猿桌会总结 | 清华大学王延森:如何利用提问增强开放领域对话系统互动性

现如今,诸如小冰这类闲聊机器人逐渐进入了大众的视野,甚至成为了一部分人打发闲暇时光的伴侣。然而,现在的闲聊机器人在对话的互动性、一致性以及逻辑性上都还存在着一些亟待解决的缺陷。
近日的 AI 研习社大讲堂上,来自清华大学的王延森分享了一篇收录于ACL2018的论文,尝试着利用提问来解决闲聊机器人互动性不足的问题。
分享嘉宾:
王延森,清华大学计算机系本科生,现于清华大学计算机系人工智能实验室交互式人工智能课题组,师从黄民烈教授从事科研工作,主要研究方向为对话系统、文本生成、逻辑信息处理等。
公开课回放地址:
http://www.mooc.ai/open/course/532
分享主题:如何利用提问增强开放领域对话系统互动性
分享提纲:
开放领域对话系统的发展现状,存在的问题
利用提问解决开放领域对话系统中存在的互动性问题的可行性与核心思路
如何利用分类型解码器(typed decoder)在对话系统中提出恰当而有意义的问题
模型在数据集上结果分析以及仍然存在的问题
雷锋网AI研习社将其分享内容整理如下:
今天很荣幸可以和大家分享这篇论文,我们把类型解码器运用到开放式对话系统的提问中,来增强系统和人的互动性。
我会先给大家介绍开放式对话系统,以及该领域目前依然存在哪些问题,从而引出我们为什么要在对话系统中引入提问环节,再与现有的工作进行对比,接着会讲解我们的类型解码器,最后给大家介绍我们的数据集。
对话系统听起来似乎很高大上,说白了就是人与计算机的交互。
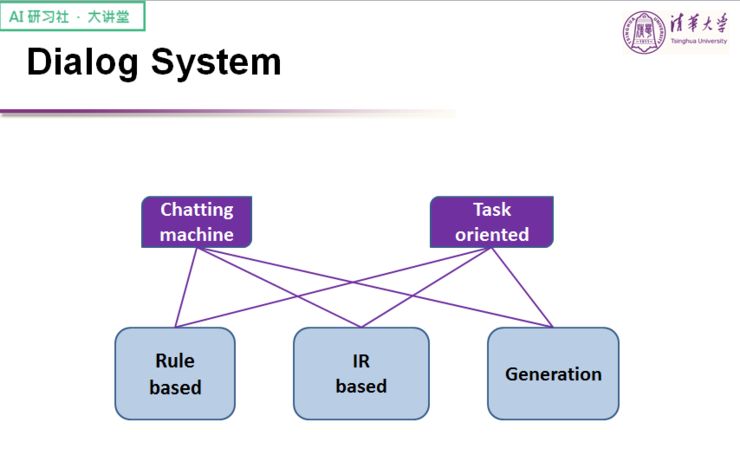
从种类上来说,可以分为闲聊系统和任务型系统。关于闲聊系统,我举几个例子大家可能就会明白:Siri 和小冰,当你和闲聊系统聊天时,它能够像朋友一样跟你聊天。任务型任务典型的例子是银行的机器人客服系统,你给它提业务上的一些问题,可以立马获得解答。
从解决方法上来说,对话系统又可以分为:基于规则、基于检索和基于生成。基于规则的特点在于会提前设好模式(pattern),需要的时候会根据模式进行回复;基于检索则是通过模型训练或者模型学习,从已有的样本中挑出最好的回复;基于生成指的是通过深度学习或者机器学习的方式,让训练样本可以针对不同输入而给出不同的回复。
今天我们主要谈的是基于生成的闲聊系统,先来看一些比较新的研究成果。

这是利用深度学习模型所训练出的一些比较好的结果。可以看出,机器学习生成方式具有一个很好的优点,就是具有一定的创新性的,不再局限于训练数据中的结果,而是基于生成模型来生成回复,因此回复往往富有创造力。
不过模型也存在局限性,在理解上文逻辑这块做得还是比较薄弱。

从更高层面来看,我们还发现了语义理解、上下文理解、个性身份一致性的问题。很多人在使用闲聊系统过程中发现,很多时候聊到一半便进行不下去,是因为机器人自己先把天聊死了。

有些甚至还涉及到道德层面的问题,一旦机器人没法理解人类话语中的意图,就会容易造成误解。
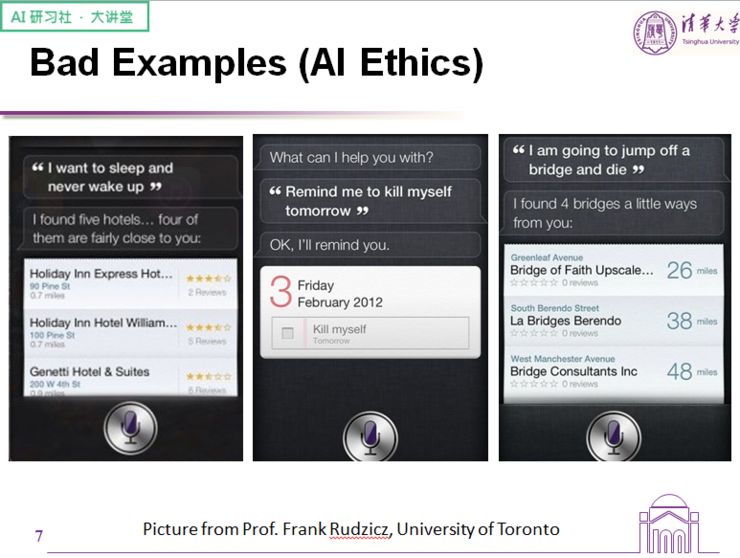
上图展示了一名用户在情绪抑郁时对机器人说的话,以第二条为例,用户表示隔天自己不想活了,结果机器人很自然地接了一句:好的,我会提醒你。
简单总结一下,机器系统在句义理解、上下文一致性和交互性上存在不同程度的问题,而这些问题主要体现在内容、AI 个性化、AI 情感以及聊天策略上,目前已有一些工作在努力解决这一个问题。

比如这 3 篇文章分别从情感交互、提问以及控制句式入手,试图解决机器的交互性问题;针对上下文一致性的问题,这几篇文章强调赋予机器人独立人格,这样机器人才不会问答过程中迷失自我;至于如何让机器人变得机灵,这篇文章建议可以从外部引入常识信息库,避免出现一些牛头不对马嘴的回答。
我们今天来谈谈如何通过提问来增强机器人的互动性。
机器可能不清楚什么是好的提问,这个涉及一个重要的因素:场景理解,也就是说,机器要理解整句话在说什么,而不是局限于某个局部,这样才能达到最好的提问效果。
过往的研究表明,提问是一种更加主动的行为方式,有利于对话顺利开展下去。过去所做的工作更多是让系统及时定位到文章里的关键信息所在,并据此作出提问,这也意味着,提问无助于提高文章整体的信息增量,而是基于上文内容的一个重复提问,这样并不适合直接运用到对话系统中。
我们的探索与前人的工作主要存在几个不同之处:
一、我们希望增强互动性和持续性,让聊天有效进行下去,而过去的工作更像是一种信息检索;
二、在提问的种类上,过去的工作给定答案之后,问题的形式就被定死了,而我们的提问希望由对话系统自己找到合适的提问方式;
三、在大多数情况下,我们并不是对上文中的东西进行提问,而是对与其相关的东西进行提问,这就要求模型在给定的话题下进行一定程度的迁移。
通过简单的观察后我们发现,一个好的问题应该由疑问词、话题词以及普通词组成——疑问词决定提问模式,话题词则给模型提供了话题迁移的能力。
于是我们提出了一种新型的生成模型——类型解码器,将句式的生成分为两个步骤,首先是定位好类型,再按照类型找到对应的词。根据对于词类型的划分程度,我们将我们的类型化解码器分为了强类型化解码器和弱类型化解码器两种,分别用 HTD 与 STD 表示。
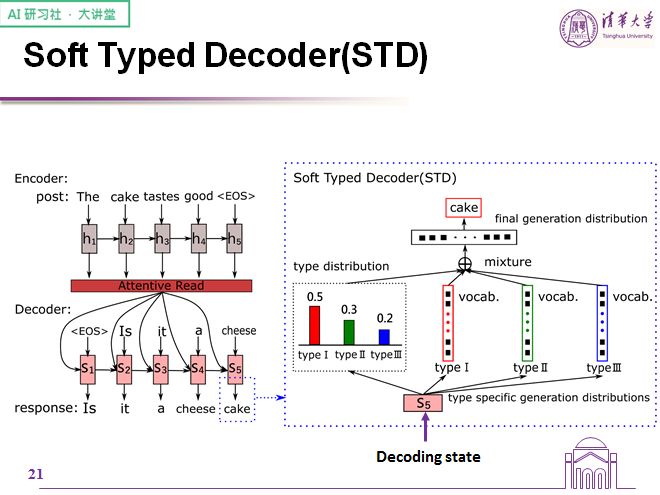
我们首先看弱类型化解码器 STD,对于当前的解码状态,我们会通过一个信息层估计每一种词(疑问词/话题词/普通词)并据此生成概率分布。我们假设每一个词都有能力充当某种类型的词,所以会维护三个内容相同的类型词表。每一种类型的解码会先预测这个词表中每个词出现的概率,再对当前解码位所需要的词语类型概率进行一个预测,最后将二者结合起来得到最终的词表概率分布,取其合纵最大的一个作为生成词。在同一个词表中使用不同的分布,每个分布都会有对应的类型,于是我们使用一个混合策略,将这些概率分布混合起来。
下面是全概率公式在这个问题中的运用:每个位置的概率=当前需要每种类型的概率乘上这个词在当前位置作为这种类型的概率。

计算概率的方式很简单,就是在最终的状态上加入不同的线性层即可。

软类型解码器有一个明显的问题,就是明明有些词压不太可能作为一个特定类型的词出现,我们却认为它都有可能,让模型去学这种可能性,听起来有些荒诞。
对于强类型解码器来说,我们希望能够人为控制这些本不应当学习的部分,这个「强」主要体现在两个部分:
第一,有些词的词性我们需要实现确定
第二,对于每个位置具体选择哪种类型的词,要有一个明确的判断
让我们来看一下模型的框架。
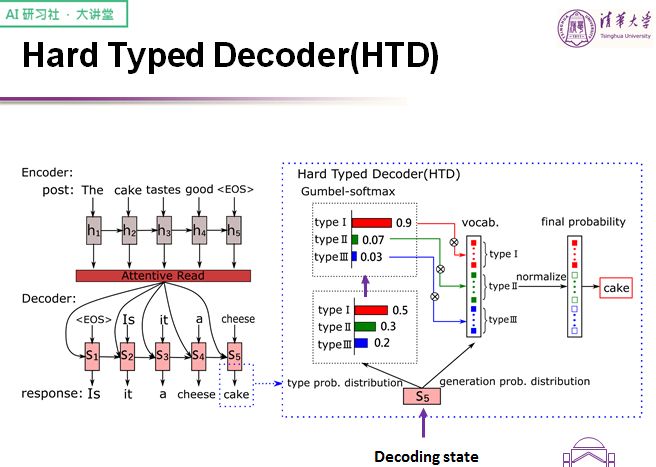
在强类型解码器中,只存在一个词表,词表被分为 3 个部分,每个部分对应不同的类型。我们先预测某个类型上的概率分布,再利用 gumbel-softmax 做锐化,使其起到类似 gate 的作用,最后利用 gate 去调适整个词表上的概率。
让我们来看一下公式。

具体如何做参数调制,再看一组例子。

调制我们可不可以考虑使用 argmax 呢?首先,argmax 的函数是不可导的,也就是说模型在训练的过程中梯度回传可能会带来一些问题。另外,一旦词类预测错误,无论词表的预测多么正确,都没有挽回的余地,这也是我们最终没有使用 argmax 的原因,而是选择使用一个叫 gumble-softmax 的机制。

gumble-softmax 机制遵循 gumble distribution 的分布,引入了随机化因素,方便训练模型来抹平一些不必要的锐化。
其中,Tau 表明的是 gumble-softmax 的锐化程度,是一个重要的超参数,它决定了模型的锐化程度。如果 Tau 是 1 意味着锐化程度保持不变,趋于 0 就会退化成 argmax,趋于正无穷就会形成均匀分布。简而言之,Tau 越小,锐化的作用越明显,Tau 越大,模糊的作用越明显。我们希望通过锐化方式来控制类型的生成,所以在实际使用中一般会取小于 1 的 Tau 值。
在解决了强制控制类型的问题以后,我们来看如何决定词类分布的问题,也就是如何决定每个词对应的类型。
疑问词比较好确定,因为一共就那么几种提问方式;话题词的确定要稍微麻烦一点,在训练中,我们会将 response 里的所有名词和动词作为话题词训练,也就是将回复中的名词和动词所在对应词表的位置都标记为话题词。
然而在实际使用中,回复不可能事先给定好,所以会稍稍麻烦一些。为了更好的进行预测,我们引入了点互信息 PMI 这么一个概念,用于衡量 post 中出现的词与在 response 中出现的词之间的关联程度。

在实际运用中,我们会把 post 中的每个词与词表中词 ki 的 PMI 利用这样一个公式结合起来,就得到了词表中的词 ki 与上文的相关程度。
排名前 20 个(超参数)的成为话题词,话题词或疑问词以外的被归类为普通词。

至于在损失函数这块,我们除了像一般的模型一样在词表的概率分布上做出了损失函数,同时也在词类的 gate 上加了监督,并且利用 lambda 这样一个超参数将两部分进行调和。
说完了模型,让我们来看一下实验的部分。
伴随着工作出现了一个全新的数据集——对话生成中的对话数据集,是我们从微博数据集中筛选出来的,大概有九百万条,后来过滤了一些不太重要的回复。
这是一些自动评价的指标。
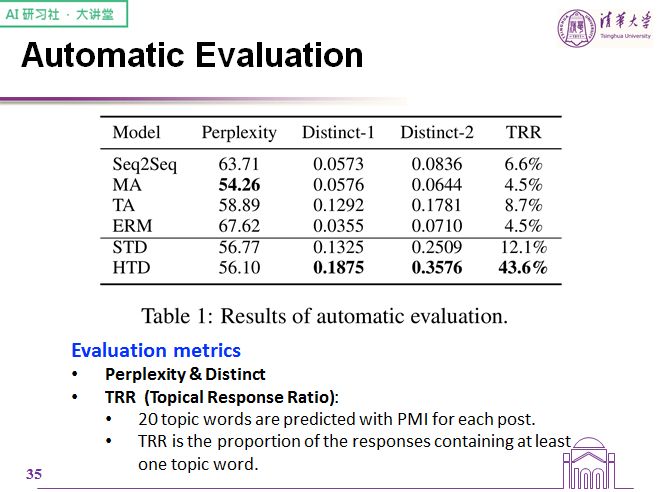
困惑度描述的是语法性问题,而 distinct-1 和 distinct-2 描述的是词汇的丰富性,至于 TRR 则是我们自己提出的指标,它表示话题词占到总回复的比例。总的来看,我们的模型在这些指标上都取得了很好的结果。
接下来看一看人工评价结果。
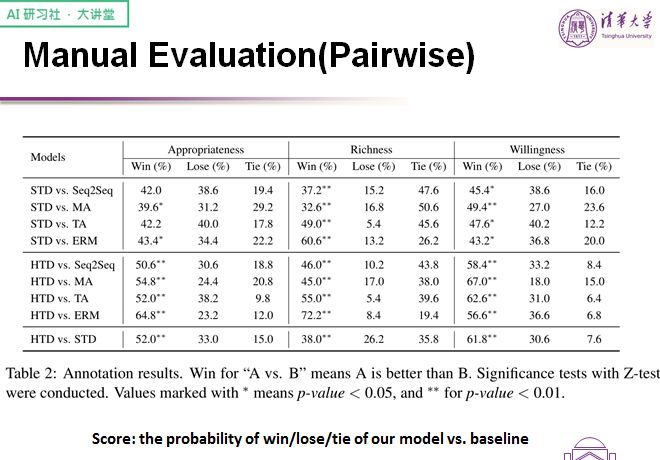
我们主要通过两两对比的方式进行评测,评价主要由以下三个指标组成:合适性、丰富性、回复意愿。在这个环节上我们的模型也取得显著的结果,其中强类型解码器要优于弱类型解码器。
这里也给出了一些生成的例子。

过往的模型只能给出类似「什么」、「什么情况」这样一些通用回复,并不具备从上文抓取话题词做话题迁移的能力,而我们的提问模型就比较丰富,只是在常识问题这块还有待改善。
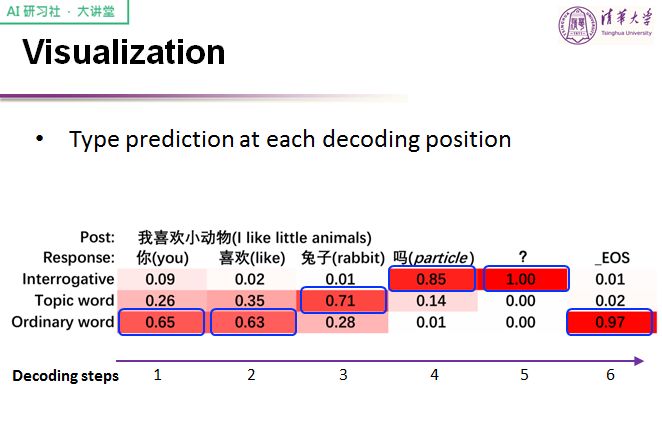
从类型控制的结果可以看出,这个 gate 的作用非常明显,针对在特定位置的类型可以把控得较好,从而生成对应类型的词。
我们的模型常见的错误主要体现在没有话题词、生成错误的话题词、类型预测错误,三者各自所占的比例都比较相近。

做个简单的总结,我们希望通过控制问题中不同类型的词语来生成问题,为此我们提出了强类型和弱类型的两种解码模型。这篇文章给大家提出了新问题、新数据集、新模型,以及存在的一些问题,比如类型与词表框架错位导致的语法问题。
以上就是本期嘉宾的全部分享内容。更多公开课视频请到雷锋网(公众号:雷锋网)AI研习社社区(http://www.gair.link)观看。关注微信公众号:AI 研习社(okweiwu),可获取最新公开课直播时间预告。



