清华朱军团队包揽三项冠军 | NIPS 2017对抗样本攻防竞赛总结(附学习资料)

来源:AI科技评论
作者:高云河
本文共8989字,建议阅读10分钟。
本次比赛总结由谷歌大脑、清华大学以及其它参与研究人员们联合撰写,为你介绍NIPS 2017 对抗样本攻防比赛的情况。
自 Ian Goodfellow 等研究者发现了可以让图像分类器给出异常结果的"对抗性样本"(adversarial sample)以来,关于对抗性样本的研究越来越多。NIPS 2017 上 Ian Goodfellow 也牵头组织了 Adversarial Attacks and Defences(对抗攻击防御)竞赛,供研究人员、开发人员们在实际的攻防比拼中加深对对抗性样本现象和相关技术手段的理解。
在比赛结束后,参与此次比赛的谷歌大脑、清华大学以及其它参与的企业和学校的研究人员们联合撰写了一篇对于本次比赛的总结。其中清华大学博士生董胤蓬、廖方舟、庞天宇及指导老师朱军、胡晓林、李建民、苏航组成的团队在竞赛中的全部三个项目中得到冠军。我们把这篇比赛总结的主要内容编译如下。
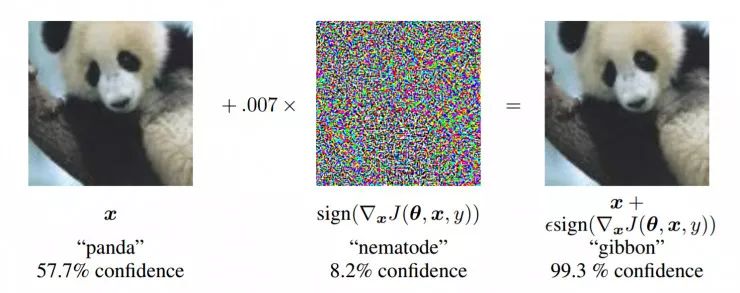
简介
最近机器学习和深度神经网络的飞速发展,使得研究人员能够解决诸如图像、视频、文字分类等很多重要的实际问题。然而目前的机器学习分类器很容易受到对抗样本的攻击。所谓对抗样本,就是对输入数据进行略微修改,以使得机器学习算法对该输入给出错误的分类结果。在很多情况下,这些修改非常细微,人类观察者甚至根本不会注意到这些修改,但是分类器却会因此犯错误。对抗样本攻击对目前的机器学习系统提出了挑战,因为即使攻击者无法访问基础模型,也能对机器学习系统发起攻击。
此外,在现实世界中运行的机器学习系统也可能遇到对抗样本攻击,它们通过不准确的传感器感知输入,而不是以精确的数字信息作为输入。从长远角度来看,机器学习和 AI 系统必将变得更加强大。类似于对抗样本的机器学习安全漏洞可能危害甚至控制强大的 AI 们。因此,面对对抗样本的鲁棒性是 AI 安全问题的一个重要组成部分。
针对对抗样本的攻击和防御的研究有很多的困难之处,其中一个原因是很难评估一个提出的攻击方式或者防御措施是否有效。对于传统的机器学习,假设已经从独立同分布的数据集中分出了训练集和测试集,那么就可以通过计算测试集的损失来评估模型的好坏,这是一种很简单的方法。但是对于对抗机器学习,防御者必须应对一个开放的问题,即攻击者将发送来自未知分布的输入。仅仅提供针对某种单一的攻击方式的防御方式,或者一系列研究人员提前准备好的防御方式是不够的。因为即使防御者在这样的实验中表现良好,机器学习系统也可能会因为某些防御者没有预料到的攻击而被攻破。理想情况下,一种防御方式是可以被证明可行的,但是通常机器学习和神经网络很难从理论上进行分析。因此,这次举办的比赛使用了一种有效的评估方法:多只独立的队伍作为防守方和攻击方进行对抗,两方都尽可能的去获得胜利。这种评估方法虽然不如理论证明那样有决定性,但是这与现实生活中安全场景下的攻防对抗更相似。
在这篇文章中,我们介绍了NIPS 2017 对抗样本攻防比赛的情况,包括对抗样本攻击研究的一些关键问题(第二部分),比赛组织结构(第三部分),以及一些顶尖参赛者所使用的一些方法(第四部分)。
对抗样本
对抗样本是指那些经过特定优化,使得对模型的输入进行了错误分类。如果输入样本是一个自然得到的样本,比如来自 ImageNet 数据集的照片,我们称之为"干净样本"(clean example)。如果攻击者修改了样本,目的是使得该样本会被误分类,我们称之为"对抗样本"(adversasrial example)。当然,这种对抗攻击并不一定会成功,模型可能仍然能够正确分类对抗样本。我们可以测量不同模型在特定对抗样本集上的准确率或者错误率。
常见攻击场景
可能的对抗样本攻击可以从几个维度进行分类。
首先,可以通过攻击的目标或者期望进行分类。
无目标攻击(non-targeted attack)。在这种情况下,攻击方的目标仅仅是使得分类器给出错误预测,具体是哪种类别产生错误并不重要。
有目标攻击(targeted attack)。在这种情况下,攻击方想要将预测结果改变为某些指定的目标类别中。
其次,可以通过攻击者对模型的了解程度进行分类。
白盒攻击。攻击者拥有模型的全部知识,包括模型的类型,模型结构,所有参数和可训练权重的值。
有探针的黑盒攻击。攻击者对模型所知道的并不多,但是可以探测或者查询模型,比如使用一些输入,观察模型的输出结果。这种场景有很多的变种,比如攻击者知道模型结构,但是不知道参数的值,或者攻击者甚至连模型架构都不知道;攻击者可能能够观测到模型输出的每个类别的概率,或者攻击者只能够看到模型输出最可能的类别名称。
无探针的黑盒攻击。在没有探针的黑盒攻击中,攻击者只拥有关于模型有限的信息或者根本没有信息,同时不允许使用探测或者查询的方法来构建对抗样本。在这种情况下,攻击者必须构建出能够欺骗大多数机器学习模型的对抗样本。
再次,可以通过攻击者给模型输入对抗样本的方法进行分类。
数字攻击。在这种情况下,攻击者能够直接将实际的数据输入到模型中。换句话说,攻击者可以将特定的 float32 数据作为输入给模型。在现实世界中,攻击者可能给某些网络服务上传 PNG 图片文件,使得这些精心设计过的文件会被错误的读取。比如为了使得某些垃圾内容能够发布在社交网络上,需要使用对图像文件加入对抗扰动以绕过垃圾内容检测器。
物理攻击。在现实世界中这种情况下,攻击者不能够直接给模型提供数字表示。但是,模型的输入是从某些传感器中得到的,比如相机或者麦克风。攻击者可以在相机前放置某些物体,或者对麦克风播放一些声音。传感器所得到的最终表示会根据一些因素而改变,比如相机的角度,到麦克风的距离,周围环境的光线和声音等。这意味着攻击者对机器学习模型输入的控制并不是很精确的。
攻击方法
第一类,白盒数字攻击
1. L-BFGS
第一个发现神经网络对抗样本攻击的方法之一是 Goodfellow 等人的 Intriguing properties of neural networks 论文。该方法的思路是解决如下的优化问题:
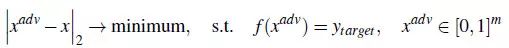
作者提出使用 L-BFGS 优化方法去解决这个问题,所以以此命名这种攻击方法。
这种方法的一个主要缺点是运行速度很慢。该方法旨在找到最小的可能的攻击扰动。这意味着该方法有时可能仅仅通过降低图像质量而被打败,比如把图像的每个像素四舍五入,用 8 位二进制数字表示。
2. FGSM(Fast gradient sign method)
为了验证对抗样本只需通过目标模型的线性近似来得到的想法,I. J. Goodfellow, J. Shlens, and C. Szegedy 等人在 Explaining and harnessing adversarial examples 文章中提出了快速梯度符号函数方法(FGSM)。
FGSM 方法通过在干净样本的邻域中线性化损失函数,并通过如下闭合形式的方程找到精确的线性化函数的最大值:
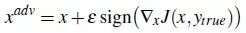
3. 迭代攻击(Iterative attacks)
L-BFGS 攻击有很高的成功率,但计算成本也很高。FGSM 攻击成功率很低(特别是当防御者预测到有攻击会发生的时候),但是计算成本很低。为了得到一个良好的折中方案,在少量迭代之后(如 40 次),重复运行专门的优化算法以快速得到结果。
一种快速设计优化算法的策略是,使用 FGSM(通常可以在一个很大的步长里得到可接受的结果),但是使用较小的步长运行几次。这是因为 FGSM 每步都被设计为一直走到以该步骤起始点的小范围球的边缘,所以即使在梯度很小的情况下,该方法也能有较快的进展。这也引出了 Adversarial examples in the physical world 论文中的基本迭代方法(Basic Iterative Method, BIM),有时也称为迭代 FGSM(I-FGSM):
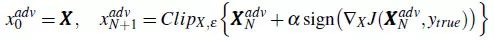
BIM方法可以很容易改进为目标攻击,称为迭代目标类别方法(Iterative Target Class Method):
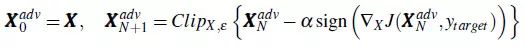
根据实验结果,运行足够次数的迭代之后,该方法总能成功生成目标类别的对抗样本。
4. Madry 攻击
Towards deep learning models resistant to adversarial attacks 这篇文章表示, BIM 可以通过 ε 范围球内的随机点开始而得到显著的改善。这种攻击通常被称为"投影梯度下降"(projected gradient descent),但这个名字有些令人困惑,因为:
投影梯度下降"一词已经指代了一种更普遍的优化方法,而不仅用于对抗攻击;
一些其他攻击方法也使用了梯度和投影,(Madry 攻击与 BIM 仅仅在起始点出不同),所以这个名字并没有将 Madry 攻击与其他攻击区分开来。
5. Carlini 和 Wagner攻击(C&W)
N.Carlini 和 D.Wagner 遵循 L-BFGS 攻击的道路进一步改善。它们设计了一个损失函数,它在对抗样本中有较小的值,但在干净样本中有较大的值,因此通过最小化该损失函数即可搜寻到对抗样本。但是与 L-BFGS 方法不同的是,本方法使用了 Adam 解决这个优化问题,通过改变变量(比如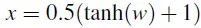
它们尝试了几种可能的损失函数,其中下面这个损失函数得到了最强的L2攻击:
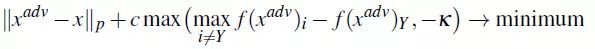
其中 Xadv 是经过参数化的
6. 对抗变换网络(Adversarial transformation networks, ATN)
Adversarial transformation networks: Learning to generate adversarial examples 一文中,提出了一种训练一个生成模型去生成对抗样本的方法。这个模型以干净样本作为输入,生成对应的对抗样本。该方法的一个有点是,如果生成模型本身是一个很小的网络,那么 ATN 相比于使用优化的算法能够更快的生成对抗样本。理论上,该方法甚至比 FGSM 更快。虽然ATN确实需要更多的时间去训练,但是一旦训练好,大量的对抗样本可以以极低的成本生成出来。
7. 不可微分系统的攻击(Attacks on non differentiable systems)
上面提到的所有攻击,都需要计算被攻击模型的梯度,以生成对抗样本。然而,这些方法并不总是可行的,比如如果模型包含不可微的操作。在这种情况下,攻击者可以训练一个替代的模型,应用对抗样本的可迁移性(transferability)对不可微系统实施攻击,这与下面提到的黑盒攻击比较类似。
第二类,黑盒攻击
据 Intriguing properties of neural networks 论文的结果,对抗样本在不同模型之间可以泛化。换句话说,能够欺骗一个模型的对抗样本,大多数情况下也能够骗过其他不同的模型。这个模型被称为可迁移性(transferability),可以用于黑盒场景中制作对抗样本。根据源模型、目标模型、数据集和其他因素的不同,可迁移的对抗样本的实际比例可能会从几个百分点到 100% 不等。黑盒场景中,攻击者可以在与目标模型相同的数据集上训练自己的模型,甚至可以使用同分布的其他数据集上训练模型。攻击者训练的模型的对抗样本很有可能能够欺骗未知的目标模型。
当然,可以通过系统地设计模型,提高对抗样本迁移的成功率,而不仅仅是依靠运气来实现迁移。
如果攻击者不在完整的黑盒子场景中,允许使用探针,那么探针可以用来训练攻击者自己的目标模型副本,这个副本被称为"替代者"。这种方法非常强大,因为作为探针的输入样本不需要是真正的训练样本,它们可以是攻击者特定选择的,可以准确找出目标模型的决策边界所在位置的样本。因此,攻击者的模型不仅可以被训练成为一个好的分类器,而且实际上可以对目标模型的细节进行逆向工程,所以两个模型从系统性上来看,可以有很高的样本迁移成功率。
在攻击者无法发送探针的完成黑盒场景下,增加样本迁移成功率的策略之一是将多个模型组成为一个集合,作为源模型以生成对抗样本。这里的基本思想是,如果一个对抗样本能够欺骗整个集合中的每个模型,那么它更有可能泛化并欺骗其他模型。
最后,在有探测器的黑盒场景中,可以运行不使用梯度直接攻击目标模型的优化算法。这样生成单个对抗样本所需的时间通常远高于使用"替代者"所需的时间,但是如果只需少量的对抗样本,那么这些方法可能更具优势,因为它们不需要高昂的训练"替代者"的成本。
防御方法综述
目前为止,并没有一个防御对抗样本的方法能够达到完全令人满意的程度。这仍然是一个快速发展的研究领域。这里我们将概述目前为止提出的方法(尚未完全成功的防御方法)。
由于许多方法产生的对抗性扰动对于人类观察者来说,看起来像高频噪声,因此很多研究者建议使用图像预处理和去噪作为针对对抗样本的潜在防御方法。所提出的预处理有很多方法,比如进行 JPEG 压缩,或者使用中值滤波和降低输入数据的精度。虽然这些防御措施可能对于很多攻击方法很好,但是这种方法已经被证明在白盒攻击场景下失效,即攻击者知道防御者会使用这种预处理或去噪方法进行防御。在黑盒攻击的情况下,这种防御在实践中得到了有效的结果,这次防御竞赛的胜利队伍也证明了这点。在后面会介绍到,他们使用了众多去噪方案中的一个。
许多防御方法有意或无意的,都使用了一种"梯度掩蔽"(gradient masking)的方法。大多数白盒攻击通过计算模型的梯度来运行,因此如果不能计算得到有效的梯度,那么攻击就会失效。梯度掩蔽使得梯度变得无用,这通常是通过在某种程度上改变模型,使其不可微分,或者使其在大多数情况下具有零梯度,或者梯度点远离决策边界。实际上,梯度掩蔽所做的是在不实际移动决策边界的情况下,使得优化器不能工作。但是由于使用同分布数据集训练出的模型的决策边界相差不会很多,所以基于梯度掩蔽的防御方法很容易被黑盒迁移攻击攻破,因为攻击者可以在"替代者中得到梯度。一些防御策略(比如将平滑的 sigmoid 单元替换为硬阈值)被直接设计为执行掩蔽掩盖,其他的一些防御措施,如很多形式的对抗训练,并没有以梯度掩蔽作为目标设计,但是在实践中实际做的也是与梯度掩蔽类似的工作。
还有一些防御措施首先检测对抗样本,并在有迹象表明有人篡改输入图像的情况下拒绝对输入进行分类。这种方法只有攻击者不知道探测器的存在或者攻击不够强时才可以正常工作。否则攻击者可以构建一种攻击,既欺骗检测器使之认为对抗样本是合法的输入,又欺骗分类器使之做出错误的分类。
一些防御措施很有效,但是会以严重降低干净样本的准确率作为代价。比如浅层 RBF 网络对于小数据集(如MINIST)上的对抗样本有很强的鲁棒性,但是相较于深度神经网络在干净样本上有差的多的准确率。深度 RBF 网络可能既对对抗样本有很好的鲁棒性,同时对干净样本也有很好的准确率,但是据我们所知,没有人成功训练好一个深度 RBF 网络。
胶囊网络(capsule network)在 Small-NORB 数据集上对白盒攻击展示出了很好的鲁棒性,但尚未在对抗样本研究中其他更常用的数据集上进行评估。
当前研究论文中最流行的防御方法可能就是对抗性训练了。这个思路是在训练过程中就加入对抗样本,使用对抗样本和干净样本混合训练模型。该方法已经成功应用于大型数据集,并且可以通过使用离散向量码来表示输入,以进一步提高有效性。对抗训练的一个关键缺点是,它更容易过拟合到训练中使用的特定攻击方法中。但是这个缺点是可以被克服的,至少是在小数据集上,只需在启动攻击的优化器之前,对图像加入噪声即可。对抗训练的另一个主要缺点是,它倾向于在无意中学习做梯度掩蔽,而不是实际移动决策边界。这可以在很大程度上通过来自多个模型集合的对抗样本进行训练来克服。对抗训练还有一个关键缺点,即它倾向于过拟合到用于产生对抗样本示例的特定约束区域中去(即模型被训练为拒绝某一 max-norm 球型区域的对抗样本,但是却不能拒绝那些甚至对人类观察者来说都不具有特别挑战性的对抗样本,比如对背景像素进行大幅修改的对抗样本)。
对抗竞赛
在本部分中,我们将简单介绍本次竞赛的规则,目标和评价标准等。
本次竞赛旨在加速对抗机器学习的研究速度,以及让众多对抗攻击和防御方法互相竞争,以找到最有力的评价标准。
在这此比赛中,参赛者需提交生成的对抗样本(攻击方),和对对抗样本鲁棒的分类器(防御方)。在评估比赛结果的时候,会在数据集上运行所有攻击方法,用以生成对抗样本,然后在防御方测试这些对抗样本。攻击方按照能够成功欺骗防御方的对抗样本数量进行排名,而防守方根据能够正确分类样本的数量进行评分。
数据集
为了能够尽可能好的评价参与竞赛的各种算法,竞赛举办方按照如下的标准制作了数据集:
有足够大的数据集,且是有意义的任务,这样竞赛结果才有意义。
是众所周知的任务,这样人们就可以使用现有的分类器,这使得参赛者能够更好的专注在对抗性挑战的本质上,而不是浪费很多时间在理解任务上。
数据必须是从来没有使用过的,这样参赛者才不会过拟合到已知的数据集上。
因此竞赛举办方选择了图像分类问题作为本次竞赛的任务,并构建了与 ImageNet 兼容的全新数据集。举办方首先选择了一批从来没有用在公开数据集的图像,使用预训练的 ImageNet 分类器进行分类,之后人工验证这些分类器的分类结果是否正确。
这个全新的数据集被分为两部分:
DEV 数据集,在比赛开始提供给参赛者,用来开发参赛算法,这部分包括 1000 张图片。
FINAL 数据集,此数据集并不会提供给参赛者,在最后用来评估参赛者所提交的算法。这部分包含了 5000 张图片。
任务和竞赛规则
竞赛包含了三个部分,分别是:
无目标对抗攻击,参赛者需提交无目标黑盒攻击方法。比如,给定一个输入图像,生成一个对抗图像,尽可能使一个未知分类器给出错误的分类结果。
有目标对抗攻击,参赛者需提交有目标黑盒攻击方法。比如,给定一个输入图像和目标类别,生成一个对抗图像,尽可能使一个未知分类器将对抗图像分类为目标类别。
针对对抗攻击的防御,参赛者需提交一个对对抗样本鲁棒的分类器。
对于每个提交的结果,评估程序会以每批 100 张图片作为输入。为了限制提交的结果所需的计算资源,举办方规定每批中的 100 张图片需要在 500 秒之内处理完毕,如果 500 秒之内没有处理完毕,那么当前批的处理程序会被中断,并将下一批的 100 张图像输入。只有成功处理好的图片才被计入得分。
评价标准
每次当有一张图片能够成功欺骗防守方,攻击方得到1分。如果攻击方没有欺骗防守方,或者在时间限制内未能产生对抗样本图片,则该图片得0分。对于每个正确分类的图片,防守方得到1分,对于不正确分类或者未能产生分类的图片,防守方得0分。最后将所有的得分相加到一起,进行归一化,使得所有队伍提交的结果最终得分在[0,1]的范围内,其中1表示所有图像均成功,而0表示所有图像均失败。
比赛规则
比赛于2017年7月开始,在2017年10月1号结束,整个比赛多个轮次,其中有三个开发轮,和一个最终轮。其中开发轮的主要目的是让参赛者测试他们的结果,只有最终轮才被用来计算最后的评分并决定谁是冠军。
竞赛结果
直到比赛结束,举办方共收到 91 个无目标对抗攻击的提交结果, 65 个有目标对抗攻击的提交结果,和 107 个防御方提交的结果。
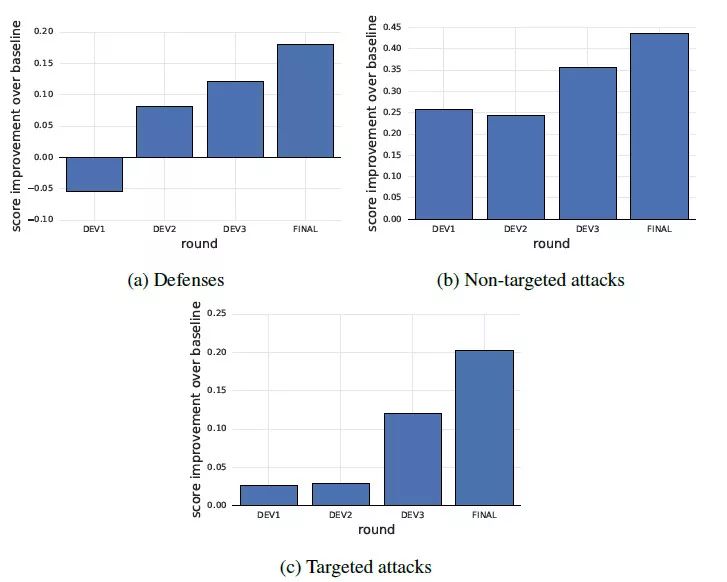
这幅图展示了每个轮次中得分最高的提交结果相较于 baseline 有多大的提升,可见提交结果的性能在每轮中都有提高。
下面的三个表格分别为防御比赛,无目标攻击比赛和有目标攻击比赛中 top-5 队伍的结果。其中 score 为归一化之后的得分,raw score 是未归一化的得分,而 worst score 是最差情况下的得分,Median eval time 是处理一批 100 张图片所需要的时间。
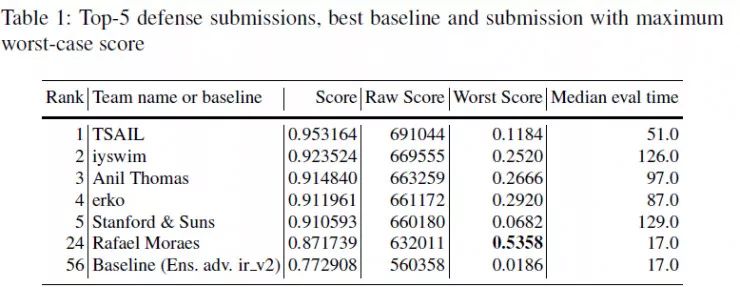
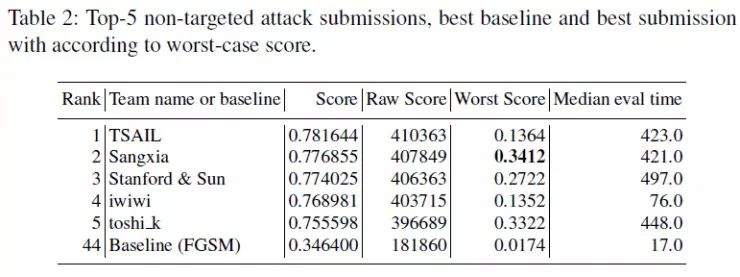
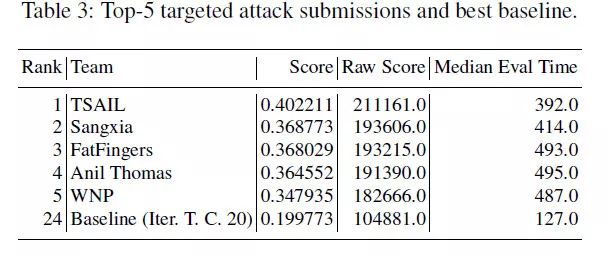
从表中的结果可以看出,最好的防御方法在所有对抗图像中,能够得到超过 90% 的准确率。但是与此同时,防御的最差情况下,最高只有 53.6% 的准确率。这就意味着,虽然平均情况下对于对抗样本能够得到很高的准确率,但是模型仍然存在可能被攻击的方法,而这是有可能被攻击者发现的。
来自清华大学的 TSAIL 团队在防御、无目标、有目标攻击三个项目中都得到了冠军。
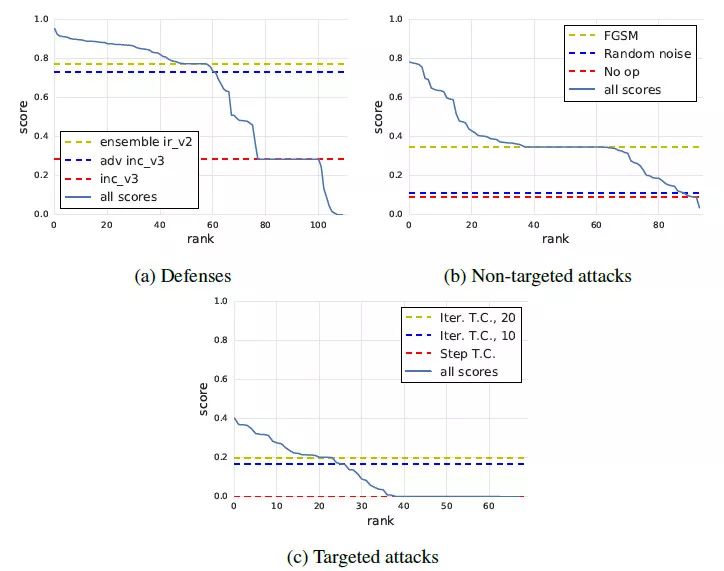
上图展示了三种竞赛中,各个队伍的得分情况,其中实线表示各个排名的队伍的得分。虚线表示不同的baseline方法。
顶尖队伍的方法
本部分将展示几个评分最高的队伍的解决方案。
防守竞赛冠军:清华大学 TSAIL 队
该队伍使用了高阶表征引导去噪器(High-level representation guided denoiser, HGD),整体思路是训练一个基于神经网络的去噪器来去除对抗扰动。
为了训练去噪器,该队从 ImageNet 训练集中提取了 20K 张图片(每个类别 20 张图)。之后使用多种对抗攻击方法来处理这些图像,生成训练集。其中使用了 FGSM 和 I-FGSM 作为攻击方法,并且将这些攻击应用到多种模型中,最终结合多种模型来模拟各种强度的攻击。
该队使用了 U-Ne t作为去噪网络,U-Net 相较于编码器解码器结构,在同分辨率的编码层和解码层之间直接相连,这样网络只需学习如何去除噪声,而无须学习如何重建整个照片。
该队并没有使用常见的重建距离损失来训练网络。他们使用了网络第 l 层的高阶表达作为损失函数,该方法被称为 HGD。因为这些监督信号来自于分类器的高阶表达,而这些特征通常包含了与图像分类有关的引导信息。
具体细节可以参考该队伍的论文:
Defense against adversarial attacks using high-level representation guided denoiser
两种攻击竞赛冠军:清华大学 TSAIL 队
该队伍同时赢得了无目标攻击和有目标攻击两项竞赛的冠军,他们使用了基于梯度的动量迭代攻击方法(Momentum iterative gradient-based attack)。
动量迭代攻击方法是基于基本的迭代方法(BIM)构建的,增加了动量项,极大地改善了生成对抗样本的可迁移性。目前的攻击算法由于需要在攻击强度和可迁移性之间进行折衷,往往在攻击黑盒模型时效率很低。详细的说,一些单步的方法,如 FGSM,假设在数据点附近决策边界是线性的,并据此计算一次梯度。然而实际情况中,由于较大的失真,线性假设往往不成立,这就使得单步的方法不能很好的拟合模型,使得攻击强度变低。相反的是,基本迭代方法使用贪婪法在每次迭代中将对抗样本沿梯度方向移动。因此对抗样本很容易过拟合到局部极值点,这就使得模型之间的迁移变得困难。
为了解决这个问题,该队在基本迭代模型中加入了动量项,以稳定更新的方向,使得优化能够逃离局部极值点。该方法与最优化任务中的动量所带来的好处是类似的。因此该方法减轻了攻击强度和可迁移性之间的折衷,展现出了强大的黑盒攻击能力。
详细的细节可以参考论文:
Boosting adversarial attacks with momentum
防守竞赛亚军:iyswim 队
该队使用了一种随机的方法来防御对抗样本攻击。该思路十分简单,只是在分类网络之前加入了随机缩放层(resize)和随机填充(padding)层。这样做的好处是:
无须 fine-tune 网络;
只增加了极少量的计算;
与其他防御方法兼容
通过结合这个随机的方法和经过对抗样本训练的模型,该队就在竞赛中排名第二。
详细的内容可以参考论文:
Mitigating adversarial effects through randomization
两种攻击竞赛亚军:Sangxia 队
该队使用了针对多个分类器的迭代 FGSM 方法攻击,同时结合了随机扰动和增强以提高鲁棒性和可迁移性。许多工作已经证明了针对一个分类器的对抗样本可以迁移到其他分类器中去。因此,为了攻击一个未知的分类器,一个很自然的想法就是生成能够欺骗一系列分类器的样本。此外,该队还使用了图像增强以提高鲁棒性和可迁移性。
已开源:
https://github.com/sangxia/nips-2017-adversarial
有目标攻击竞赛季军:FatFinger 队
该队使用的方法与Sangxia队类似,使用了结合多种模型的迭代攻击方法。
无目标攻击竞赛第四名:iwiwi 队
该队伍的方法与其他队伍十分不同,他们训练了一个全卷积神经网络来将干净样本转换为对抗样本,并得到了第四名。
给定一个输入图像x,按照如下公式生成对抗样本:
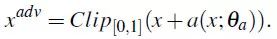
其中,a 是表示 FCN 的一个可微分函数,Theta 为该网络的参数。a 被称为攻击全卷积网络。该网络的输出为对抗扰动,因此,为了迷惑图像分类器,该队伍最大化 J(f(xadv), Y) 来训练网络,即最大化:
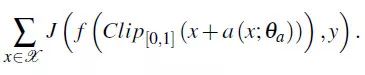
该队同时也使用了多目标训练,多任务训练和梯度提示(gradient hints)等方法一同提高性能。该队伍同时观测到,攻击网络所生成的对抗样本中,所有纹理信息都被丢掉,并增加了一些类似拼图的图案,这种图案能够欺骗图像分类器,将对抗样本分类到拼图图案所属的类。
更多信息可在GitHub上了解:
https://github.com/pfnet-research/nips17-adversarial-attack
总结
对抗样本是机器学习安全领域的中的一个有趣现象和重要问题。这次比赛的主要目的就是提高研究者对问题的认识,并激励研究者提出新的方法。
竞争确实有助于提高对问题的认识,同时也能促使人们探索新的方法并改进现有的解决方法。在所有的三项赛事中,参赛者在比赛结束前都提交了比 baseline 方法好得多的方法。此外,针对在所有攻击方法产生的对抗样本,最好的防守方法仍能得到 95% 的准确率。虽然最坏情况下的准确率不如平均准确度,但是结果仍然能够表明,在黑盒情况下实际应用在面对对抗样本攻击时,仍然有足够的鲁棒性。



