ALBert: 轻量级Bert

最近要开始使用Transformer去做一些事情了,特地把与此相关的知识点记录下来,构建相关的、完整的知识结构体系,
以下是要写的文章,本文是这个系列的第六篇:
-
Transformer:Attention集大成者 -
GPT-1 & 2: 预训练+微调带来的奇迹 -
Bert: 双向预训练+微调 -
Bert与模型压缩 -
Bert与模型蒸馏:PKD和DistillBert -
ALBert: 轻量级Bert (本篇) -
MobileBert(待续) -
更多待续 -
Bert与AutoML (待续) -
线性Transformer (待续) -
Bert变种 -
Roberta: Bert调优 -
Reformer (待续) -
Longformer (待续) -
T5 (待续) -
更多待续 -
GPT-3 -
更多待续
背景
近年来,预训练的趋势从学习embedding变成了学习整个网络,即Word2vec到Bert的变迁。
另一个趋势则是大模型对最后的效果非常重要。而想要在真实的场景中使用,则需要小一些的模型,因而,知识蒸馏变得比较流行。
之前在卷积上,把层次加深到一定程度后如果没有结构上的创新(ResNet等)就不能再进一步提升效果。与之类似,在Bert上,把模型大小调整到一定程度也无法再继续使效果变好,反而会变差。如下图所示:


把hidden size从1024调整到2048会使得效果反而变差。
这个结论虽然在论文中得到了,但是没有考虑到数据的增长,后面有大量的论文通过增加数据训练更大的模型。
于是,ALBert中采用了三种手段来提升效果,其中,前两个方法通过模型上的改进降低了模型的大小。
-
Embedding矩阵分解 -
层次间的参数共享 -
损失函数添加句子顺序预测的loss
Embedding矩阵分解
原始的Bert,因为要做残差,所以每层的Hidden size都是一样的,同时也使得Embedding size和hidden size一样。但是,因为词表比较大,Bert中用的是3w的word piece,这样会导致模型的参数中,embedding会占一大部分。
从模型的角度来说,Embedding的参数学习的是上下文无关的表达,而Bert的模型结构则学习的是上下文相关的表达。在之前的研究成果中表明,Bert及其类似的模型的好效果更多的来源于上下文信息的捕捉,因而,embedding占据这么多的参数,会导致最终的参数非常稀疏。
因而,我们不用这么大的Embedding size,而是用一个较小的size,但是这样就没法在第一层去做残差了。没有关系,我们可以用另一个参数矩阵来把embedding size投射到hidden size上来。即假设V是词表大小,E是embedding size,H是hidden size,那么原始的Bert中E=H, 参数数目为VxH,而做了分解之后参数数据为VxE+ExH, 因为E远小于H,所以做了分解后这一部分的参数变少了很多。
层次间的参数共享
Bert的层次很深,至少在10层以上,这样,层次间的参数如果能共享的话,会使得参数量大大减少。
不仅如此,在共享了参数之后,会使得模型更加稳定,这方面的表现就是模型的每层的输入和输出之间的L2距离更小了。如下图所示:
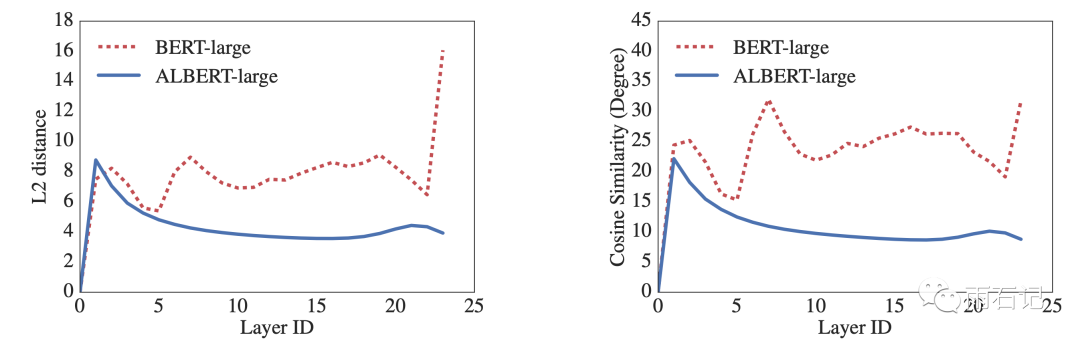
当然,关于参数共享,也有很多选项:
-
全部共享 -
只共享全连接层 -
只共享多头注意力层 -
不共享
句子顺序预测损失
在原始的Bert中,除了masked language model之外,还需要学习下一个句子的预测,在这个任务中,正例是两个连续的句子AB,反例则是两个句子AC,其中C来自于另外的文章。
这个loss已经在很多论文中被怀疑无效或者可以提升了。在论文中,怀疑它不好的原因就是它太简单了。于是,论文设计了一个更难的任务,即两个连续的句子AB,判断它是正序还是逆序,即是AB还是BA。
实验效果
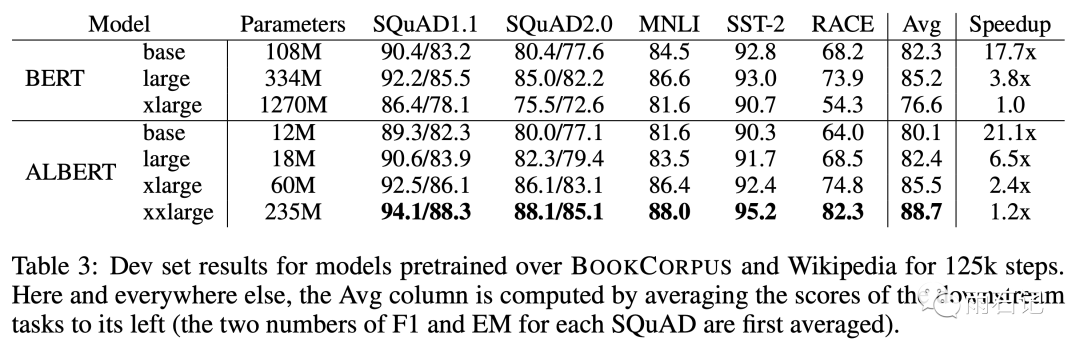
ALBERT和Bert的比较如下图,可以看到,相同的设置,ALBert比Bert略差,但是参数量会减少一个量级。可以看到,达到Bert-large的效果,ALBert-xlarge需要的参数从334M减少到了60M。
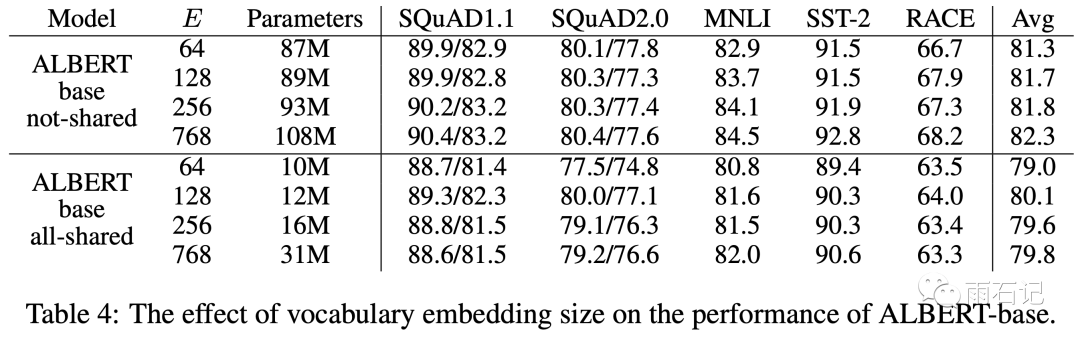
word embedding大小的影响如下图,可以看到在参数不共享的条件下,增大embedding可以带来微小的提升,在参数共享的条件下,embedding=128的时候反而最好。
参数共享设置的影响如下图。可以看到,全连接层的share带来的损失更大。

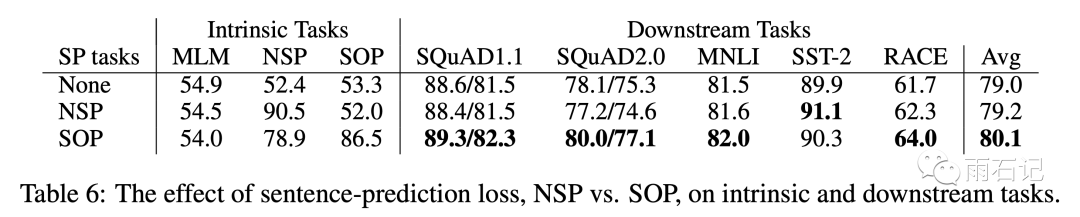
不同的句子损失的影响如下图,SOP是sentence order prediction的缩写。可以看到SOP训练好了,NSP结果自然也好,反之则没有。所以SOP是NSP的比较好的扩展。
除了论文的创新点的实验之外,论文中还有很多其他的实验结果。比如模型层次数目的影响:
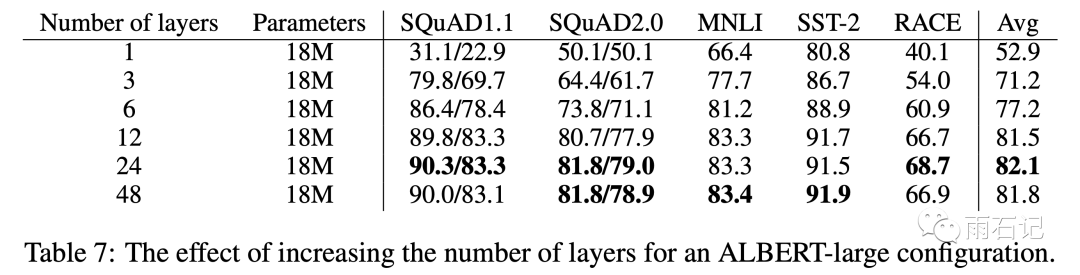
hidden size的影响:

相同训练时间下,Bert-large和AlBert-xxlarge的效果

在共享了参数之后,加到12层即可,没有必要加到24层了。

添加数据或者去掉dropout对模型训练的影响。
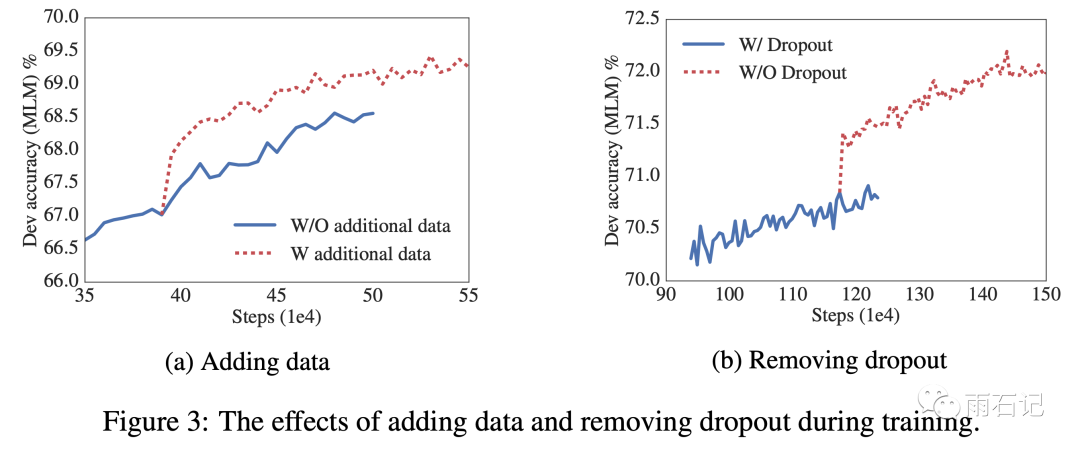
加入新数据的影响

去掉dropout的影响。

总结
虽然ALBert解决了模型大小的问题,但是计算量的问题并没有解决,因为层次间参数共享并不会省略计算。因而,这块还可以尝试sparse attention或者block attention等。
还可以通过hard example mining与more efficient language modeling training来进一步提升模型的表达能力。
虽然句子顺序预测效果不错,不过在这个方向上还有更多可以挖掘的地方。
参考文献
-
[1]. Lan Z, Chen M, Goodman S, et al. ALBERT: A lite BERT for self-supervised learning of language representations[J]. arXiv preprint arXiv:1909.11942, 2019.
-
[2]. Taku Kudo and John Richardson. SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pp. 66–71, Brussels, Belgium, November 2018. Association for Computational Linguistics. doi: 10.18653/v1/D18-2012. URL https://www.aclweb.org/anthology/D18-2012.
-
[3]. Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S Weld, Luke Zettlemoyer, and Omer Levy. SpanBERT: Improving pre-training by representing and predicting spans. arXiv preprint arXiv:1907.10529, 2019.

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏



