谷歌最新双塔DNN召回模型——应用于YouTube大规模视频推荐场景

“ 谷歌基于双塔DNN框架提出一个大规模最近邻召回系统,为降低采样偏差带来的影响,文章对batch softmax的损失函数进行了改进,同时从工程的角度介绍了大规模双塔DNN召回模型的训练、部署、应用等细节”
文章来源:https://zhuanlan.zhihu.com/p/128988454 点击文末【阅读原文】关注专栏及时获得更多更新!
一、创新点
1、文章将视频召回问题看做一个多分类问题,为解决全库数据量巨大难以高效快速训练的问题,文章采用采样的方式来处理实时流数据,同时提出一种新的算法用于估计某个视频从实时流中被采样的概率,这个概率用于对损失函数进行优化
2、文章基于双塔DNN框架提出一个大规模最近邻召回系统,为降低采样偏差带来的影响,文章对batch softmax的损失函数进行了改进
3、文章同时从工程的角度介绍了大规模双塔DNN召回模型的训练、部署、应用等细节
二、论文背景
本文提出的双塔DNN模型主要使用在类似于猜你喜欢这种场景下,即当你在YouTube上观看某个视频时,下方或者右侧会给你推荐一些其他的视频,这些视频会经过召回——排序——重排序等过程最终展现给用户,而如何从海量的候选视频库中精准的筛选出用户更加感兴趣的视频是论文主要关注的地方。
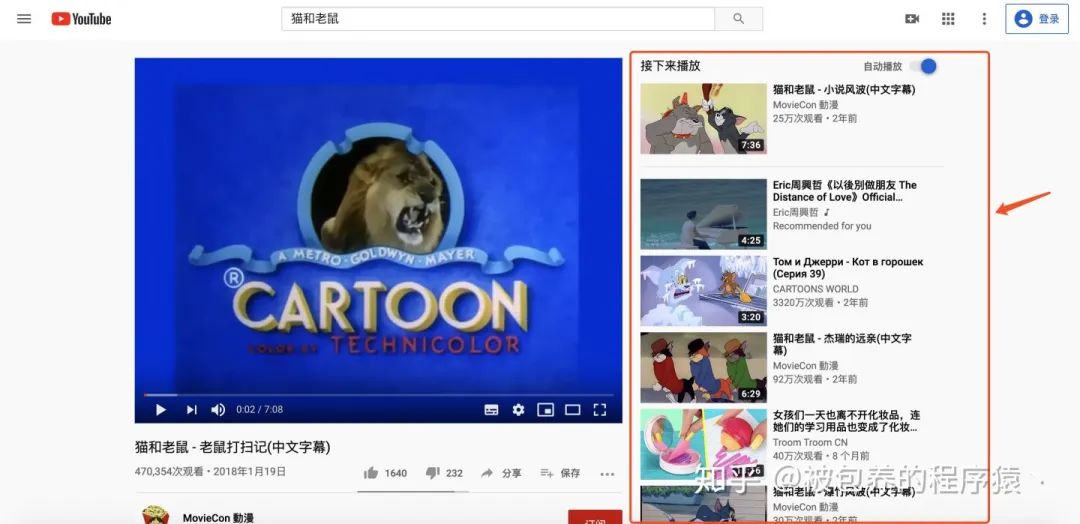
一般在推荐场景下,实时性是十分重要的,一些热点新闻、资讯、视频都需要及时的推送给用户。同时像YouTube这种用户量巨大的视频网站,如何在满足实时性的基础上,对海量的用户进行精准的个性化召回、排序与最终进行推荐是技术人员亟待解决的。YouTube将视频召回看做一个多分类问题,多分类问题中最常使用的激活函数就是softmax,但是要知道YouTube上视频素材库中的视频数量是巨大的,当类别数量特别大时,使用softmax来训练模型是比较耗时的。所以一种常用的方法就是进行采样,采样理所当然会有一定的偏差,无法保证采样后的分布和原始数据分布是一样的,这样模型学习到的将会是错误的分布从而影响模型的效果,所以文章一方面对损失函数进行了改进(加权对数似然函数),另一方面提出了一种对采样概率进行自适应修正的算法,
三、整体框架
「1、损失函数」
整个召回系统采用的是双塔结构,即分别构建请求侧的Embedding和视频侧的Embedding,两个塔的输出就为各自的embedding向量,最终模型的输出为两个Embedding内积后的结果,即
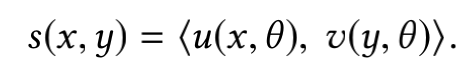
文章将视频召回看做一个多分类的问题,通常各个类别的权重都为1,但是在该场景中,文中引入了一个用户偏好的权重(用户观看某视频的时长),由于是多分类问题,将模型的输出经过一个softmax函数之后得到具体对应的label,softmax函数如下
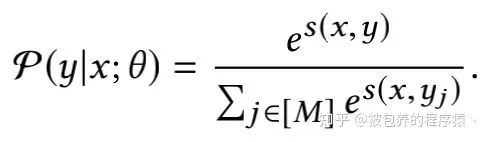
基于上述softmax函数的输出和用户偏好权重,损失函数采用加权对数似然函数的形式,具体如下
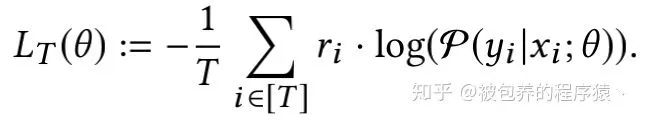
当视频素材库的视频数量巨大时(M非常大),计算上述的softmax函数是十分低效且不太现实的,所以一个常用的方法就是对全量的视频集合进行采样,传统的做法是训练所需的负样本从固定的集合中采样得到,但是论文中的做法是对实时流中的数据采样出一个batch,训练的负样本即这个batch中的负样本,但是这样就会引入偏差,即热门的一些视频有更大的可能成为负样本,所以文章对上文中两个embedding向量计算得到的内积进行了logQ修正,即
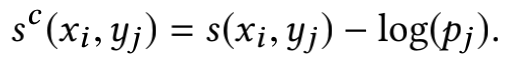
其中pj表示的是视频j被随机选中到batch中的采样概率。基于此经过修正后的softmax函数的输出以及修正后的损失函数如下所示
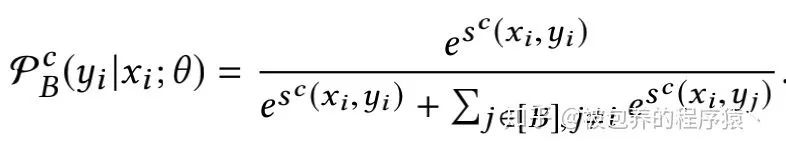
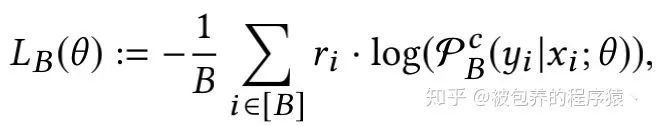
然后利用SGD即可进行参数的更新。具体的模型训练算法如下所示

「上述模型训练过程可以归纳为:」
(1)从实时数据流中采样得到一个batch的样本
(2)基于下文即将提到的采样概率估计算法得到采样概率pi
(3)计算上文介绍的修正后的损失函数
(4)利用SGD更新模型参数
「2、采样概率修正」
这部分主要对采样概率进行估计,这里的核心思想是假设某视频连续两次被采样的平均间隔为B,那么该视频的采样概率即为1/B,如果该商品上一次被采样的时刻为A的话,那么当该商品在时刻t被采样时,文章提出的算法利用A辅助更新B,即
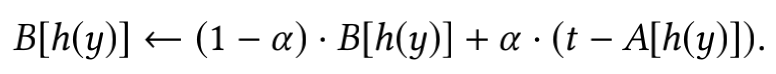
文章这里给出的是矩阵的形式,可以认为上式中的函数h()是一个hash函数,他将某个视频的id映射到具体的索引上,然后利用该索引从矩阵B和矩阵A中分别得到该商品对应的平均采样间隔和上一次该商品被采样的时刻,从而进行梯度更新。当B更新完之后,需要对A进行更新(将时刻t赋值给A)。整体采样频率检测算法如下所示

具体的证明过程可以参考论文中的描述,这里不做赘述
「3、其他」
(1)近邻搜索:当模型训练完成之后,我们首先可以对候选视频进行inference得到视频侧的embedding向量,并对这些embedding构建索引用于线上查询使用,当线上有用户侧的请求到来是,模型只需要首先对该用户进行预测得到请求侧的embedding,然后从构建好索引的视频侧embedding中检索出top视频即可,这里需要说明的是很难进行最近邻的搜索(线上耗时的考虑),所以会采用一些近似最近邻的检索算法或者方式进行处理
(2)归一化处理:文章提到对两个塔输出的embedding向量进行归一化处理后会有效果上的提升,同时对归一化后的内积值引入了一个超参数用来调整最终的输出
(3)模型分布式训练:论文中对模型分布式训练进行了简要的介绍,具体可以参考论文中的表述
(4)hash冲突:由于在采样频率估计中使用到了hash算法,会在一定程度上存在hash冲突的问题,为了解决该问题,文章提出了一种改进的采样频率估计算法,感兴趣的可以具体参考卢文中的介绍,具体改进算法如下

四、模型结构与线上部署
双塔DNN模型的结构与索引构建流程如下图所示,
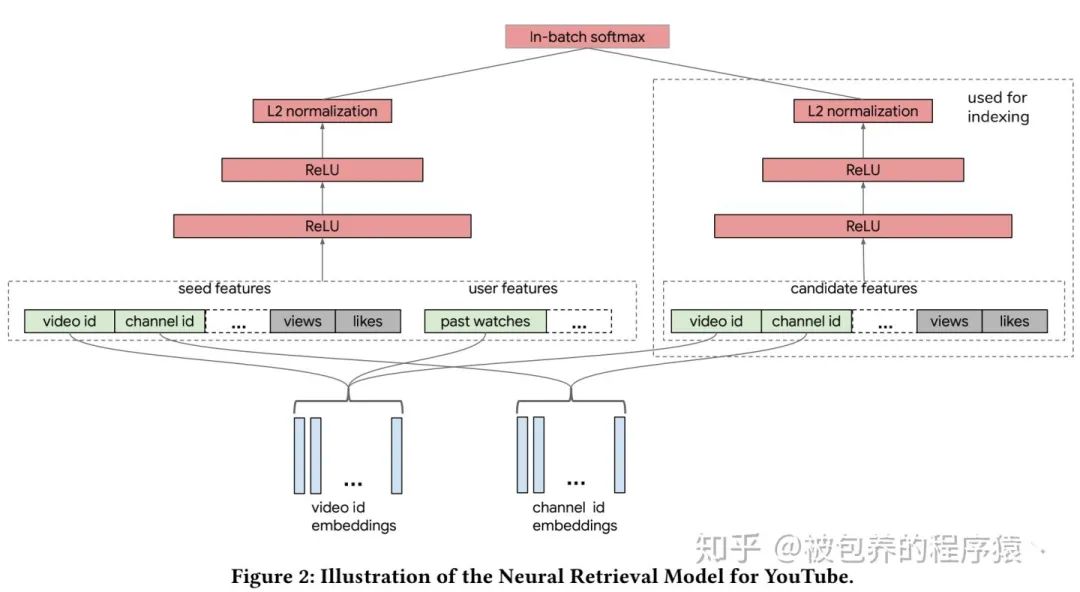
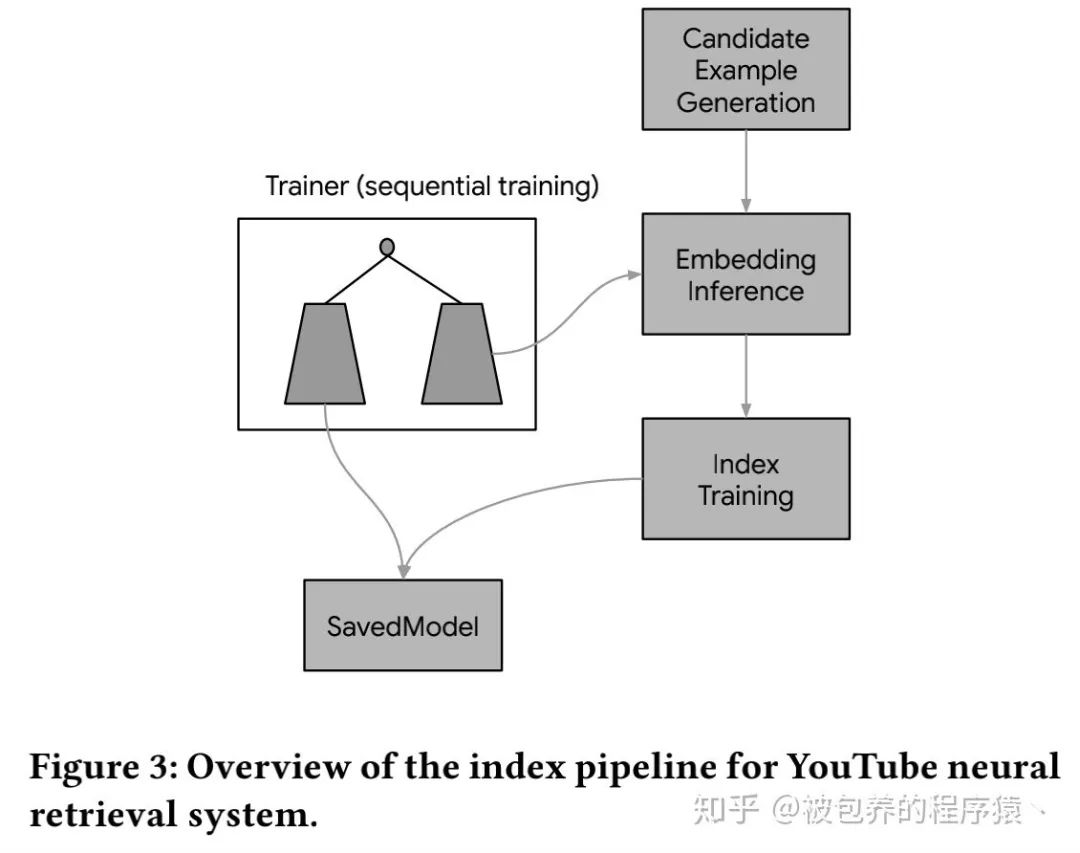
论文中对模型的结构、使用的特征进行的详细的介绍,都是一些比较常规的特征处理方法,具体可以详细参考论文中的描述,而且具体部署时候的方法与之前我们实际业务中的部署方案类似,感谢兴趣的可以同时参考下之前的文章。
五、实验结果
这里只贴出线上AB实验的效果,论文中还花了大量的篇幅对其他的超参数进行了详细的分析与对比,具体可以参考论文中的分析。线上A/B Test的结果如下图所示

plain-sfx表示不通过概率对采样偏差进行修正,correct-sfx表示修正采样偏差,可以看到修正后效果更为显著。
六、总结
论文详细介绍了工业界应用双塔DNN模型解决大规模视频召回场景下的问题,同样是一篇工程性很强的论文。相信很多人对双塔DNN模型并不陌生,也有很多公司实际在这么做(也包括我所在的公司),但是文章中提到的很多细节问题可能是我们平时所忽略的(国内公司快糙猛,有效果就赶紧上线,之后再看要不要迭代优化),比如对embedding进行归一化处理、对embedding内积引入修正系数、线上如何进一步提高检索效率等。所以如果真的需要在实际业务中应用类似的架构设计,推荐大家去看一下原始的论文。
参考资料
推荐阅读
百度PaddleHub NLP模型全面升级,推理性能提升50%以上
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
From Word Embeddings To Document Distances 阅读笔记
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
可解释性论文阅读笔记1-Tree Regularization
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。


