ASP.NET Core 3.0中支持AI的生物识别安全
(给DotNet加星标,提升.Net技能)
转自: Stefano Tempesta msdn.microsoft.com/zh-cn/magazine/mt833460
本文共两个部分,这是第一部分,其中介绍了 ASP.NET Core 3 中旨在将授权逻辑与基本的用户角色相分离的基于策略的授权模型。
此部分提供了此授权进程的基于生物识别信息(如人脸识别或语音识别)的具体示例。
在此示例中,检测到未经授权的入侵时,将限制进入建筑。
Azure 机器学习内置的异常检测服务将评估入侵的严重性。
进入场地
上下文是受高度保护的场地 - 如军区、医院或数据中心。通过一些限制来仅允许已授权的人员进入。下列步骤说明了在各个门口执行的用于进行人员签入的安全流:
要求进入建筑的人员在门口的读卡器上刷其访问通信证。
摄像头检测手势,并捕获此人的面部和肢体;此过程应防止使用诸如打印的照片之类的来欺骗仅具有人脸识别的摄像头。
读卡器和摄像头注册为物联网 (IoT) 设备,并将录制的数据流式传输到 Azure IoT 中心。
Microsoft 认知服务将此人与已授权进入建筑的人员数据库进行比较。
授权流将 IoT 设备采集的生物识别信息与访问通信证上的人员身份进行匹配。
调用 Azure 机器学习服务来评估访问申请的风险级别,并评估是否属于未经授权的入侵。
ASP.NET Core Web API 核对前面的步骤中定义的配置文件包含的特定策略要求,并授予权限。
若检测到的人员身份与访问通信证不一致,将立即阻止其进入场地。反之,流查看是否存在下面的任何异常,并继续操作:
进入建筑的频率异常。
此人之前是否曾进入此建筑(签出)。
每日允许的访问次数。
此人是否值班。
建筑的关键性(可能无需限制对餐厅的访问,但要对服务器数据中心访问执行严格的策略)。
此人是否带领其他人或携带其他物品同行。
同一个建筑发生过的类似访问异常。
过去评估的风险级别的变化。
过去检测到的入侵次数。
Azure 机器学习运行异常检测服务,此服务返回评分来表示访问偏离标准值的可能性。
使用 0 到 1 之间的数值表示此评分,其中 0 表示“未检测到风险”、一切正常、已受到完全信任;1 表示“红色警报”,要立即阻止进入!对于大于 0 的任意值,由各个建筑的风险级别决定用于允许进入建筑的可接受阈值。
ASP.NET Core 中的授权
ASP.NET Core 提供简单的授权声明性角色和丰富的基于策略的模型。使用要求表示授权,由处理程序针对这些要求评估用户的声明。
为说明如何向要访问场地的用户授权,下文将介绍如何生成自定义策略要求以及其授权处理程序。
有关 ASP.NET Core 中的授权模型的详细信息,请参阅 bit.ly/2UYZaJh 中的文档。
如上所述,自定义的基于策略的授权机制由要求和(通常情况下)授权处理程序组成。授权访问建筑包括调用打开入口门锁的 API。
IoT 设备将生物识别信息流式传输到 Azure IoT 中心,进而通过发送场地 ID(场地的唯一标识符)触发验证工作流。
若验证成功,Web API POST 方法仅返回 HTTP 代码 200 及包含用户名和场地 ID 的 JSON 消息。反之,它引发相应的 HTTP 401“访问未经授权”错误代码。
接下来我们按顺序操作:从 Web API 的 Startup 类开始,ConfigureServices 方法尤为重要,其中包含配置所需服务以运行 ASP.NET Core 应用程序的说明。
在服务对象上调用 AddAuthorization 方法,以添加授权策略。
调用 AddAuthorization 方法以授权其执行时,它接受 API 函数必须拥有的策略集合。在本示例中,仅需要一个策略,我们称其为“AuthorizedUser”。
但是此策略包含多个要满足的要求,它们反映了要验证的人员的生物特性:面部、肢体和声音。
这三个要求分别由实现 IAuthorizationRequirement 接口的特定类表示,如图 1 所示。列出 AuthorizedUser 策略的要求时,还指定了满足要求所需的可信度。
如前文所述,此值介于 0 和 1 之间,并且表示相应的生物属性识别的准确性。
稍后在探讨使用认知服务进行生物识别时,我们将继续介绍它。
图 1 Web API 中的授权要求的配置
public void ConfigureServices(IServiceCollection services)
{
var authorizationRequirements = new List<IAuthorizationRequirement>
{
new FaceRecognitionRequirement(confidence: 0.9),
new BodyRecognitionRequirement(confidence: 0.9),
new VoiceRecognitionRequirement(confidence: 0.9)
};
services
.AddAuthorization(options =>
{
options.AddPolicy("AuthorizedUser", policy => policy.Requirements =
authorizationRequirements);
})
AuthorizedUser 授权策略包含多个授权要求,必须满足所有要求才能使策略评估成功。换言之,按照 AND 原则处理添加到单个授权策略的多个授权要求。
在此解决方案中实现的三个策略要求都是实现 IAuthorizationRequirement 接口的类。此接口实际为空;也就是说,它不指示任何方法的实现。
一致通过以下方式实现这三个要求:指定 ConfidenceScore 公共属性来捕获若要视为此要求“成功”识别 API 应达到的预期可信度。
FaceRecognitionRequirement 类如下所示:
public class FaceRecognitionRequirement : IAuthorizationRequirement
{
public double ConfidenceScore { get; }
public FaceRecognitionRequirement(double confidence) =>
ConfidenceScore = confidence;
}
以同样的方式分别在 BodyRecognitionRequirement 和 VoiceRecognitionRequirement 类中实现针对肢体和语音识别的其他要求。
通过授权属性控制对执行 Web API 操作的授权。简而言之,通过向控制器或操作应用 AuthorizeAttribute,来将该控制器或操作的访问权限限制在所有已授权用户范围内。控制场地访问的 Web API 公开单个访问控制器,其中仅包含 Post 操作。
若已满足指定的“AuthorizedUser”策略中的所有要求,将向此操作授权:
[ApiController]
public class AccessController : ControllerBase
{
[HttpPost]
[Authorize(Policy = "AuthorizedUser")]
public IActionResult Post([FromBody] string siteId)
{
var response = new
{
User = HttpContext.User.Identity.Name,
SiteId = siteId
};
return new JsonResult(response);
}
}
由授权处理程序管理各个要求,如图 2 中所示,它负责评估策略要求。可以选择让所有要求共用单个处理程序,也可以选择让各个要求拥有单独的处理程序。
后面的方式更为灵活,因为它允许配置渐变的授权要求,这样就可以轻松地在 Startup 类中配置它们。
面部、肢体和声音要求处理程序扩展 AuthorizationHandler<TRequirement> 抽象类,其中 TRequirement 是要处理的要求。
由于要评估三个要求,因此需要编写自定义处理程序来分别扩展 FaceRecognitionRequirement、BodyRecognitionRequirement 和 VoiceRecognitionRequirement 的 AuthorizationHandler。
具体而言,由 HandleRequirementAsync 方法决定是否满足授权要求。由于此方法为异步方法,因此它不返回实际值,指示任务已完成时除外。
处理授权包括在授权处理程序上下文上调用 Succeed 方法以将要求标记为“成功”。
此过程实际上由“识别器”对象验证,它在内部使用认知服务 API(详见下一部分)。
识别方法执行的识别操作获取所识别人员的姓名,并返回一个值(评分)来可信度,即识别准确度高(值接近 1)或准确度低(值接近 0)。
在 API 设置中指定了预期 API。可以将此值调整为任何适用于解决方案的阈值。
图 2 自定义授权处理程序
public class FaceRequirementHandler :
AuthorizationHandler<FaceRecognitionRequirement>
{
protected override Task HandleRequirementAsync(
AuthorizationHandlerContext context,
FaceRecognitionRequirement requirement)
{
string siteId =
(context.Resource as HttpContext).Request.Query["siteId"];
IRecognition recognizer = new FaceRecognition();
if (recognizer.Recognize(siteId, out string name) >=
requirement.ConfidenceScore)
{
context.User.AddIdentity(new ClaimsIdentity(
new GenericIdentity(name)));
context.Succeed(requirement);
}
return Task.CompletedTask;
}
}
除了评估特定要求,授权处理程序还为当前用户添加身份声明。生成身份后,可以为它分配一个或多个由受信任方发布的声明。声明是表示主体身份的姓名-值对。
在此示例中,将为上下文中的用户分配身份声明。
然后在访问控制器的 Post 操作中检索此声明,并将其作为 API 响应的一部分返回。
启用此自定义授权进程的最后一个步骤是注册 Web API 内的处理程序。进行配置时,在服务集合中注册处理程序:
services.AddSingleton<IAuthorizationHandler, FaceRequirementHandler>();
services.AddSingleton<IAuthorizationHandler, BodyRequirementHandler>();
services.AddSingleton<IAuthorizationHandler, VoiceRequirementHandler>();
此代码使用 ASP.NET Core 的内置依存关系注入 (DI) 框架将各个要求处理程序注册为单一实例。启动应用程序时,将生成此处理程序的实例,依存关系注入将注册的类注入到相关对象。
人脸识别
此解决方案将 Azure 认知服务用于视觉 API,来识别人的面部和肢体。有关认知服务及此 API 的详细信息,请参阅 bit.ly/2sxsqry。
视觉 API 提供人脸属性检测和人脸验证。人脸检测指从图像中检测人脸的功能。
此 API 返回所处理的图像中人脸位置的矩形坐标,还可以提取一系列与人脸相关的属性,如头部姿势、性别、年龄、表情、面部毛发和眼镜。
人脸验证与之相反,它针对人员的预保存人脸验证检测到的人脸。它实际上是在评估两个人脸是否属于同一个人。这是用于此安全项目的特定 API。
请将下面的 NuGet 包添加到 Visual Studio 解决方案,以开始使用:Microsoft.Azure.CognitiveServices.Vision.Face 2.2.0-preview
.NET 托管的包处于预览状态,因此在浏览 NuGet 时务必选中“包括预发行版”选项,如图 3 所示

图 3 人脸 API 的 NuGet 包
.NET 包、人脸检测和人脸识别的用法非常简单。大体而言,人脸识别说明了比较两个不同的人脸以确定它们是否相似或是否属于同一个人的工作过程。识别操作主要使用图 4 列出的数据结构。
图 4 人脸 API 的数据结构
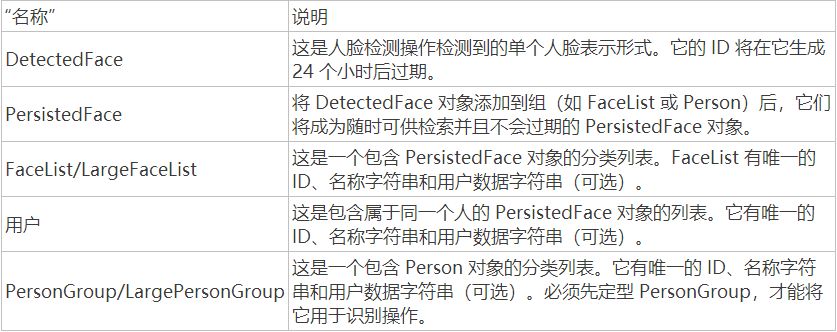
验证操作从在图像中检测到的人脸列表(DetectedFace 集合)提取人脸 ID,并将此 ID 与保存的人脸 (PersistedFace) 集合进行比较,来确定这些人脸是否属于同一个人。保存的人脸图像使用唯一的 ID 和名称标识某个人员。
可以选择将一组人员收集到一个 PersonGroup 中,以便改进识别性能。从根本上说,一个人员就是一个基本的身份单位,一个人员对象可以注册一个或多个已知的人脸。
在一个特定的 PersonGroup(人员集合)中定义各个人员,并基于 PersonGroup 完成识别。
安全系统将创建一个或多个 PersonGroup 对象,然后将人员与这些对象关联。
生成组后,必须先定型 PersonGroup 集合,然后才能使用它执行验证。
此外,在添加或删除任何人员或编辑任何人员已注册的人脸后,必须重新定型此集合。由 PersonGroup 定型 API 完成定型。
如果使用的是客户端库,此过程只是对 TrainPersonGroupAsync 方法的调用:
await faceServiceClient.TrainPersonGroupAsync(personGroupId);
定型是异步进程。即使 TrainPersonGroupAsync 方法已返回,此进程可能仍未完成。需要使用 GetPersonGroupTrainingStatusAsync 方法查询定型状态,直至已准备就绪,才可继续执行人脸检测或验证。
执行人脸验证时,人脸 API 计算检测到的人脸与组内所有人脸的相似度,并返回与该测试人脸相似度最高的人员。通过客户端库的 IdentifyAsync 方法完成此过程。需要使用上述步骤检测测试人脸,然后将人脸 ID 作为第二个参数传递到识别 API。
一次可以识别多个人脸 ID,结果将包含所有识别结果。默认情况下,识别仅返回一个与测试人脸匹配度最高的人员。
如有必要,可以指定可选参数 maxNumOfCandidatesReturned,来让识别返回多个候选人。图 5 中的代码演示了识别和验证人脸的过程:
图 5 人脸识别过程
public class FaceRecognition : IRecognition
{
public double Recognize(string siteId, out string name)
{
FaceClient faceClient = new FaceClient(
new ApiKeyServiceClientCredentials("<Subscription Key>"))
{
Endpoint = "<API Endpoint>"
};
ReadImageStream(siteId, out Stream imageStream);
// Detect faces in the image
IList<DetectedFace> detectedFaces =
faceClient.Face.DetectWithStreamAsync(imageStream).Result;
// Too many faces detected
if (detectedFaces.Count > 1)
{
name = string.Empty;
return 0;
}
IList<Guid> faceIds = detectedFaces.Select(f => f.FaceId.Value).ToList();
// Identify faces
IList<IdentifyResult> identifiedFaces =
faceClient.Face.IdentifyAsync(faceIds, "<Person Group ID>").Result;
// No faces identified
if (identifiedFaces.Count == 0)
{
name = string.Empty;
return 0;
}
// Get the first candidate (candidates are ranked by confidence)
IdentifyCandidate candidate =
identifiedFaces.Single().Candidates.FirstOrDefault();
// Find the person
Person person =
faceClient.PersonGroupPerson.GetAsync("", candidate.PersonId).Result;
name = person.Name;
return candidate.Confidence;
}
首先需要传递订阅密钥和 API 终结点,来获取人脸 API 的客户端对象。可以从预配人脸 API 服务的 Azure 门户中获取这两个值。然后检测图像中显示的任何人脸,并作为流传递到客户端人脸对象的 DetectWithStreamAsync 方法。
人脸对象实现人脸 API 的检测和验证操作。在检测的人脸中,确保实际只检测一个人脸,并获取其 ID(它是已注册人脸集合中的唯一标识符,该集合中的所有人员已被授权访问该场地)。
然后 IdentifyAsync 方法在 PersonGroup 中识别检测到的人脸,并返回按可信度排序的最佳匹配或候选人列表。通过第一个候选人的人员 ID 检索人员姓名,并且最终会将此姓名返回到访问 Web API。人脸授权要求已满足。
语音识别
Azure 认知服务说话人识别 API 提供说话人验证和说话人识别算法。
声音具有唯一的特性,可以像使用指纹一样将它们用于人员识别。本文中的安全解决方案将语音作为访问控制信号,在此方案中主体通过语音将通行短语输入到已注册为 IoT 设备的麦克风。与人脸识别一样,语音识别也需要预注册已授权的人员。
说话人 API 将已注册人员称为“个人资料”。 注册个人资料时,将录制说话人陈述特定短语时的语音,然后提取一些特性,并识别已选定的短语。提取的特性和已选定的短语共同构成了唯一的语音签名。进行验证时,将输入语音和短语与注册语音签名和短语进行比较,来验证它们是否来自同一个人,以及短语是否正确。
从代码实现可以看出,不同于人员 API,说话人 API 并未从 NuGet 中的托管包受益,因此我们将采用直接使用 HTTP 客户端请求和响应机制调用 REST API 的方法。第一个步骤是使用验证和数据类型的必要参数实例化 HttpClient:
public VoiceRecognition()
{
_httpClient = new HttpClient();
_httpClient.BaseAddress = new Uri("<API Endpoint>");
_httpClient.DefaultRequestHeaders.Add("Ocp-Apim-Subscription-Key",
"<Subscription Key>");
_httpClient.DefaultRequestHeaders.Accept.Add(
new MediaTypeWithQualityHeaderValue("application/json"));
}
使用下面的几个步骤生成图 6 中的识别方法:从场地中的 IoT 设备获取音频流后,它尝试基于已注册的个人资料集合识别该音频。在 IdentifyAsync 方法中为识别编码。
此异步方法准备包含音频流和识别个人资料 ID 的多部分请求消息,并向特定终结点提交 POST 请求。若 API 的响应为 HTTP 代码 202(已接受),则返回值为在后台运行的操作的 URI。识别方法每 100 毫秒查看一次所标识的 URI 上的该操作是否完成。操作成功后,即获得所识别的人员的个人资料 ID。
借助此 ID,可以继续验证音频流,它将最终确认录制的语音属于所识别的人员。
在 VerifyAsync 方法中实现此操作,此方法的工作原理与 IdentifyAsync 方法类似,但它返回的是包含人员的个人资料及其姓名的 VoiceVerificationResponse 对象。验证响应包含可信度,与人脸 API 一样,同时也会将其返回到访问 Web API。
图 6 语音识别
public double Recognize(string siteId, out string name)
{
ReadAudioStream(siteId, out Stream audioStream);
Guid[] enrolledProfileIds = GetEnrolledProfilesAsync();
string operationUri =
IdentifyAsync(audioStream, enrolledProfileIds).Result;
IdentificationOperation status = null;
do
{
status = CheckIdentificationStatusAsync(operationUri).Result;
Thread.Sleep(100);
} while (status == null);
Guid profileId = status.ProcessingResult.IdentifiedProfileId;
VoiceVerificationResponse verification =
VerifyAsync(profileId, audioStream).Result;
if (verification == null)
{
name = string.Empty;
return 0;
}
Profile profile = GetProfileAsync(profileId).Result;
name = profile.Name;
return ToConfidenceScore(verification.Confidence);
}
我要为此 API 添加一些额外说明,以表明它与人脸 API 的区别。语音验证 API 返回 JSON 对象,其中包含验证操作(接受或拒绝)、可信度(低、中、高)和识别的短语的整体结果:
{
"result" : "Accept", // [Accept | Reject]
"confidence" : "Normal", // [Low | Normal | High]
"phrase": "recognized phrase"
}
此对象映射到 VoiceVerificationResponse C# 类,以便于在 VerifyAsync 方法中运行它,但它的可信度使用文本表示:
public class VoiceVerificationResponse
{
[JsonConverter(typeof(StringEnumConverter))]
public Result Result { get; set; }
[JsonConverter(typeof(StringEnumConverter))]
public Confidence Confidence { get; set; }
public string Phrase { get; set; }
}
而访问 Web API 需要介于 0 到 1 之间的小数值(双精度数据类型),因此为可信度枚举指定了一些数字值:
public enum Confidence
{
Low = 1,
Normal = 50,
High = 99
}
然后在将这些值返回到访问 Web API 之前,将它们转换为双精度值:
private double ToConfidenceScore(Confidence confidence)
{
return (double)confidence / 100.0d;
}
总结
这是第一部分的全部内容,此部分说明了整个场地访问安全流,并介绍了如何使用自定义策略和要求实现 ASP.NET Core Web API 中的授权机制。
之后说明了如何使用相关的认知服务 API 完成人脸和语音识别,来作为基于已预授权或已注册人员个人资料的生物识别信息限制访问的机制。
本文的第二个部分将详细介绍作为请求访问触发点的 IoT 设备数据流,以及访问 API 最终确认打开(或锁定)入口的过程。
此外,还将说明每当尝试访问时都会运行以识别其风险的基于机器学习的异常检测服务。
从 GitHub 获取此解决方案的第一部分的源代码:bit.ly/2IXPZCo。
推荐阅读
(点击标题可跳转阅读)
看完本文有收获?请转发分享给更多人
关注「DotNet」加星标,提升.Net技能

好文章,我在看❤️





