 TensorFlow Estimators,我们可以比以前更快地训练和评估模型,从而大大加快了迭代过程。
此外,迁移到 Kubeflow 非常有价值,因为它帮助我们更好地管理工作负载,并加快实验和产出 (Roll out) 的速度。现在,更快的自动训练显著加速了我们的机器学习算法的训练过程。
使用 Tensorflow Data Validation,我们无论在开发过程中还是在评估和产出期间均可以发现数据流水线和机器流水线中的错误。现在,借助仪表板,我们可以快速观察到流水线中存在的任何数据缺失或不一致之处,这要归功于仪表板所绘制的不同数据集上的要素和计数的分布图。
在一种情况下,我们看到训练数据中缺少付费会员的样本,而评估流程中缺少了免费用户的数据样本。从机器学习的角度来看,丢掉这些有价值的数据集是很可怕的,所幸我们可以用 TFDV 快速捕获它。更棒的是,我们还可以配置仪表板针对特定阈值触发警报,因此我们的工程师不必担心数据流水线的错误会流入系统。
架构升级带飞研发
为用户创建个性化主页的体验代价不菲。以前,我们的工程师花费大量时间来维护数据和后端系统。后来我们使用前文提到的工具(TensorFlow Extended、Kubeflow 和 Google Cloud Platform 生态系统)对我们的 ML 基础架构进行标准化。ML 架构标准化让我们在工程实践和生产力方面有了更好的理解。我们新近建立的最佳实践有一个显著优势,即它可以帮助我们在短期内大大提高用户满意度(对比基于流行度的基线)。
话虽如此,我们的实践只是初出茅庐。我们决定继续研究如何掌控机器学习与 AI 的力量,为我们的用户提供更加个性化的体验。
投资技术就是投资工程师
我们对这些技术的投资也是对机器学习工程师及其生产力的投资。我们希望我们的工程师专注于创新,并在 Spotify 推动机器学习的发展,而不是参与耗时的基础架构维护工作。我们的工程文化围绕着尽可能高产和高效的原则来帮助我们继续扩展平台,同时也为创作者和消费者创造了良好的用户体验。
定制 Spotify 主页面只是 Spotify 个性化的冰山一角。机器学习是一个令人兴奋的创新领域,我们仍在不断努力解决创建个性化体验方面的挑战。如果您有兴趣帮助我们解决机器学习工程方面的挑战,欢迎查看招聘职位并加入我们的团队。
招聘职位
https://www.spotifyjobs.com/
如果您想在 TensorFlow 社区分享经验与用例,点击 “阅读原文” 填写相关信息,我们会尽快与您联系。




