业界 | 苹果发文:全局语义信息能否改进神经语言模型?
选自machinelearning.apple
机器之心编译
参与:Huiyuan Zhuo、路
用于训练词嵌入的大多数技巧是捕捉给定词在句子中的局部上下文,但当涉及全局语义信息时,此类嵌入的表达能力有限。然而,目前基于局部上下文训练的词嵌入仍然是主流,那么使用全局语义信息能否改善神经语言模型呢?苹果的框架自然语言处理团队对此进行了探讨。全局语义上下文能否改善 QuickType 键盘的词预测?苹果是否会将这一技术应用于实际生产?
在 iPhone 上输入文本、发掘用户可能感兴趣的新闻、查明用户遇到问题的答案,以及其他语言相关的任务都取决于稳健的自然语言处理(NLP)模型。词嵌入是一类 NLP 模型,它在数学上将词映射为数值向量。这种能力使得找到数值相似的向量或向量簇变得非常简单,而后通过反向映射来得到相关的语言信息。这些模型是 News、搜索、Siri、键盘和 Maps 等常见应用程序的核心。本文将探讨能否通过全局语义上下文(global semantic context)改善 QuickType 键盘的词预测。
简介
你应该通过上下文去了解一个词。
——语言学家 John Rupert Firth
如今,用于训练词嵌入的大多数技巧是捕捉给定词在句子中的局部上下文,也就是一个包含在所讨论词之前和之后相对少量(比如说 5 个)词的窗口。例如,在《美国独立宣言》中,词「self-evident」就拥有局部上下文,词左边是「hold these truths to be」,右边是「that all men are created」。
本文介绍了这种方法的扩展版本,它是捕捉文档的整个语义上下文,例如整本《独立宣言》。这种全局语义上下文能否改善语言模型?我们首先来看目前词嵌入的使用情况。
词嵌入
以无监督方式训练的连续空间词嵌入对于各种自然语言处理(NLP)任务是非常有用的,如信息检索 [1]、文档分类 [2]、问答 [3] 和联结主义语言建模 [4]。最基本的嵌入基于 1-N 编码,即大小为 N 的基础词汇表中的每个词都由 N 维稀疏向量来表示(词的索引为 1,其他为 0)。更复杂的嵌入是将词映射为低维连续空间上的密集向量。在维度减少的过程中,映射有效地采集到词一定量的语义、语法和语用信息。计算向量间的距离然后生成词的相似性度量,这些都是无法仅仅通过词本身去直接计算的。
有两种基本的降维词向量类型:
从词的局部上下文生成的表示(如前 L 个词和后 L 个词,其中 L 通常是一个小的整数)。
利用词的全局上下文生成的表示(如它所在的整个文档)。
利用局部上下文的方法有:
使用神经网络架构的基于预测的方法 [5],如连续词袋模型和 skip-gram 模型。
源自联结主义语言建模的投影层技术 [6]。
使用自编码器配置的瓶颈表示 [7]。
利用全局上下文的方法有:
全局矩阵分解法,如潜在语义映射(latent semantic mapping,LSM),它使用词—文档共现数 [8]。
对数线性回归建模,如 GloVe,它使用词—词共现数 [9]。
像 LSM 这样的全局共现计数法会形成被认为是真正语义嵌入的词表示,因为它们公开了统计信息,而这些信息采集了整个文档传达的语义概念。相比之下,使用神经网络的基于预测的典型解决方案仅封装了语义关系,它们在一个以每个词为中心的局部窗口中出现(这是预测中使用的所有内容)。因此,当涉及全局语义信息时,由此类解决方案产生的嵌入本身的表达能力有限。
尽管有这种限制,研究人员仍然更多地采用基于神经网络的嵌入。特别是连续词袋模型和 skip-gram(线性)模型,因为它们能够传达与「king is to queen as man is to woman」同一类型的词类比。因为基于 LSM 的方法大多无法呈现这样的词类比,所以普遍的观点是,由于向量空间的单个维度缺乏精确的含义,基于 LSM 的方法产生了一个次优的空间结构。
这种认识促使我们探索基于深度学习的替代方案能否比现有的 LSM 方法表现得更好。我们特别研究了是否可以通过使用不同类型的神经网络架构来实现更强大的语义嵌入。
在下一节中,我们将讨论在 Apple QuickType 键盘上使用这些嵌入提高预测准确率所涉及的挑战。我们回顾了我们所采用的双向长短期记忆架构(bi-LSTM)。然后介绍了这种架构获得的语义嵌入,及其在神经语言建模中的用途。最后,我们讨论了从中获得的见解以及对未来发展的看法。
神经架构
创建词嵌入最有名的框架之一是 word2vec。我们决定研究一种可以提供全局语义嵌入的神经网络架构,因此我们选择 bi-LSTM 循环神经网络(RNN)架构。此方法允许模型访问过去、现在与未来的输入信息,从而使得模型能够采集全局上下文。
我们设计了这个架构,使之能够接受多达一个完整文档的输入。至于输出,它提供与文档相关联的语义类别,如图 1 所示。生成的嵌入不仅采集了词的局部上下文,该采集了输入的整个语义结构。
该架构解决了两个主要障碍。第一个障碍是对围绕每个词的有限大小窗口中包含的局部上下文的限制,这个窗口用来预测输出标签。通过转换为嵌入计算的双向循环实现,该架构原则上能够容纳无限长度的左右上下文。这样不仅可以处理句子,还可以处理整个段落,甚至是一整个文档。
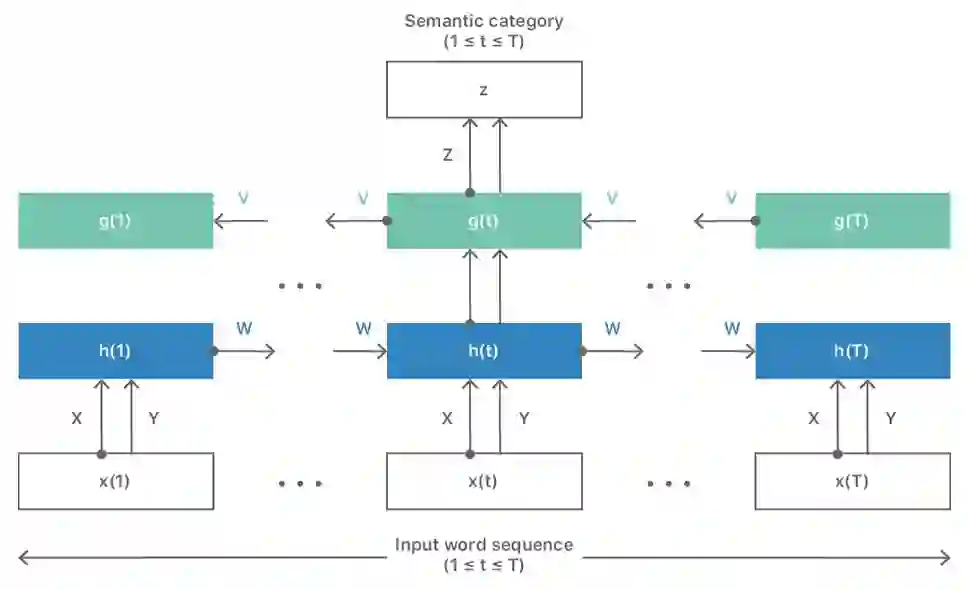
图 1:全局语义嵌入的 RNN 架构。
第二个障碍与预测目标本身有关。到目前为止,所有的神经网络解决方案都可以预测上下文中的词或局部上下文,而这并不能充分反映全局语义信息。相反,图 1 所示架构直接从输入文本预测全局语义类别。为了简化语义标签的生成过程,我们发现去获得合适的聚类类别更加方便,例如,从使用 LSM [8] 获得的初始词—文档嵌入中获得聚类类别。
让我们仔细看看该网络是如何运作的。假设当前所考虑的文本块(无论是句子、段落还是整个文档)由 T 个词组成 x(t),1 ≤ t ≤ T,并且与语义类别 z 全局相关。我们把这个文本块作为双向 RNN 架构的输入。
输入文本中的每个词 x(t) 使用 1-N 编码进行编码,因此,x(t) 是 N 维的稀疏向量。左边上下文的 H 维向量 h(t-1) 包含左边上下文的内部表示,它来自于前一个时间步的隐藏层中的输出值。右边上下文的 H 维向量 g(t+1) 包含下一个时间步的隐藏层中的右边上下文输出值。该网络在当前时间步计算隐藏节点的输出值:
h(t)=F{X⋅x(t)+W⋅h(t−1)}
g(t)=F{Y⋅x(t)+V⋅g(t+1)}
其中:
F{·} 表示激活函数,如 sigmoid、双曲正切或线性修正单元。(或者,纯线性激活函数可用来确保在词类比上的良好性能。)
s(t) 表示网络状态,它是左右上下文隐藏节点的级联:s(t) = [g(t) h(t)],维度是 2H。将此状态看作是维度 2H 的向量空间中的词 x(t) 的连续空间表示。
该网络的输出是与输入文本相关联的语义类别。因此,在每个时间步中,对应于当前词的输出标签 z 被编码为 1-K,通过以下公式计算并获得:
z=G{Z⋅[g(t)h(t)]}
其中:
G{·} 表示 softmax 激活函数
在训练该网络时,我们假设有一组可用的语义类别注释。如前所述,这些注释可能来自于使用 LSM 获得的初始词—文档嵌入。
为了避免典型的梯度消失问题,我们使用 LSTM 或门控递归单元(GRU)作为隐藏节点。此外,你可以根据需要将图 1 所示的单个隐藏层扩展到任意复杂的、更深的网络。例如,两个堆叠的 RNN 或 LSTM 网络在许多应用上取得了良好的表现,如语种识别。
语义词嵌入
对于基础词汇表中的每个词,给定每个文本块(句子、段落或文档),我们要寻找的词表示是与该词相关的已训练网络的状态。当词只出现在一个文本中时,我们使用对应的向量(维度是 2H)。如果一个词出现在多个文本中,我们相应地求所有相关向量的平均值。
与 LSM 一样,与特定语义类别密切相关的词倾向于和代表该语义类别的维度一致。相反,功能词(即「the」、「at」、「you」这样的词)倾向于聚集在向量空间的原点附近。
注意,可以通过迭代所获得的连续语义嵌入和你想实现的语义粒度来细化初始语义类别集。
词表外(OOV)的词需要特殊处理,因为它们超出了 1—N 编码范例。一种可能方法是为 OOV 分配一个额外的维度,使得输入维度变为 1-(N+1)。网络的其余部分保持不变。这样的话,维度 2H 的单个向量最终是任意 OOV 词的表示。
神经语言建模
在最初的实验中,我们在一个约 7000 万词、维度 2H 为 256 的专用段落语料库中训练语义嵌入。然而,我们发现,即使在长度标准化的条件下,仍然难以处理每个输入段落的长度显著变化的情况。此外,在段落数据上训练词嵌入与在句子数据上训练语言模型之间的不匹配似乎超过了添加全局语义信息带来的好处。这与我们之前的观察一致,即任何嵌入都是在将使用的确切数据类型上训练得最好。通常,数据驱动的词嵌入在任务中并不是可移植的。
因此我们决定在用于训练 QuickType 预测类型神经语言模型的(句子)语料库的一个子集上训练嵌入。然后,我们在标准语言建模测试数据集上测量嵌入的质量,如表 1 所示。符号「1-of-N」表示我们的标准稀疏嵌入,而「word2vec」表示在大量数据上训练的标准 word2vec 嵌入。

表 1:语言建模测试集上的困惑度结果(训练语料库的大小有变化,如图所示)。
我们惊讶地发现,在少量数据上训练的 bi-LSTM 嵌入与在更大(7 倍以上)数据上训练的 word2vec 嵌入表现差不多。类似地,bi-LSTM 嵌入与在更大(5000 倍以上)数据上训练的 one-hot 向量表现得一样好。因此,我们提出的方法十分适合那些收集大量训练数据耗时且昂贵的应用。
结论
我们评估了将全局语义信息纳入神经语言模型中的潜在好处。由于这些模型本身是为局部预测而设计优化的,因此它们无法正确利用可能十分相关的全局信息。利用全局语义信息通常有利于神经语言建模。然而,正如我们所发现的那样,这种方法需要解决段落数据上训练的词向量与句子数据上训练的语言模型之间的长度不匹配问题。
我们认为解决这个问题最好的办法是修改语言模型训练中使用的客观标准,这样我们就可以在同一段落数据上同时训练嵌入和语言模型。目前,我们正在试验一个多任务目标,以同时预测语义类别(用来训练语义嵌入)和下一个词(用来训练神经语言模型)。
总之,使用 bi-LSTM RNN 训练全局语义词嵌入确实可以提高神经语言建模的准确率。它还可以大大减少训练所需的数据量。
在未来,我们认为多任务训练框架有可能通过利用局部和全局语义信息来实现两全其美。

参考文献
[1] C.D. Manning, P. Raghavan, and H. Schütze. Introduction to Information Retrieval. Cambridge University Press, 2008.
[2] F. Sebastiani. Machine Learning in Automated Text Categorization. ACM Computing Surveys, vol. 34, pp. 1–47, March 2002.
[3] S. Tellex, B. Katz, J. Lin, A. Fernandes, and G. Marton. Quantitative Evaluation of Passage Retrieval Algorithms for Question Answering. Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 41–47, July–August 2003.
[4] H. Schwenk. Continuous Space Language Models. Computer Speech and Language, vol. 21, issue 3, pp. 492–518, July 2007.
[5] T. Mikolov, W.T. Yih, and G. Zweig. Linguistic Regularities in Continuous Space Word Representations. Proceedings of NAACL-HLT 2013, June 2013.
[6] M. Sundermeyer, R. Schlüter, and H. Ney. LSTM Neural Networks for Language Modeling. InterSpeech 2012, pp. 194–197, September 2012.
[7] C.Y. Liou, W.C. Cheng, J.W. Liou, and D.R. Liou. Autoencoder for Words.Neurocomputing, vol. 139, pp. 84–96, September 2014.
[8] J.R. Bellegarda. Exploiting Latent Semantic Information in Statistical Language Modeling. Proceedings of the IEEE, vol. 88, issue 8, pp. 1279–1296, August 2000.
[9] J. Pennington, R. Socher, and C.D. Manning. GloVe: Global Vectors for Word Representation. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp 1532–1543, October 2014.
原文链接:https://machinelearning.apple.com/2018/09/27/can-global-semantic-context-improve-neural-language-models.html
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


