Spotify揭秘:如何用算法实现歌曲精准推送
Spotify是全球最大的正版流媒体音乐服务商,虽然因为某些原因暂未进入大陆市场,但是其用户已达1.4亿以上。它的使用模式与我们熟知的XX音乐、XX云音乐类似,可免费在线收听正版音乐,但不能下载。这种音乐服务方式收到了全球几十个国家用户的喜爱。
本文作者Sophia Ciocca是Spotify的忠实用户,她最喜欢的功能就是“每周歌曲推荐”。每周一,Spotify会根据用户最近听歌的偏好对其推荐30首歌曲,Sophia认为:“这让我有一种’被看到’的感觉,Spotify比我生活中的任何一个人都要了解我的音乐口味。”
有这种感觉得不止Sophia一人,Twitter上就有许多用户对Spotify这一精准推荐给与莫大的好评。而公司也注意到了这一点,他们在音乐推荐算法上也投入了更多资源。所以,Spotify到底是如何做到每周给用户推荐30首“最合口味”的歌曲的呢?在正式研究开始前,让我们先看看其他音乐服务商的模式,再与Spotify形成对比。
在线音乐服务的发展历程

早在本世纪初,Songza就利用手动推荐推出而在线音乐精选的界面,创建个性化的音乐播放列表。“手动推荐”的意思是,一些“音乐专家”或管理团队会用人工将他们认为不错的音乐放在一起,让观众只听他们制作出的播放列表。这种方法虽然有效,但是由于它是简单地手工组合,因此不能考虑到每位听众的个性化口味。
和Songza一样,Pandora也是音乐精选推荐的最早玩家之一。它采用了稍微高级的方法:让一群人在听音乐的同时,为每首曲目选择一组描述性的词语,然后为每首曲目打标签。然后,Pandora的代码可以简单地过滤某些标签,以推荐类似的音乐播放列表。
与此同时,MIT媒体实验室推出了一款名为“回声巢”(The Echo Nest)的音乐信息处理器,它生成个性化音乐的方法更先进。Echo Nest使用算法分析音乐的音频和文本内容,使其能够识别音乐,执行个性化推荐,创建播放列表并分析。
最后,Last.fm采取了另一种方法,称为协同过滤(collaborative filtering)来识别用户可能喜欢的音乐。Last.fm至今仍然存在。
既然已有这么多音乐公司为精准推荐做了努力了,Spotify的方法究竟与其他方法有何不同,在哪里更胜一筹呢?
Spotify的三种推荐模式
实际上,Spotify并不只用一种创新的推荐模式,而是将其他服务商的最佳方法混合在一起,创建出了自己独特而强大的推荐引擎。
要生成“每周音乐推荐”,Spotify使用三种模型:
协同过滤模型,即Last.fm最初使用的模型,通过分析你的行为和其他用户的行为工作;
自然语言处理(NLP)模型,通过文本分析工作;
音频模型,通过分析原始音轨工作。
接下来,让我们一个一个来研究一下!
协同过滤模型
首先,先了解一下背景知识。很多人听到“协同过滤”这个词的时候,会想到Netflix,因为它是最初使用协同过滤算法来加强用户推荐的公司之一。他们通过用户对电影的星级评分决定给“相似”用户推荐什么电影。
随着Netflix使用成功,协同过滤模型被广泛应用。到目前,如果有人想做推荐算法,首先要考虑的就是协同过滤。

与Netflix不同的是,Spotify没有让用户为歌曲打分的功能。相反,Spotify的数据是私密的,数据流记录下我们收听的曲目以及额外的流数据,比如用户是否将该曲目添加到自己的播放列表中,或者是否在收听后访问了歌手的主页。
但到底什么是协同过滤?它是如何工作的?下面的对话就大致为我们描述了一下:

可以看到,左边的人喜欢歌曲P、Q、R、S,右边的人喜欢Q、R、S、T。然后协同过滤会默默地说:
嗯……你们有三首共同喜欢的曲目:Q、R、S,所以你们可能口味相近。因此,你们可能会喜欢别人听过的歌曲,但你们从未听过。
所以,左边的人可能会去听一下T,而右边的人会试着听一下P。很简单对吧?
但是,Spotify要想把这一概念用于数以百万的用户,该怎么实现呢?
答案是,矩阵加Python库!
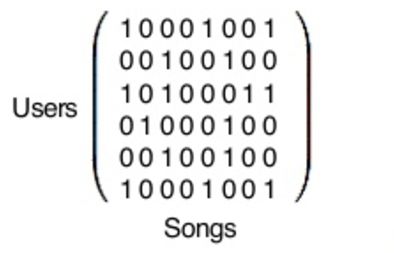
其实这个矩阵非常非常大,每行代表1.4亿用户中的一位,每列代表Spotify数据库中3000万首歌曲之一。
然后,在Python库中运行这个长且复杂的矩阵分解公式:
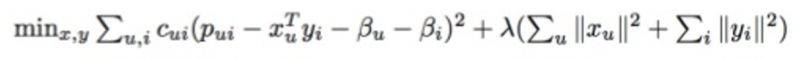
完成之后,我们最终会得到两种类型的向量,分别用X和Y表示。X是用户向量,代表一个用户的喜好,Y是歌曲向量,代表单首歌曲的信息。现在我们拥有了1.4亿用户向量以及3000万歌曲向量。这些向量实际上只是一堆没有意义的数字,但是当它们进行比较时就非常有用。
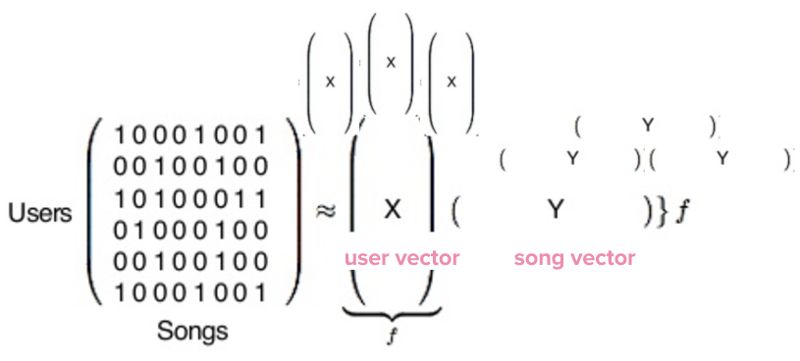
为了找到哪些用户的音乐偏好与我类似,协同过滤将我的向量与其他用户进行比较,最终向我展示与我最相似的用户。Y向量也是如此。
协同过滤的效果相当不错,但是Spotify认为加入另一个工具,他们能做的更好。那就是NLP。
自然语言处理(NLP)
Spotify第二种音乐推荐方法是利用自然语言处理模型。模型的源数据都是常规的在线词语:互联网上的元数据、新闻文章、博客以及其他文本。

自然语言处理,即让计算机理解人类语言的能力,本身就是一个宽泛的领域,通常通过情感文本分析来获得结果。
本文不讨论NLP背后的详细机制,Spotify应用的是一个更高水平:Spotify不断在网页上查找人们关于音乐的博文或评价,找出人们对某些歌手或歌曲的评价,他们经常用什么形容词或语言评价这些歌曲,是否有与这些歌曲相比较的其他歌曲或歌手等等。
虽然我不知道Spotify具体怎样处理他们的数据,但我知道Echo Nest处理数据的方法。他们会把数据分为cultural vectors或top terms。每位歌手和每首歌曲每天都有数千条变化的top terms。每个term都有一个相关的权重,这说明了描述的重要性。
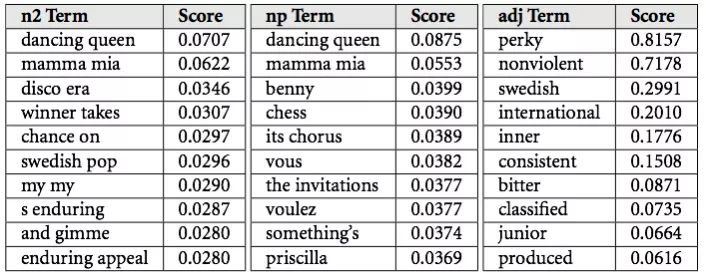
然后,与协同过滤形似,NLP模型使用这些terms和权重来创建歌曲的向量表示,然后判断两首音乐是否相似。酷吧?😎
原始音频模型
看到标题,你可能会问:前两种方法已经得到很多数据了,为什么还要分析音频本身?
首先,引入第三种模型毫无疑问会让推荐结果更精确。但是除此之外,这一模型还有另一个作用:与前两种模型不同,原始音频分析考虑了新歌。
比如,你有一位创作型歌手朋友,他的歌曲发布到Spotify后只播放了50次,所以能被协同过滤的机会很小。同样,互联网上也很少有这首歌的身影,没人提起过它,所以NLP模型也不好使了。幸运的是,还有原始音频模型啊!它可不会将流行曲目和新曲目区别对待。所以有了它,新发布的歌曲也有机会出现在“每周歌曲推荐”的列表上。
好了,那么现在的问题是,怎么分析这抽象的原始音频数据呢?
当然是用卷积神经网络啦!
CNN常用的场景是面部识别。不过在Spotify里,他们将像素换成了音频。下面是一个神经网络架构的例子:
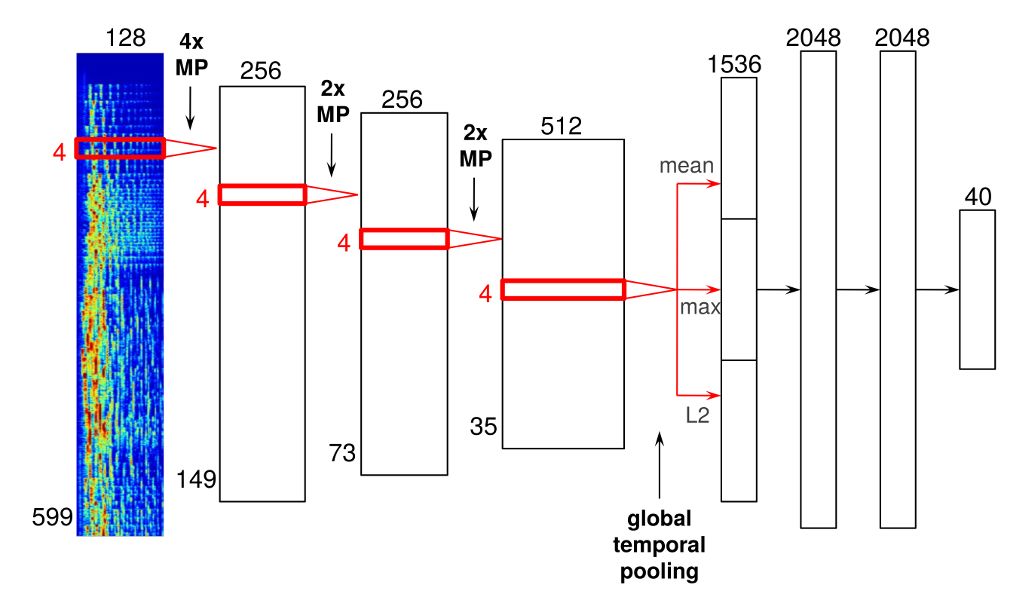
这一神经网络有四个卷积层,输入的是音频帧的时频表示,然后将其连接形成声谱图。
音频帧通过这些卷积层后,你可以看到一个“全局时域池化层”(global temporal pooling layer),它在整个时间轴上集中资源,有效地计算在一首歌的时间内所学特征的数据。
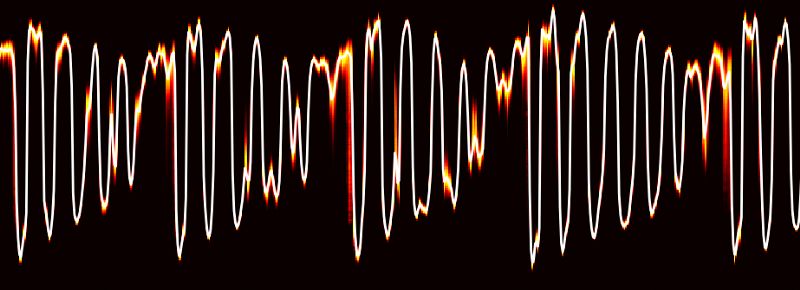
经过处理后,神经网络生成对歌曲的理解信息,包括这首歌的拍号、音调、调式、节拍、响度等。下图是从Daft Punk的歌曲《Around the World》中截取的30秒片段。
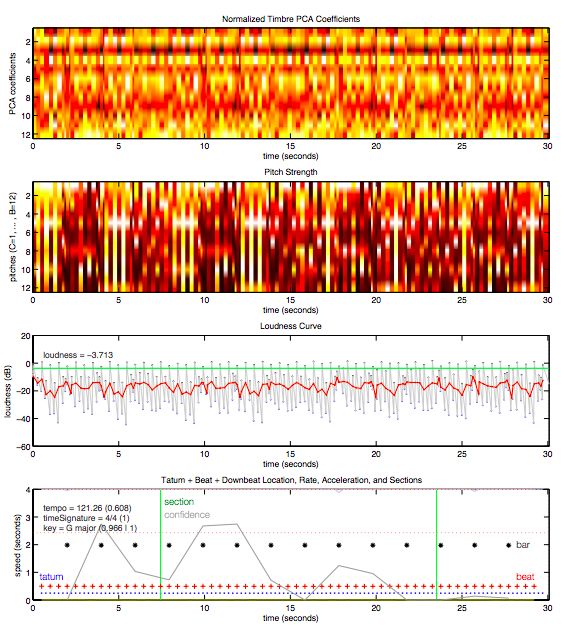
最终,对歌曲关键特征的把握使Spotify能够了解歌曲之间的相似性,从而根据用户的收听记录判断他们会喜欢哪些歌曲。
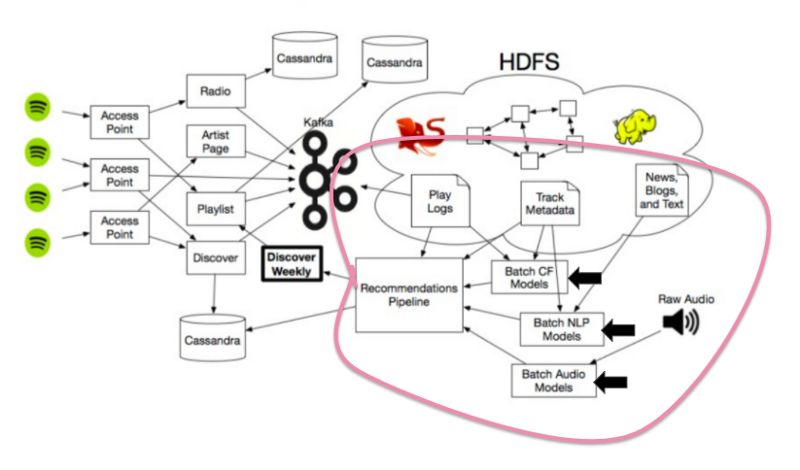
以上就是Spotify音乐推荐的三种模式,当然,这些模式都与Spotify更广泛的生态系统相连,其中包括大量的数据存储以及使用大量Hadoop集群来扩大推荐范围。
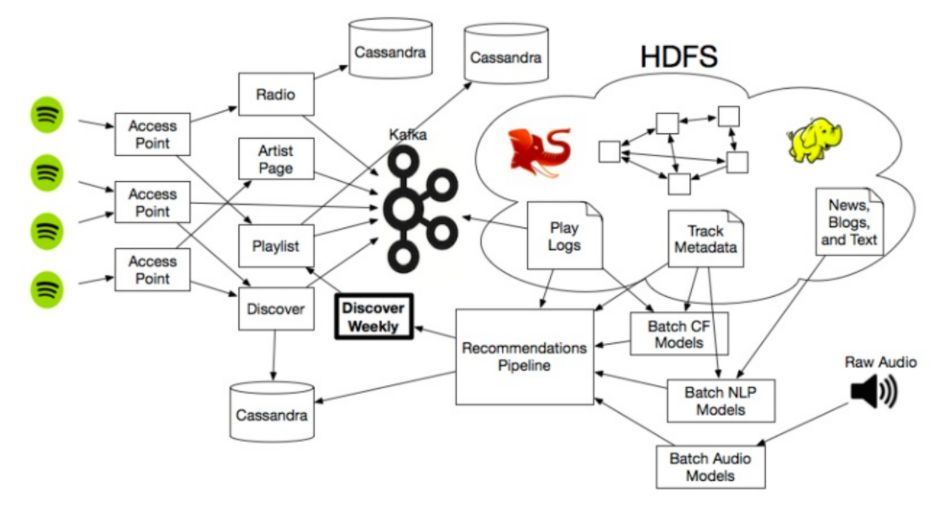
其实,国内类似的音乐软件实现的推荐功能与Spotify的原理相差不大,有兴趣的同学可自行查资料研究,希望本文的信息能满足你的好奇心。
原文地址:hackernoon.com/spotifys-discover-weekly-how-machine-learning-finds-your-new-music-19a41ab76efe







