DeepMind默默开源三大新框架,深度强化学习落地希望再现!
【导读】近几年,深度强化学习(DRL)一直是人工智能取得最大突破的核心。 尽管取得了很多进展,但由于缺乏工具和库,DRL 方法仍难以应用于主流的解决方案。 因此,DRL 主要以研究形式存在,并未在现实世界的机器学习解决方案中得到大量应用。 解决这个问题需要更好的工具和框架。 而在当前的 AI 领域,DeepMind 在推动 DRL 研发方面做了大量工作,包括构建了许多专有工具和框架,以大规模地简化 DRL agent 训练、实验和管理。
最近,DeepMind 又默默开源了三种 DRL 框架:OpenSpiel、SpriteWorld 和 bsuite,用于简化 DRL 应用。
OpenSpiel
-
安装系统包并下载一些依赖项。 只需要运行一次。
./install.sh
-
安装 Python 依赖项,例如在 Python 3 中使用 virtualenv:
vvirtualenv -p python3 venvsource venv/bin/activatepip3 install -r requirements.txt
-
构建并运行测试以检查一切是否正常:
./open_spiel/scripts/build_and_run_tests.sh
-
添加
# For the python modules in open_spiel.export PYTHONPATH=$PYTHONPATH:/<path_to_open_spiel># For the Python bindings of Pyspielexport PYTHONPATH=$PYTHONPATH:/<path_to_open_spiel>/build/python
-
open_spiel / integration_tests: 所有游戏的通用(python)测试。 -
open_spiel / tests: C ++ 常用测试实用程序。 -
open_spiel / scripts: 用于开发(构建、运行测试等)的脚本。
-
open_spiel /: 包含游戏抽象 C ++ API。 -
open_spiel / games: 包含 games ++实现。 -
open_spiel / algorithms: 在 OpenSpiel 中实现的 C ++ 算法。 -
open_spiel / examples: C ++ 示例。 -
open_spiel / tests: C ++ 常用测试实用程序。
-
open_spiel / python / examples: Python 示例。 -
open_spiel / python / algorithms /: Python算法。
-
这里仅介绍添加新游戏最简单、最快捷的方式。 首先要了解通用 API(参见 spiel.h)。
-
将标头和源: tic_tac_toe.h,tic_tac_toe.cc和tic_tac_toe_test.cc 复制到 new_game.h,new_game.cc 和 new_game_test.cc。 -
配置 CMake:
-
将新游戏的源文件添加到 games / CMakeLists.txt。 -
将新游戏的测试目标添加到 games / CMakeLists.txt。
-
更新样板C ++代码:
-
在 new_game.h 中,重命名文件顶部和底部的标题保护。 -
在新文件中,将最内层的命名空间从 tic_tac_toe 重命名为 new_game。 -
在新文件中,将 TicTacToeGame 和 TicTacToeState 重命名为 NewGameGame 和 NewGameState。 -
在 new_game.cc 的顶部,将短名称更改为 new_game 并包含新游戏的标题。
-
更新 Python 集成测试:
-
将简短名称添加到 integration_tests / api_test.py 中的已排除游戏列表中。 -
在 python / tests / pyspiel_test.py 中将短名称添加到预期游戏列表中。
-
现在,你有了一个不同名称的 Tic-Tac-Toe 复制游戏。 测试运行,并可以通过重建和运行示例 examples / example --game = new_game 来验证它。 -
现在,更改 NewGameGame 和 NewGameState 中函数的实现以表示新游戏的逻辑。 你复制的游戏中的大多数 API 函数都应该与原来的游戏有区分度。 如果没有,那么重合的每个API 函数都将在 spiel.h 中的超类中被完整记录。 -
完成后,重建并重新运行测试以确保一切都顺利(包括新游戏测试! )。 -
更新 Python 集成测试:
-
运行 ./scripts/generate_new_playthrough.sh new_game 生成一些随机游戏,用于集成测试以防止任何回归。 open_spiel / integration_tests / playthrough_test.py 将自动加载游戏并将它们与新生成的游戏进行比较。
SpriteWorld
-
多目标的竞技场反映了现实世界的组合性,杂乱的物体场景可以共享特征,还可以独立移动。 此外,它还可以测试与任务无关的特征/对象的稳健性和组合泛化。 -
连续点击推动动作空间的结构反映了世界空间和运动的结构。 它还允许 agent 在任何方向上移动任何可见对象。 -
不以任何特殊方式提供对象的概念(例如,没有动作空间的特定于对象的组件),agent 也完全可以发现。
-
目标寻找。 agent 必须将一组目标对象(可通过某些功能识别,例如“绿色”)带到屏幕上的隐藏位置,忽略干扰对象(例如非绿色的对象) -
排序。 agent 必须根据对象的颜色将每个对象带到目标位置。 -
聚类。 agent 必须根据颜色将对象排列在群集中。
pip install spriteworld
pip install git + https://github.com/deepmind/spriteworld.git
git clone https://github.com/deepmind/spriteworld.gitpip install spriteworld /
python /path/to/local/spriteworld/run_demo.py
bsuite
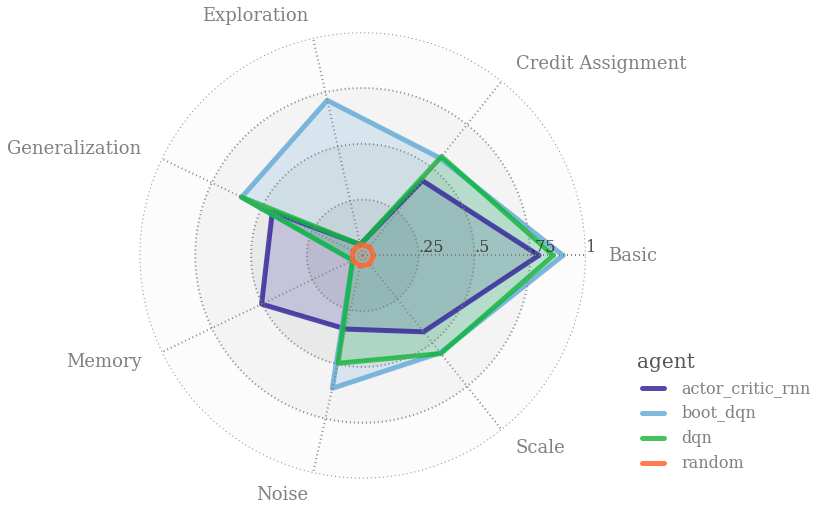
-
收集清晰、信息量大且可扩展的问题,以捕获高效和通用学习算法设计中的关键问题。 -
通过在这些共享基准上的表现来研究 agent 行为
pip install git+git://github.com/deepmind/bsuite.git
pip install bsuite/
pip install -e bsuite /
pip install -e bsuite
import bsuiteenv = bsuite.load_from_id('catch/0')
from bsuite import sweepsweep.SWEEP
sweep.DEEP_SEAsweep.DISCOUNTING_CHAIN
pdflatex bsuite / reports / neurips_2019 / neurips_2019.tex
深度强化学习实验室
算法、框架、资料、前沿信息等
长按二维码关注我们吧
GitHub仓库
https://github.com/NeuronDance/DeepRL
欢迎Fork,Star,Pull Request

微信交流群助手:
NeuronDance
第三篇:深度强化学习框架-OpenSpiel(DeepMind开源28种DRL环境+24种DRL算法实现)
登录查看更多
相关内容

IEEE情感计算TAC(IEEE Transactions on Affective Computing)是一份跨学科的国际档案期刊,旨在传播能够识别、解释和模拟人类情感和相关情感现象的系统设计研究成果。
官网地址:http://dblp.uni-trier.de/db/journals/taffco/
专知会员服务
131+阅读 · 2020年4月19日
专知会员服务
41+阅读 · 2020年4月11日




相关VIP内容
专知会员服务
131+阅读 · 2020年4月19日
专知会员服务
41+阅读 · 2020年4月11日
相关资讯
相关论文