【论文】赛尔原创 | EMNLP 2019基于知识库检索器的实体一致性端到端任务型对话系统
论文名称:Entity-Consistent End-to-end Task-Oriented Dialogue System with KB Retriever
论文作者:覃立波,刘一佳,车万翔,文灏洋,李扬名,刘挺
原创作者:覃立波
下载链接:https://www.aclweb.org/anthology/D19-1013/
转载须注明出处:哈工大SCIR
1.端到端任务型对话系统
任务型对话系统可以用来帮助用户完成订购机票、餐厅预订等业务,越来越受到研究者的关注。近几年,由于序列到序列(sequence-to-sequence)模型和记忆网络(memory-network)的强大建模能力,一些工作直接将任务型对话建模为端到端任务型对话任务。如图一所示,输入输出定义如下:
输入Utterance:“Address to the gas station.”
输入知识库 (KB)。
输出Utterance:Valero is located at 200 Alester Ave.
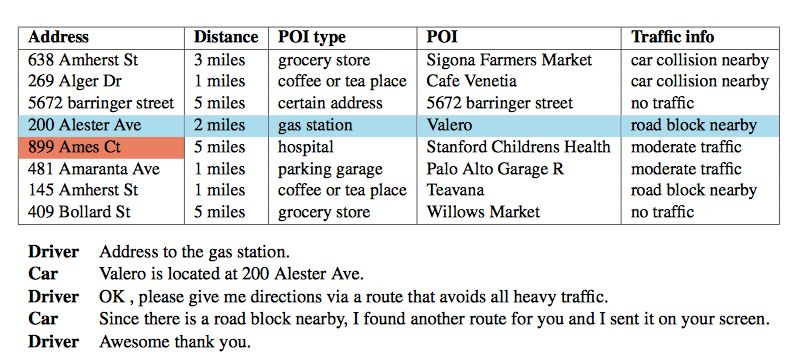
图1 InCar数据集的一个例子。上面为支撑该组对话的知识库,下面为对应的对话内容。
端到端任务型对话系统可定义为:通过sequence-to-sequence模型读入用户的需求和配套的知识库,直接生成系统的回复,如图2所示:

图2 端到端任务型对话系统的流程图
2.背景和动机
一些工作在端到端任务型对话系统中进行了探索。Eric [1] 等人第一次构建了InCar数据集,并提出了对于整个知识库进行注意力操作,然后将对知识库中的实体注意分值增广到最终的生成概率分布中,从而使得整个模型能够生成实体。Madotto [2] 等人第一次将记忆网络引入到端到端任务型对话中,用它来存储知识库和历史对话,来增强生成过程中与实体的交互。Wen[3]等人提出使用隐式的对话状态来检索相应的知识库,从而在生成过程中复制选择实体。
但是这些方法都聚焦在整个知识库的选择和注意上。往往会造成模型生成实体出现不一致的情况,如图1所示:如果系统生成回复中的POI是第四行的“Valero”,但是生成的Address又是第五行标红的“899 Ames Ct”,这就是我们所说的实体不一致的情况,这极大的影响了任务型对话系统最后的任务成功完成度。
同时,我们观察到,在任务型对话系统中,大部分回复中的实体是可以由一行知识库支撑,如图3,4所示:
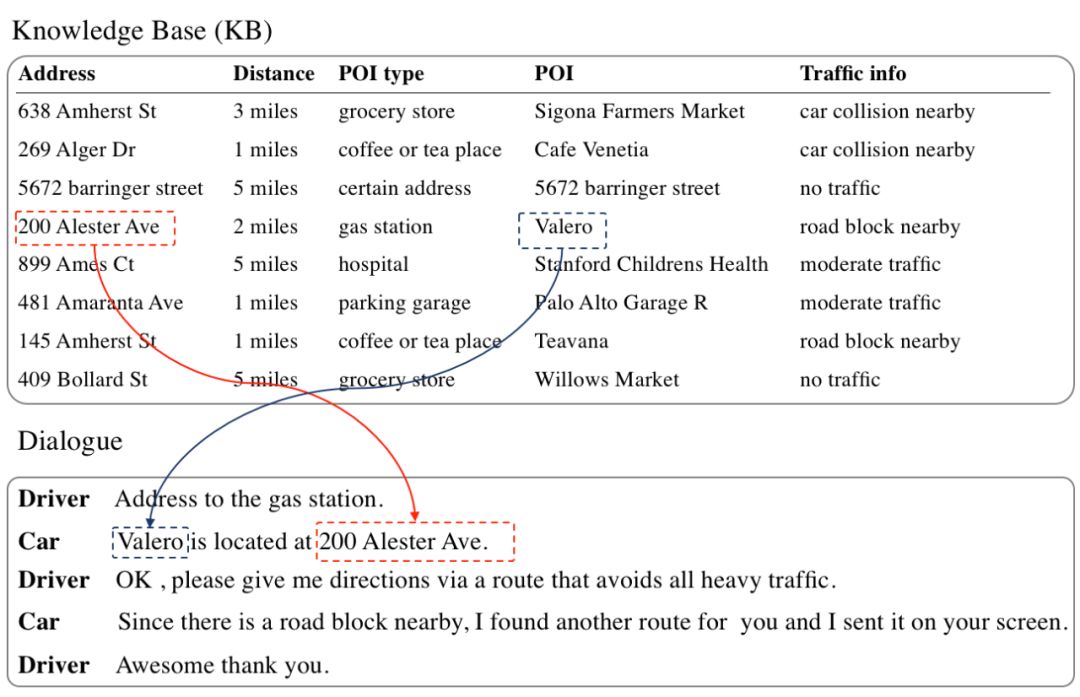
图3 一行知识库支撑回复案例
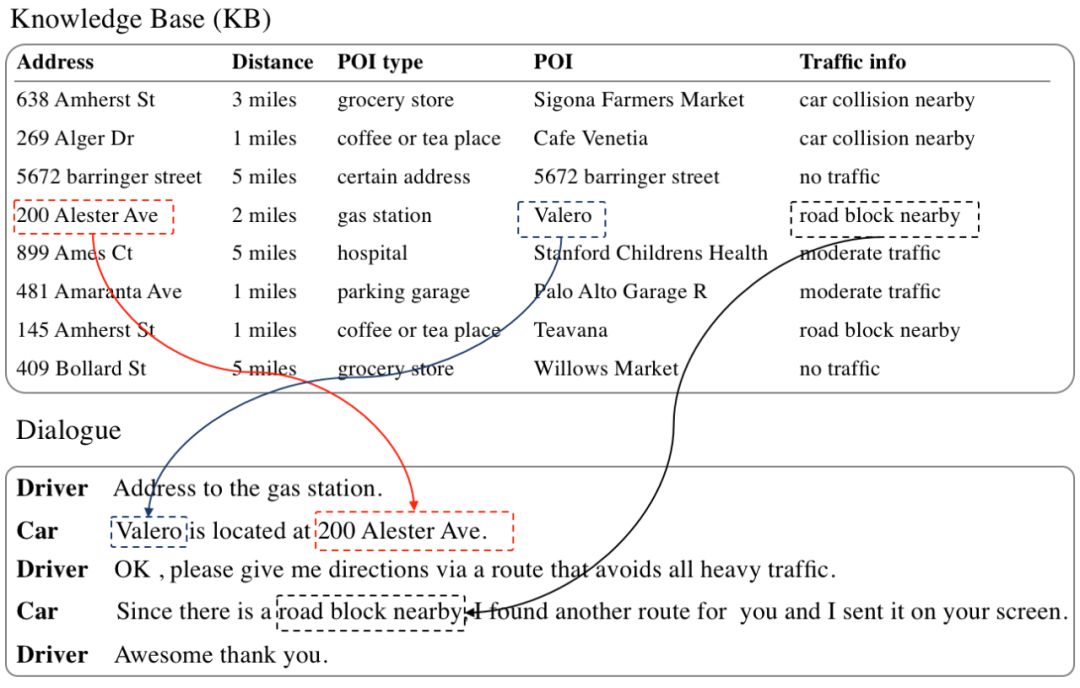
图4 一行知识库支撑回复案例
因此将该观察融入到回复生成中,可以提升生成实体的一致性。我们在本文中,提出了一个两步检索知识库的框架,第一步我们引入一个知识库检索模块来检索出最相关的知识库行,在第二步中,我们使用注意力机制来对知识库的列进行打分,最后采用复制(copy)机制,来将选中的实体融入到生成过程。在下面方法阶段我们将详细描述。
3.方法
3.1 基本的序列到序列模型
基本的序列到序列模型包括一个编码器和一个基于注意力机制的解码器,基本框架图如图5所示:
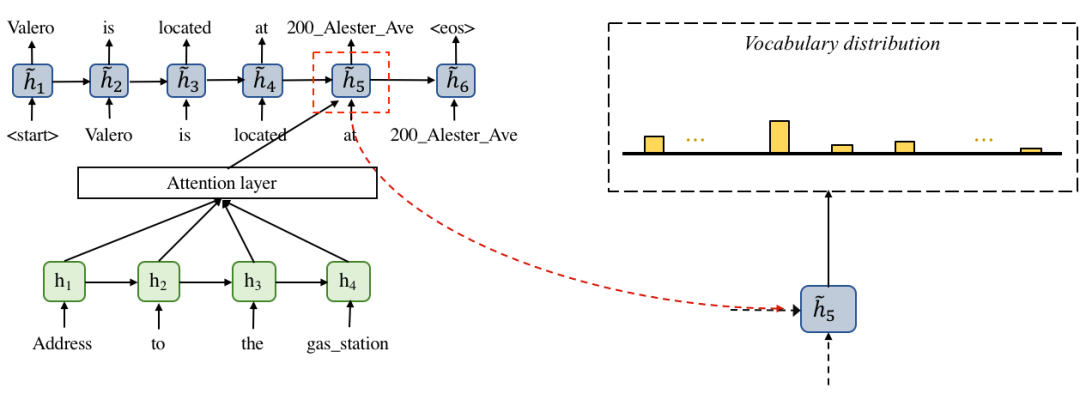
图5 基本的序列到序列模型
编码器:采用双向LSTM将对话历史进行编码得到:
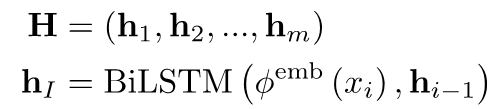
解码器:使用注意力机制的解码器,采用单向LSTM对每个时刻状态进行解码,公式如下:
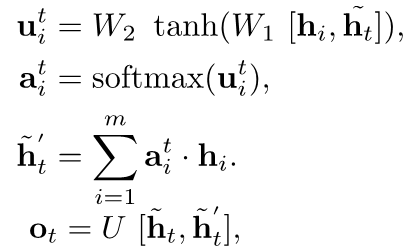
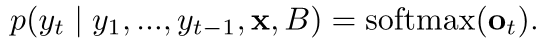
3.2 知识库行选择
我们采用记忆网络(memory-network)来建模知识库的行选择过程。
对话历史表示:我们follow原始论文(Sukhbaatar等人,2015)[4] 的神经词袋模型(BoW)来编码对话历史。
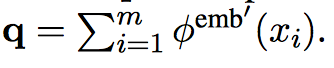
知识库每一行的表示:一行中的每个实体采用词向量表示,第行中的所有实体的词向量之和来作为该行的表示。
基于记忆网络的知识库检索器,建模过程如下:
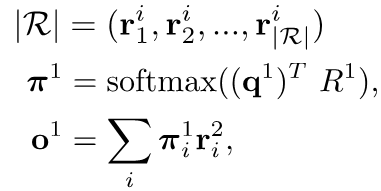
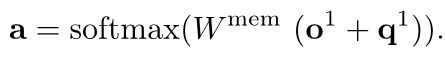
其中i代表记忆网络中第i个hop。得到a之后,我们可以将检索结果表示为: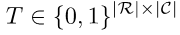
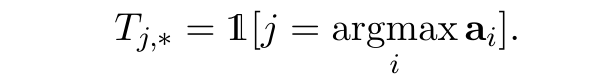
其中在检索结果中, 


图6 检索知识库行示例图
3.3 知识库列选择
我们采用注意力机制来挑选知识库列:
其中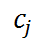

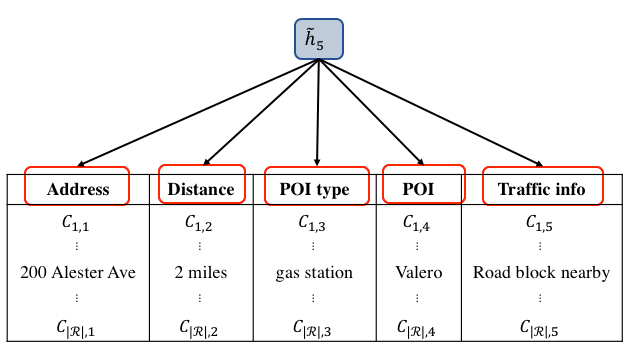
图7 检索知识库列示例图
得到了知识库列的分布,我们将之前的行选择结果t与列选择结果相乘得到我们的检索结果:
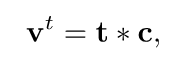
最后我们将检索结果融入到解码器生成过程中,如图8所示:
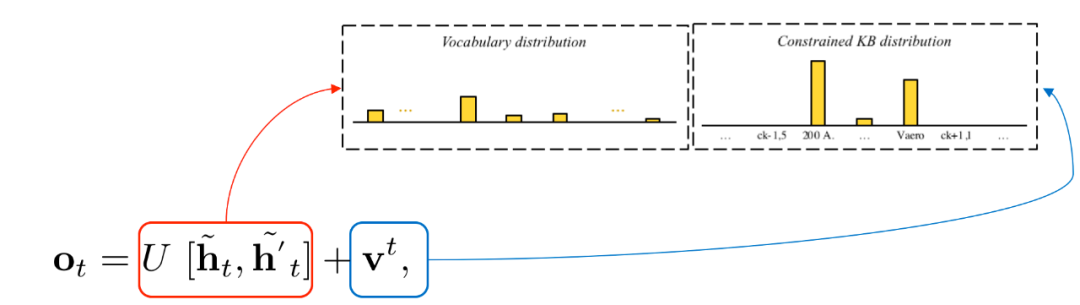
图8 生成过程融入检索知识过程
上图的红色部分代码正常词汇的生成过程,蓝色部分代表检索的知识结果。
4.训练知识库检索器
因为前面提到,给定对话历史和对应的知识库,知识库检索器需要选择一个最相关的知识库行,但是该过程没有标注数据。
于是我们提出两种方法去训练知识库检索器。
4.1 远程监督
我们设计了一些启发式规则来构造行的监督数据。在构造过程中,我们进一步假设一个任务型对话能够由一行知识库支撑。我们计算每一个知识库行与整个对话系统的相似度分数。如果有单词能够匹配上,我们就将得分进行加1.最终挑选得分最大的那行,作为我们的监督信息。例子如下:

图9 远程监督例子(1)

图10 远程监督例子(2)

图11 远程监督例子(3)
4.2 Gumbel-Softmax
由于之前挑选行的过程会使用argmax的操作,造成整个框架不能进行端到端的训练,于是我们在得到行检索结果T的时候,使用Gumbel-softmax操作来使得整个过程可微分,替换公式如下:
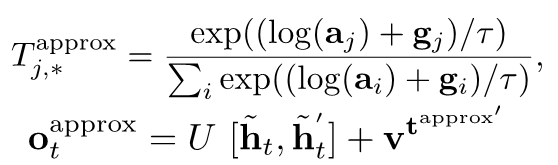
5.实验
5.1 数据集和评价指标
我们使用公开的InCar数据集,训练、开发和测试集的划分依照提出这个数据集的论文[2]进行,并且为了进一步检验我们框架的有效性,我们重新标注了Camrest数据集 [5]。我们将该数据集的每一个对话人工标注上它配套的知识库,目前该标注数据集已经开源,地址为:https://github.com/yizhen20133868/Retriever-Dialogue。
我们follow前人工作,采用BLEU来衡量生成句子的流畅度,采用实体Micro-F1值来衡量系统检索知识库的能力。
5.2 主实验结果
主实验结果如表1所示:
表1 主实验结果
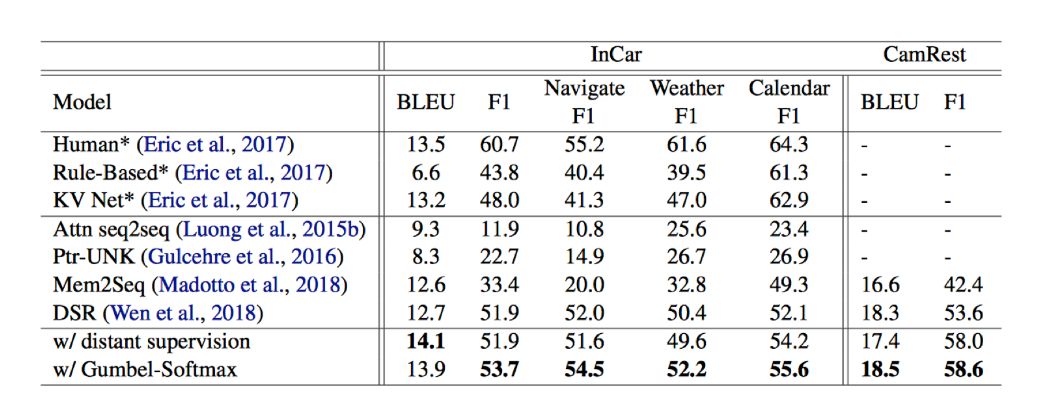
我们对比了基线模型,可以发现:
(1)在表1第一个方框中,我们显示了Eric等人报告的结果(带*)。我们认为,他们的结果不能直接比较,因为他们的工作使用的是标准化形式的实体,这些实体不是基于真实实体来计算的。但是我们的两种方法的框架在整体BLEU和Entity F方法上仍优于他们的模型的KV Net,这证明了我们框架的有效性。
(2)在表1的第二个方框中,我们可以看到我们的框架(远程监督和Gumbel-Softmax训练),击败了两个数据集上的基线模型。在InCar数据集中,我们的Gumbel-Softmax模型与基线相比具有最高的BLEU,这表明我们的框架可以产生更多的流畅回复。特别是,在F1指标上,我们的框架在Navigate域上实现了2.5%的改进,在Weather域上实现了1.8%的改进,在Calendar域上实现了3.5%的改进。这表明我们的KB检索器模块和框架的有效性可以从KB中检索更多正确的实体。在CamRest数据集中,也看到了相同的增长趋势,进一步表明了我们框架的有效性。
(3)我们观察到,用Gumbel-Softmax训练的模型好于远距离监督方法。我们归功于KB检索器和Seq2Seq模块以端到端的方式进行微调,这可以优化KB检索器并进一步促进对话的生成。
5.3 一行知识库能够支撑的回复比例
我们分析了实验的两套数据集,发现95%的Navigate领域,80%的天气领域和90%的Camrest数据集的生成回复中的实体可以由一行知识库支撑。这证明了我们一开始的假设。并且,我们研究了其余20%的weather领域,发现大部分回复不能由知识库的任意一行支撑,比如 “It ’s not rainy today”,知识库实体中只有Sunny,如果我们把这种情况也认为是一行知识库支撑,那么比例能够达到99%。
5.4 生成实体一致性
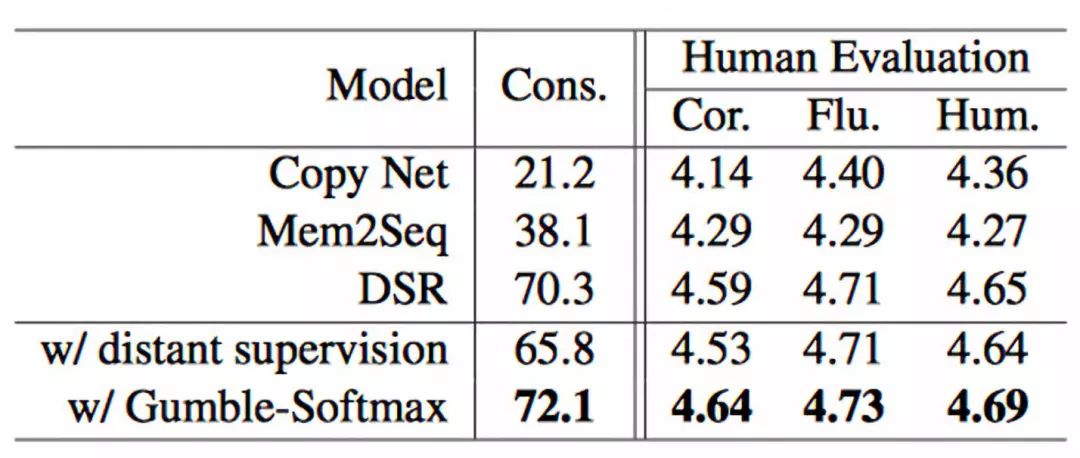
我们定义生成的回复实体如果是来自相同的一行知识库(由远程监督自动得到的结果),就认为他们是一致的,所有模型的一致性结果如表2左半部分:
表2 实体一致性结果与人工评价
5.5 知识库行数与生成一致性之间的相关性
为了进一步探讨知识库行数与回复实体一致性之间的相关性, 我们实验了1到5行知识库的回复生成。一致性结果如图12所示,我们可以看到随着知识库行数的增加,实体一致性在逐渐降低。这表明不相关的信息将损害对话生成的一致性。
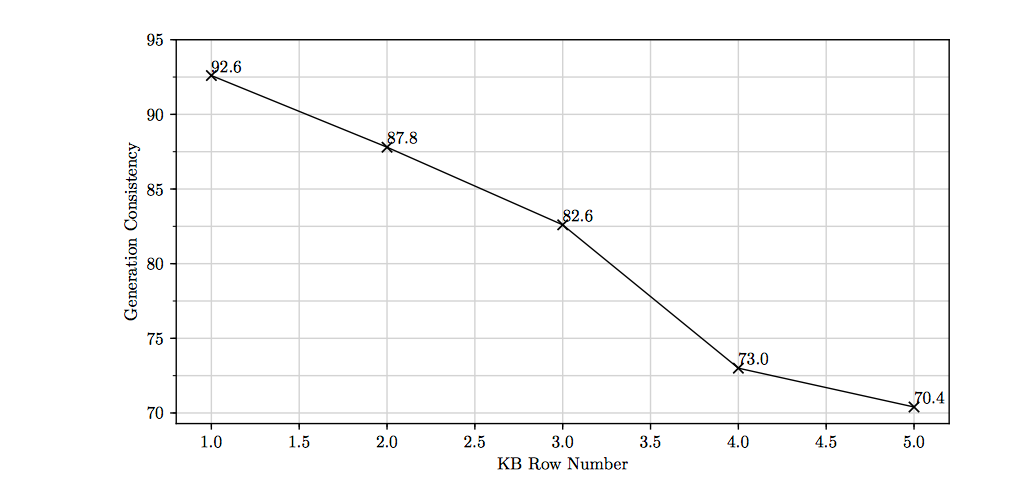
图12 知识库行数与回复一致性关系
5.6 可视化
我们在生成实体“Alester Ave 200”的解码位置上知识库实体概率可视化。从图13中,我们可以看到第4行和第1列具有生成200 Alester Ave的最高概率,这证明了首先选择最相关的知识库行然后进一步选择知识库列的有效性。
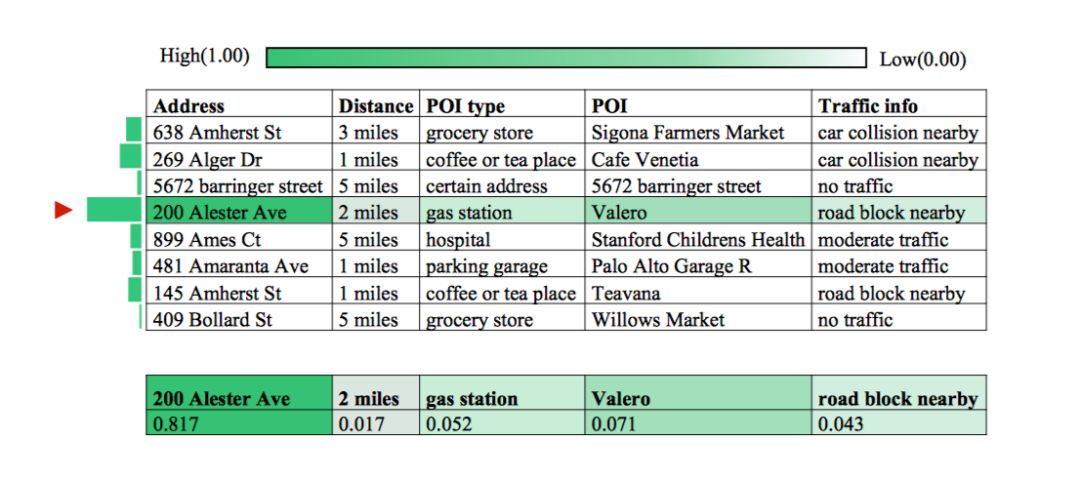
5.7 人工评价
我们最后还进行了人工评价,对生成的回复correctness,fluency, and humanlikeness三个方面进行打分,结果如表2右半部分所示。我们可以看出结果与自动评价一致,尤其是在正确性指标上远高于基线模型,证明我们框架的有效性。
6.结论
(1)我们首次在端到端任务型对话系统中研究实体一致性问题,并采用知识库检索器过滤不相关的知识库,用来提高实体一致性。
(2)我们提出使用远距离监督和Gumbel-Softmax方法来训练知识库检索器。
(3)我们在两个公开的任务的对话数据集上的实验结果表明:提出的模型优于基线模型并产生了更多实体一致的回复,这证明了我们模型的有效性。
参考文献
[1] Mihail Eric, Lakshmi Krishnan, Francois Charette, and Christopher DManning. 2017. Key-value retrieval networks for task-oriented dialogue.
[2] Andrea Madotto, Chien-Sheng Wu, andPascale Fung. 2018. Mem2seq: Effectively incorporating knowledge bases intoend-to-end task-oriented dialog systems.
[3] Haoyang Wen, Yijia Liu, Wanxiang Che,Libo Qin, and Ting Liu. 2018. Sequence-to-sequence learning for task-orienteddialogue with dialogue state representation.
[4] Sainbayar Sukhbaatar, Jason Weston, RobFergus, et al. 2015. End-to-end memory networks.
[5] Tsung-Hsien Wen, David Vandyke, NikolaMrkˇsi´c, Milica Gasic, Lina M. Rojas Barahona, Pei-Hao Su, Stefan Ultes, andSteve Young. 2017b. A network-based end-to-end trainable task-oriented dialoguesystem.


