AI产品需要了解的数据标注工作

而现在作者仍能负责公司的重点项目,证明了进入 AI 行业并不是想象中的那么困难。直至今天,作者仍在这条道路上不断学习。
本文就是作者从自己的经验出发,告诉各位读者,如何在对 AI 行业一无所知的情况下,快速了解到它的流程运作,并找准机会转行。
更多干货内容请关注微信公众号“AI 前线”(ID:ai-front)
首先要跟大家说明的是,AI 是一个领域,AI 的应用范围非常非常广,如下图
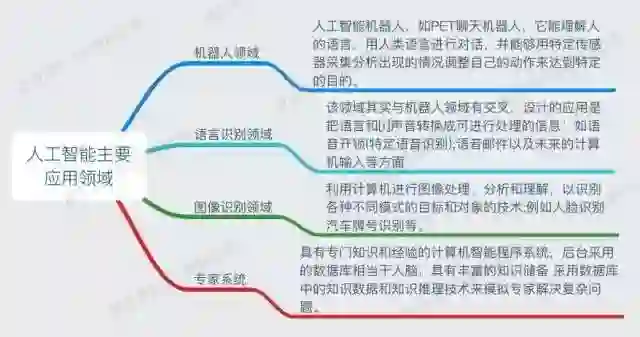
图 by@智能玩咖
图上每一个领域用到的算法都不一样,并且一个领域下面有很多的细分小领域。
比如语音识别,就包含了语音转文字、自然语言处理、文字转语音等等技术。而有很多想转型的产品,第一个考虑的点就是:不懂技术就做不了 AI,我是不是学完算法才能入行?
其实不是。
如果不是想立刻转型到算法相关的 AI 产品,其实在平台——工程——算法之间有一个可以渐渐过渡的过程。
大家可能都知道:
▶
对算法来说最重要的是数据, 足够量足够好的数据才能得到更优秀的算法模型。
▶
而关于数据其实可分为两种类型:被标记过的数据和未被标记过的数据。什么是标记呢?意同“贴标签”,当你看到一个西瓜,你知道它是属于水果。那么你就可以为它贴上一个水果的标签。算法同事用“有标签的数据”去训练模型,这里就有了“监督学习”。
重点就是这里:
只要是跟“监督学习”沾边的产品 / 技术,比如图像识别、人脸识别、自然语言理解等等,他们都有一个必走的流程
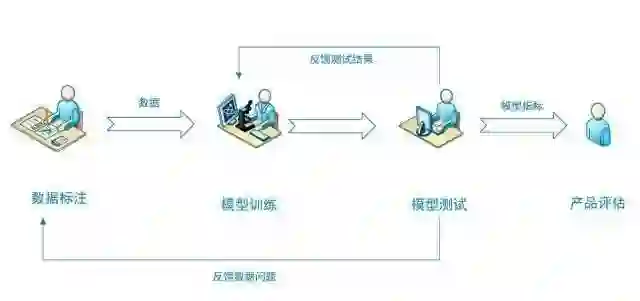
不断地用标注后的数据去训练模型,不断调整模型参数,得到指标数值更高的模型。
数据的质量直接回影响到模型的质量,因此数据标注在整个流程中绝对是非要重要的一点。一般来说数据标注部分可以有三个角色:
标注员:标注员负责标记数据。
审核员:审核员负责审核被标记数据的质量。
管理员:管理人员、发放任务、统计工资。
只有在数据被审核员审核通过后,这批数据才能够被算法同事利用。
1. 任务分配:假设标注员每次标记的数据为一次任务,则每次任务可由管理员分批发放记录,也可将整个流程做成“抢单式”的,由后台直接分发。
2. 标记程序设计:需要考虑到如何提升效率,比如快捷键的设置、边标记及边存等等功能都有利于提高标记效率。
3. 进度跟踪:程序对标注员、审核员的工作分别进行跟踪,可利用“规定截止日期”的方式淘汰怠惰的人。
4. 质量跟踪:通过计算标注人员的标注正确率和被审核通过率,对人员标注质量进行跟踪,可利用“末位淘汰”制提高标注人员质量。
这部分基本交由算法同事跟进,但产品可依据需求,向算法同事提出需要注意的方面;
举个栗子:
一个识别车辆的产品现在对大众车某系列的识别效果非常不理想,经过跟踪发现是因为该车系和另外一个品牌的车型十分相似。而本次数据标注主要针对大众车系的数据做了补充,也修改了大批以往的错误标注。(这两种为优化数据的基本方式)本次模型需要重点关注大众某车系的识别效果,至少将精确率提高 5%。
产品将具体的需求给到算法工程师,能避免无目的性、无针对性、无紧急程度的工作。
测试同事(一般来说算法同事也会直接负责模型测试)将未被训练过的数据在新的模型下做测试。
如果没有后台设计,测试结果只能由人工抽样计算,抽样计算繁琐且效率较低。因此可以考虑由后台计算。
一般来说模型测试至少需要关注 两个指标:
1. 精确率:识别为正确的样本数 / 识别出来的样本数
2. 召回率:识别为正确的样本数 / 所有样本中正确的数
模型的效果需要在这两个指标之间达到一个平衡。
测试同事需要关注一领域内每个类别的指标,比如针对识别人脸的表情,里面有喜怒哀乐等等分类,每一个分类对应的指标都是不一样的。测试同事需要将测试的结果完善地反馈给算法同事,算法同事才能找准模型效果欠缺的原因。同时测试同事将本次模型的指标结果反馈给产品,由产品评估是否满足上线需求。
评估模型是否满足上线需求是产品必须关注的,一旦上线会影响到客户的使用感。
因此在模型上线之前,产品需反复验证模型效果。为了用数据对比本模型和上一个模型的优劣,需要每次都记录好指标数据。
假设本次模型主要是为了优化领域内其中一类的指标,在关注目的的同时,产品还需同时注意其他类别的效果,以免漏洞产生。
产品的工作不止是产品评估:
除了流程控制,质量评估。针对分类问题,由产品制定的边界非常重要,直接影响模型是否满足市场需求。
产品制定的分类规则:例如,目的是希望模型能够识别红色,那产品需要详细描述“红色”包含的颜色,暗红色算红色吗?紫红色算红色吗?紫红色算是红色还是紫色?这些非常细节的规则都需要产品设定。
若果分类细,那么针对一类的数据就会少。如果分类大,那么一些有歧义的数据就会被放进该分类,也会影响模型效果。
分类问题和策略问题道理是一样的,都需要产品对需求了解得非常深刻。
以上内容,都只是 AI 行业一个小领域内可梳理的工作内容。
针对刚刚入行的朋友,如果没有算法基础、没有工程基础。可以考虑在流程、平台上做过渡。在工作内容中不断总结学习,往自己想走的方向不断前进!
原文链接:
http://www.jianshu.com/p/97e5c8bf9459



