发布 Open Images V6:新增局部叙事标注
文 / Jordi Pont-Tuset,研究员,Google Research
在许多方面,Open Images 都可堪称为最大的标注图像数据集,可为计算机视觉任务训练最新深度卷积神经网络。去年 5 月发布的第 5 版 Open Images 数据集中有 900 万张有标注图像(含 3600 万个图像级标签、1580 万个边界框,280 万个实例分割以及 39.1 万个视觉关系)。该数据集本身以及围绕它展开的 Open Images 挑战赛,共同推动了物体检测、实例分割和视觉关系检测领域取得了最新进展。

Open Images V5 采用如下标注形式:图像级标签、边界框、实例分割和视觉关系。图像来源:1969 Camaro RS/SS 由 D. Miller 拍摄、房屋照片由 anita kluska 拍摄、Calico 猫咪咖啡馆新宿店由 Ari Helminen 拍摄、Radiofiera - 蒙泰基奥马焦雷 Villa Cordellina Lombardi (VI) - agosto 2010 由 Andrea Sartorati 拍摄。所有图像的使用均遵循 CC BY 2.0 许可
今天,我们宣布 Open Images V6 已正式发布,此版本通过增加大量的视觉关系(例如“狗抓飞盘”)、人类动作标注(例如“女子跳起”)和图像级标签(例如“佩斯利”)大幅扩展了 Open Images 数据集的标注范围。
值得注意的是,新版本还添加了 局部叙事标注 (localized narratives):一种全新的多模式标注形式,包含对描述对象添加的语音、文本和鼠标轨迹同步信息。在 Open Images V6 中,50 万张图像都能使用这些局部叙事功能。此外,为便于与先前的研究进行比较,我们还为 COCO 数据集中的所有图像(共 12.3 万张)发布了局部叙事标注。
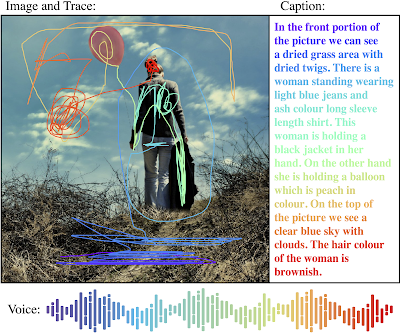
局部叙事实例,图像来源:春天来了:-) 由 Kasia 拍摄
局部叙事
添加局部叙事标注的动机之一是希望能更充分的研究与利用视觉与语言之间的联系,这通常由添加 Image Captioning (即将图像与人工添加的内容文本描述进行配对) 来完成。不过,Image Captioning 存在着诸多局限,其中一个便是缺乏视觉基础,即在进行文本描述时找准文字在图像上的位置。为解决这一问题,先前的一些研究曾采用 后验法 (Posteriori) 对描述中出现的名词绘制边界框。然而,在局部叙事标注中,文本描述中的每个词都有视觉依据。

图像内容和文字说明之间的不同对应程度。从左到右:文字说明与整张图像的对应 (COCO);名词与边界框的对应 (Flickr30k Entities);每个词与鼠标轨迹片段的对应(局部叙事)。图像来源:COCO、Flickr30k Entities 以及由 Rama 拍摄的越南沙坝风景图
局部叙事由标注者手工添加,在原本的文字描述上新增语音标注 (转录)与移动鼠标轨迹标记所描述的区域。语音标注是此方法的核心,直接将描述内容与所指的图像区域对应联系。为了让标注更易于理解,标注者转录了他们所进行的描述,并将自动语音转录结果对齐。这一过程恢复了语音描述的时间戳,从而确保三种标注形式(语音、文本和鼠标轨迹)正确且保持同步(见下图)。

手动和自动转录完好对应,以上图标均取自于 Freepik 中的原创设计
语音和鼠标定位同步进行,非常直观,由此可为标注者提供大致的任务介绍。在探索人们如何描述图像方面,也提供了潜在的研究途径。如,在指明某物体的空间范围时,我们观察到标注者有画圈、涂画、下划线等多种不同的样式。通过对此开展研究,这也将为设计新用户界面带来宝贵经验。

鼠标轨迹片段对应于图像下方的文字说明,图像来源:波西塔诺 Via Guglielmo Marconi - Hotel Le Agavi - 船只由 Elliott Brown 拍摄、机身由 vivek jena 拍摄、CL P1050512 由 Virginia State Parks 拍摄
特此说明,在为局部叙事而新增的标注中:鼠标轨迹的总长度约为 6400 公里,完整听完全部语音叙述,大约需要 1.5 年!
新视觉关系、人类动作,以及图像级标注
除了在 Open Images V6 中引入局部叙事功能以外,我们还将 视觉关系标注 (Visual Relationship Annotations) 类型增加了一个数量级(多达 1400 种),新加入了如“男子玩滑板”、“男女牵手”和“狗抓飞盘”等视觉关系。

图像来源:IMG_5678.jpg 由 James Buck 拍摄、DSC_0494 由 Quentin Meulepas 拍摄、DSC06464 由 sally9258 拍摄
自计算机视觉诞生以来,识别图像中的人像便一直是其关注重心,对于许多应用程序而言,理解这些人的行为至关重要。这就是为什么Open Images V6 中还包含了 250 万个与人类作出的独立动作(如“跳跃”、“微笑”或“躺下”)有关的标注。

图像来源:_DSCs1341 (2) 由 Boo Ph 拍摄、Richard Wagner Spiele 2015 由 Johannes Gärtner 拍摄
最后,我们还添加了 2350 万个手工验证的全新图像级标签,至此在将近2万个类别中的标签总数已达 5990 万。
总结
在为图像分类、物体检测、视觉关系检测和实例分割改进统一标注方面,Open Images V6 堪为重要的定性和定量步骤,而且还可采用全新的局部叙事方法将视觉和语言联系起来。我们希望 Open Images V6 将能协助研究人员进一步加深对于真实场景的理解。
如果您想详细了解 本文讨论 的相关内容,请参阅以下文档。这些文档深入探讨了这篇文章中提及的许多主题:
Open Images
https://ai.googleblog.com/2019/05/announcing-open-images-v5-and-iccv-2019.html物体检测
https://www.kaggle.com/c/open-images-2019-object-detection实例分割
https://storage.googleapis.com/openimages/web/challenge2019.html#instance_segmentation视觉关系检测
https://www.kaggle.com/c/open-images-2019-visual-relationshipOpen Images V6
https://g.co/dataset/openimages局部叙事
https://google.github.io/localized-narratives/COCO 数据集
http://cocodataset.org/先前的某些研究
https://arxiv.org/abs/1505.04870
更多 AI 相关阅读:




