大规模时间序列分析框架的研究与实现,计算机学报

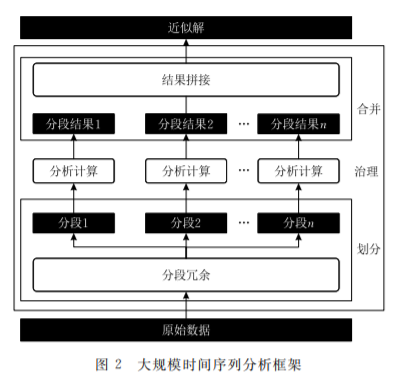
工业互联时代,每天数以亿计的传感器源源不断生成时间序列,用以记录工业设备的温度、振动、压力、曲度和张力等参数。如何从这些非结构化的时间序列中挖掘出有价值信息,并运用于状态监测、故障诊断和控制决策,引起了广泛的关注和研究。随着数据规模日益增长,能够提供较为完备数据分析算法库的主流单机环境如Matlab、R等,已无法较好地应对大规模时间序列分析场景下的数据处理需求。而现有的并行分析算法数量有限,常与平台相互绑定,更换平台需对算法进行二次开发,可扩展性较差。本文旨在设计一种通用的近似解分析框架,支持第三方算法快速实现并行化,解决因数据规模过大而导致的算法适用性问题。分析框架主要包含任务划分、治理和合并三个步骤。任务划分通过冗余保留了数据的局部相关性,生成相互独立的子任务,减少分布式节点之间的数据通信和同步开销。对于任务划分问题,本文提出了近似解代价模型,得到了最优的任务划分方案。基于Spark平台设计并实现了原型系统,实验结果表明,该系统在确保分析结果准确性的前提下,其加速能力随着并行程度保持近似线性的增长,解决了单机算法的数据规模受限问题。同时,该系统易于集成与扩展,使数据分析人员免于算法重复开发。
地址:
https://kns.cnki.net/kcms/detail/Detail.aspx?dbname=CAPJLAST&filename=JSJX20190711000&v=
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“TSAF” 可以获取《大规模时间序列分析框架的研究与实现,计算机学报》专知下载链接索引



登录查看更多
相关内容
专知会员服务
104+阅读 · 2019年10月22日




相关VIP内容
专知会员服务
104+阅读 · 2019年10月22日
相关资讯
相关论文