商业DMP数据管理平台的架构与实践


分享嘉宾:林鹏 58同城 大数据架构师
编辑整理:张磊
出品平台:DataFunTalk
主要内容包括:
DMP 平台简介
DMP架构及实现
DMP应用
未来规划
DMP 其实是一个数据管理平台,是把分散的多方数据进行整合纳入统一的技术平台,并对这些数据进行标准化和细分,让用户可以把这些细分结果推向现有的互动营销环境里的平台。
业界代表性的产品有腾讯广点通和阿里达摩盘。它们主要提供创建细分人群、分析用户画像、种子用户群体拓展(lookalike)、再营销、分析投放管理、流量采买和第三方数据接入等功能。
下面和大家分享下58商业对DMP平台的需求。
1. 业务需求
58商业产品技术部主要负责整个58的商业变现,最核心的OKR其实是如何将有效的流量进行变现。
我们需要把点击广告的用户特征、上下文特征和我们自己的广告库特征进行加工整合后,再提供给在线广告推荐的触发、排序和装饰。其次还要支撑其他部门的商业营销、商家平台以及微聊系统。
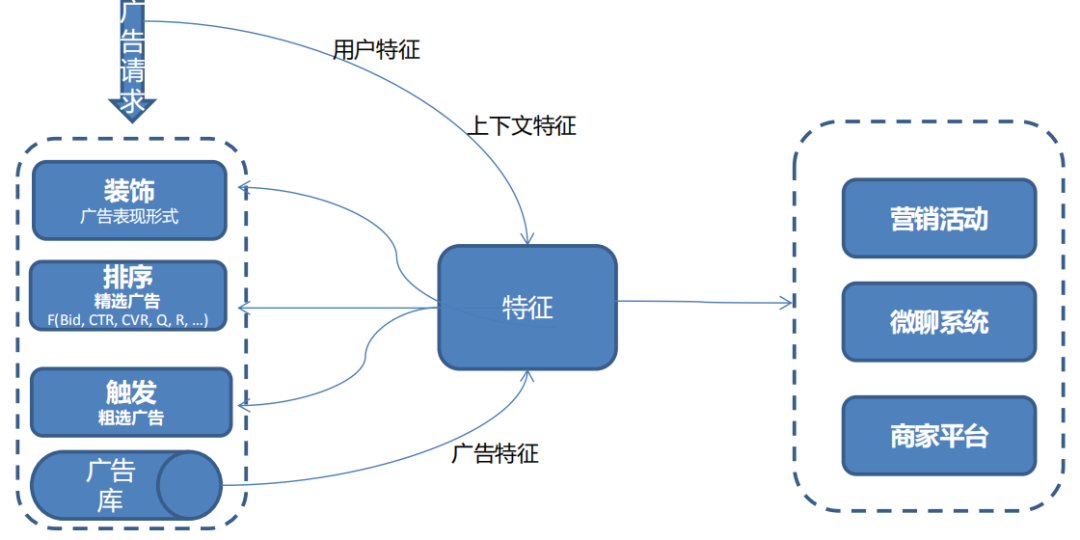
2. 特征需求
特征需求主要是特征的挖掘和特征的使用。
特征挖掘需满足:
快速、便捷定义特征挖掘逻辑
一定时限内的历史特征+ 实时特征(s 级)融合
快速上线生效
实验迭代
特征使用应提供如下功能:
丰富的特征数据、有序的特征体系、统一的元数据管理体系
便捷、稳定的在线服务
便捷、可靠的离线特征仓库
实验迭代
1. 商业DMP定位
首先,结合我们的需求,介绍下商业DMP定位,这里介绍的商业DMP主要是指我们商业站内的,主要提供特征挖掘和特征数据服务的能力。
对于开发者,特征挖掘平台提供了简洁、易用的开发SDK,屏蔽实时计算、批量计算、海量存储、高并发服务、各底层分布式系统部署等细节。提供TB级别(N天)行为数据挖掘和秒级别延时实时特征挖掘,支持特征挖掘实验、水平扩展。
对于特征数据服务平台,提供丰富的特征数据(TB级别)和元数据管理,能够提供在线和离线特征数据服务。对于在线,提供稳定的在线特征数据服务,支撑在线推荐系统;对于离线,提供灵活的多维查询,支持按人群特征进行营销活动。
2. 平台业务架构
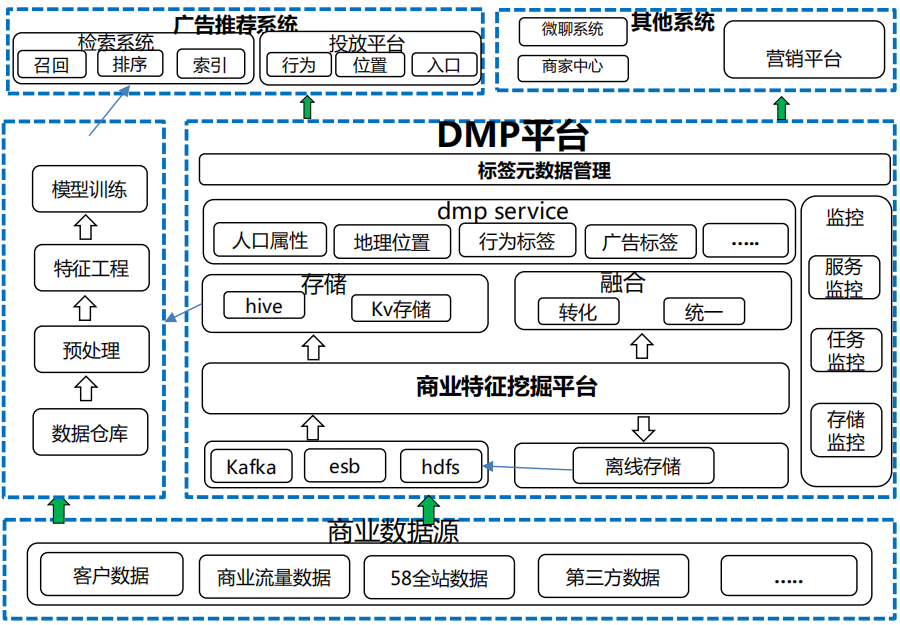
从数据的产生到标签的加工再到业务应用,在这完整的数据流中,DMP平台其实是起着承上启下的作用,可以把它看做是一个数据工厂,对数据特征进行统一、清洗、加工、转化、提炼,再对外提供相应的数据服务。DMP平台主要包括特征挖掘平台、dmp service、标签元数据管理、监控等模块。
3. 平台逻辑架构
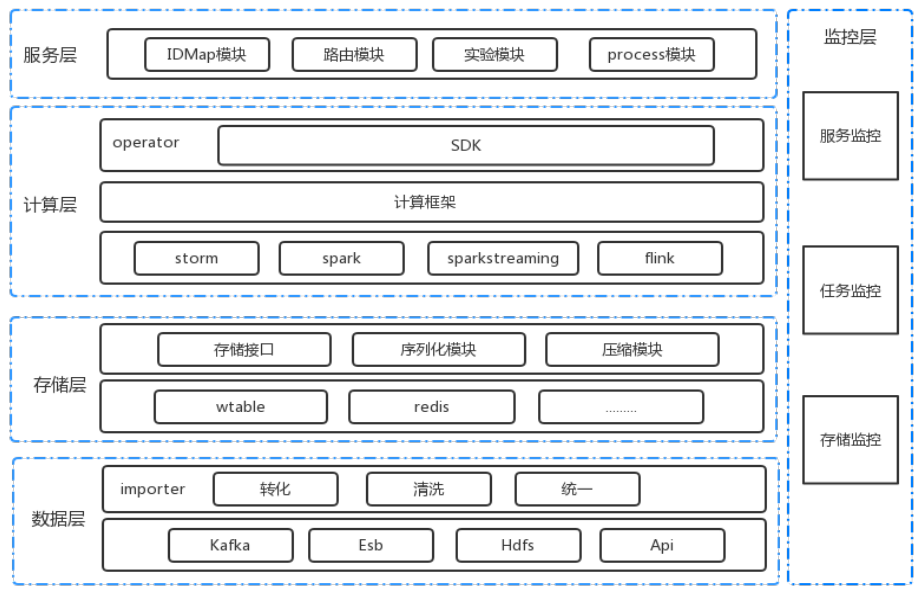
平台逻辑架构主要分为数据层、存储层、计算层、服务层和监控层。
数据层:提供Kafka、ESB、HDFS、Api等多种异构数据源,通过importer层将数据进行统一的清洗转化,对下形成统一的数据源,从而屏蔽底层的异构数据源。
存储层:我们实现了存储接口、序列化模块、压缩模块。由于在线推荐特征挖掘提供基于KV键值存储就能满足需求,故底层存储主要提供Redis和自研的wtable等。
计算层:提供了storm、spark、sparkstreaming、flink等多种计算引擎。在operator模块提供让特征挖掘用户自己实现对应的SDK即可,简便高效,同时对于用户来说屏蔽掉了异构计算。
服务层:主要提供IDMapping、路由、实验、process四个模块。IDMapping主要是为了打通数据孤岛;路由模块主要是解决流量分发问题;实验模块主要是进行分流实验;process模块主要是提供业务解耦能力。
监控层:对服务、任务、存储等进行监控,对多环节快速发现定位并解决问题。
4. 平台功能
平台目前提供行为引入、特征存储、特征挖掘和特征服务四大模块。
行为引入:提供ID-Mapping服务、实验分流、统一Behavior结构,支持Behavior结构实时离线复用和兼容,支持实时批量导出Behavior数据。
特征挖掘:支持实时挖掘和批量挖掘,并支持在线加工,统一特征和属性结构,为解析用户行为提供相应的SDK。
特征存储:支持随机和批量的高并发读写,提供TB级别的特征存储能力,同时提供实时特征和历史特征的融合,支持多版本的特征迭代。
特征服务:对外提供统一的访问接口,权限控制,元数据管理和实验分流。
5. 元数据管理
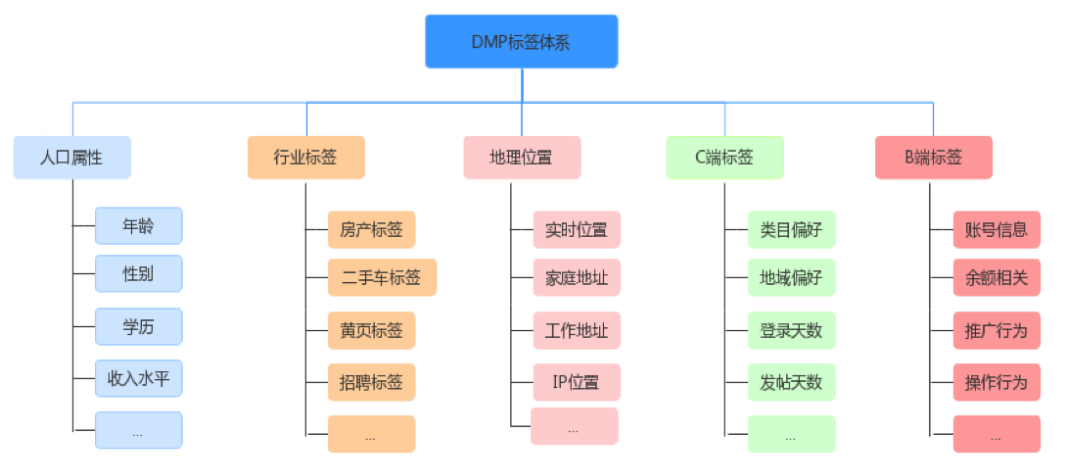
商业DMP标签体系主要分为C端标签和B端标签两类。C端主要是流量相关的标签,可以给予人口属性、行业标签、地理位置等做进一步细分。B端主要是广告主相关的标签。
6. 特征挖掘流程
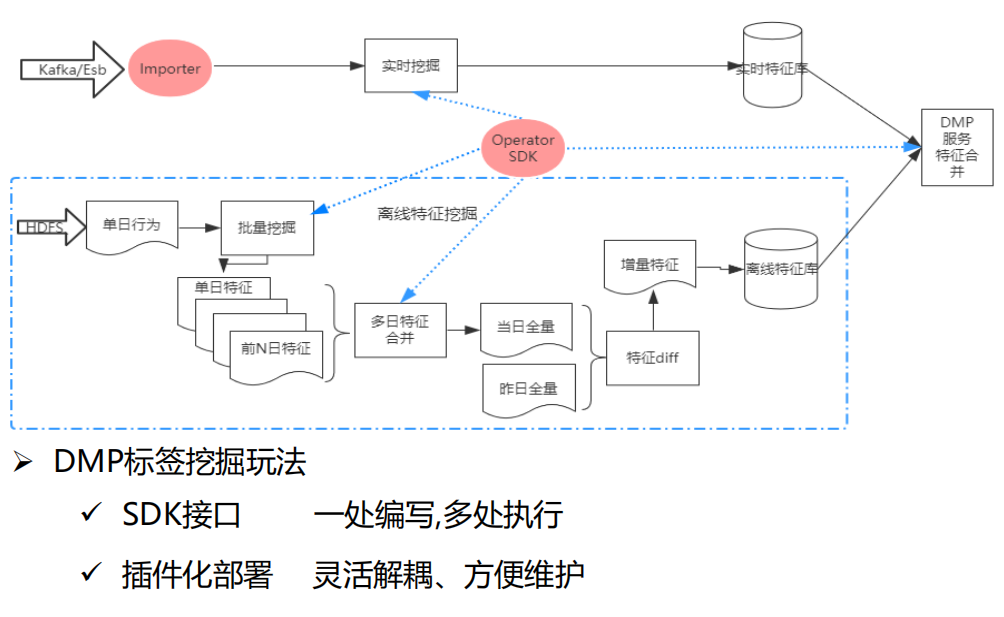
特征挖掘主要分实时特征挖掘和离线特征挖掘两大块。我们提供了Importer(对数据源的解析)和Operator SDK(融合数据挖掘的接口),可以对用户提供SDK开放接口,达到一处编写,多处执行的能力,并且支持插件化部署,利于服务解耦和维护。
离线特征挖掘的场景是一般基于单日行为的批量挖掘,再向前回溯n日的特征,然后进行多日特征合并。首次进行全量导入特征库,后续每日做增量特征导入,是通过当日全量与昨日全量做特征diff,然后得到增量特征在导入特征库。
实时特征挖掘是通过Importer和解析用户挖掘的SDK在写入实时特征库,最后在DMP服务会对实时特征库和离线特征库进行合并,再对外提供服务。
7. 计算框架
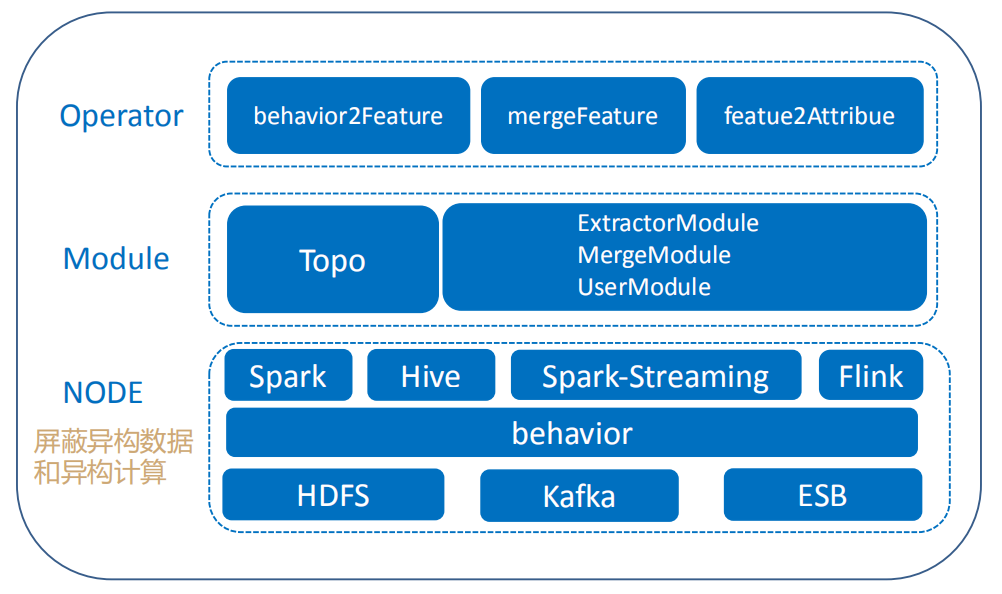
计算框架大致分NODE、Module和Operator三部分:
NODE:对用户屏蔽了异构数据和异构计算。提供Spark、Hive、SparkStreaming和Flink计算引擎,底层数据源支持HDFS、Kafka和ESB,通过behavior数据结构,对58商业流量数据抽象定义,从而兼容多种异构数据源,提供统一的数据结构。
Module:Topo主要是对Operator解析和调用。
Operator:对用户暴露了behavior2Feature、mergeFeature和 featue2Attribue三个接口。behavior2Feature是对schema数据转换成用户需要的标准化的特征;mergeFeature提供用户自定义的特征融合功能;featue2Attribue是对外提供特征查询的接口服务。
8. 实时计算
① 遇到的问题
稳定性问题:由于流量洪峰导致的任务处理数据量变大、内存溢出、数据积压等问题;由于任务频繁提交到故障机器导致任务失败问题;由于部分任务执行耗时导致整个任务执行时间过长,从而产生数据积压的问题;由于网络shuffle耗时导致任务性能变差;由于Spark和Flink自身的监控不能满足业务需要,导致不能及时发现异常问题等。
Flink框架问题:分布式缓存不生效、Taskmanager超时失败、Flink框架空指针异常等。
数据流传输问题:flume采集数据传输延迟,导致用户行为实时转化不及时。
监控问题:由于监控时间粒度太小导致监控覆盖不全。
② 解决方案
稳定性:利用Spark和Flink自带的反压机制解决流量洪峰问题;对于机器故障问题采用黑名单机制和推测执行机制来解决;通过定制化任务监控来及时发问题。
容错性:主要采用Spark和Flink自带的checkpoint机制。
高性能:算子优化、shuffle优化、参数调优等。
Flink问题:向Flink社区反馈问题,借助HDFS我们实现了分布式缓存功能。
数据传输:借助公司力量,推动Flume传输架构优化升级。
监控:开发自定义监控系统,并结合Flink,Spark自带监控。
③ 定制化监控

我们的监控平台主要结合Flink,Spark自带监控进行一个补充,主要针对task运行,重试次数和失败次数的监控和一些其他维度的监控,通过告警层,配置告警相关规则,将监控的异常信息及时通知告警人并处理。
9. 存储系统选型

针对上述对比结合58内部以及业界常见KV存储查询,我们选择Redis和wtable这两种KV存储系统。针对要求高性能高并发读写的场景我们选用redis,针对并发读性能要求高,并发写性能相对较低的场景则选用wtable。

10. 存储优化
① 读写合并优化
由于实时离线特征数据量太大,数据库的读写次数几乎等于流量日志的数量。我们做了如下优化:
离线特征先在内存中合并单个用户当日的所有特征,再合并所有RDD中包含该用户特征的数据,最后再把生成的特征数据同特征库中的历史特征数据进行合并(从n到1);
实时特征在写入特征库之前先进行窗口内聚合,通过牺牲时效性从而减轻特征库的读写压力;
将IDMap与离线特征加入本地缓存中。
优化结果:超时概率从之前的3%左右降到了0.1%以下。
② 离线实时特征拆库
由于之前离线实时特征库为同一个库,大量离线写入会对在线读请求有影响,造成服务超时及离线数据导入时间较长。针对此现象我们将离线特征单独存储,并将数据导入方式从单条导入修改为bulkload导入的方式。
优化结果:离线数据导入由3小时降至0.5小时,同时DMP对外查询服务保证在50ms之内。
③ 耗时优化
遇到问题:
获取单个用户请求时需要经过IDMap查询、两次实时特征查询和一次离线特征查询,总共四次服务调用,串行执行很容易超时;
入库的时候都做了压缩和序列化,如何提高压缩耗时与压缩比;
DMP平台采用Java服务懒加载方式从而导致服务启动耗时。
优化方法:
对于没有依赖关系的服务调用采用并行处理;
IDMapping增加缓存,保证服务的响应时间;
压缩加入压缩头,支持多种序列化与压缩方式,保留优化空间;
修改懒加载方式
优化结果:服务调用耗时从原来的各服务调用时间之和变成各服务调用耗时最大值。
11. DMP实验平台
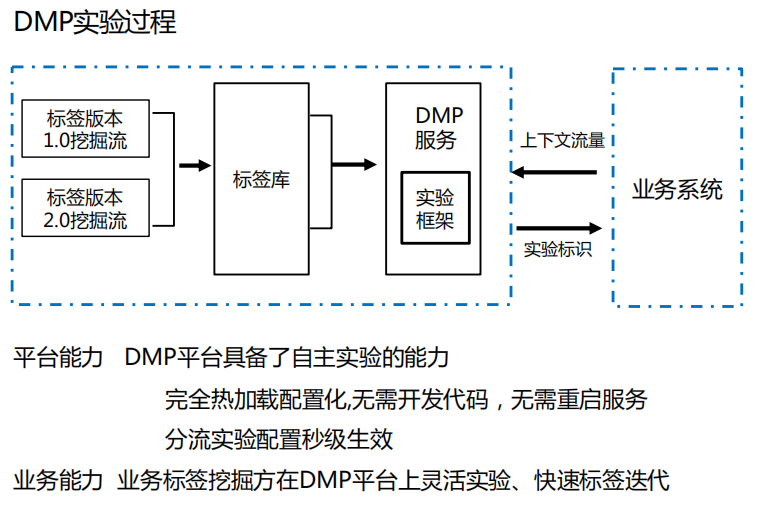
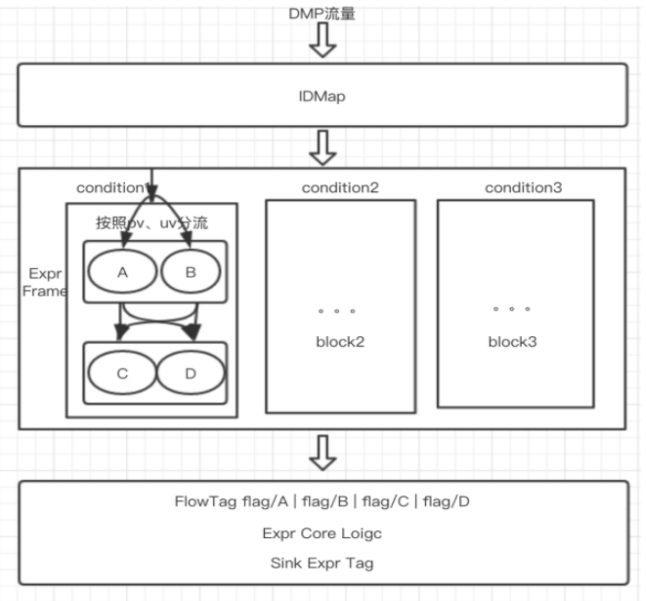
如图所示为DMP分流实验架构参照的是google分层实验框架,整个流程大致如下:
DMP流量经过IDM模块后根据condition条件进入相应的block。
DMP流量按照相应的分流方式进行分流。
根据分流实验标记进行不同的实验逻辑处理
Sink实验标记回传方便业务线做相关的数据统计分析
1. 在线推荐系统二手车Feed流
Feed流是实时的个性化推荐,从而实现用户体验和商业价值的提升。这就要求我们能快速捕捉到用户的行为变化并提取用户特征。DMP需要能对用户行为数据的采集清洗转换到特征加工等达到秒级加工能力,从而保障Feed流系统的实时性。
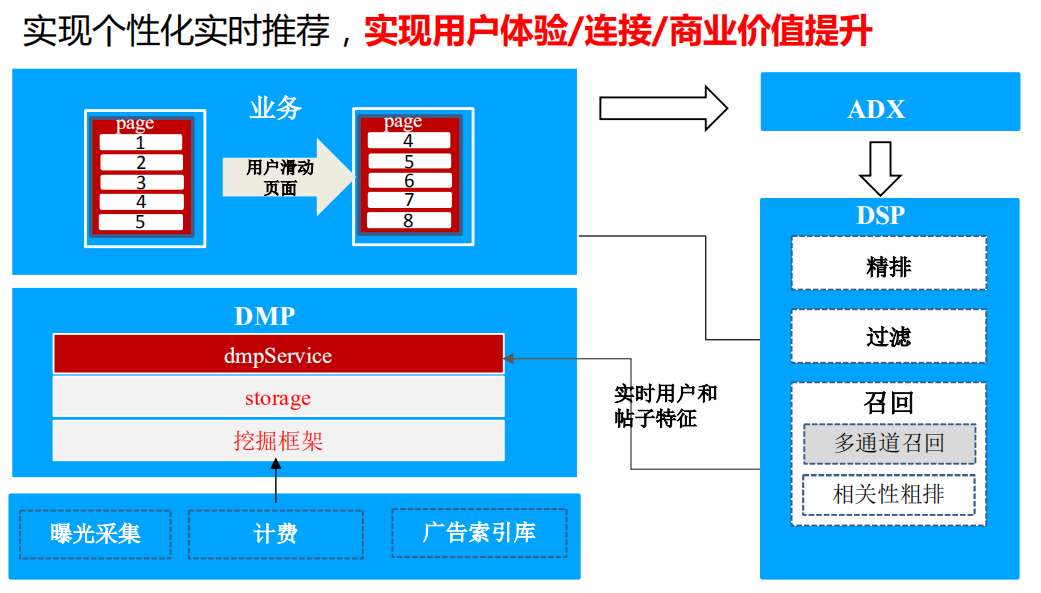
2. 人群服务
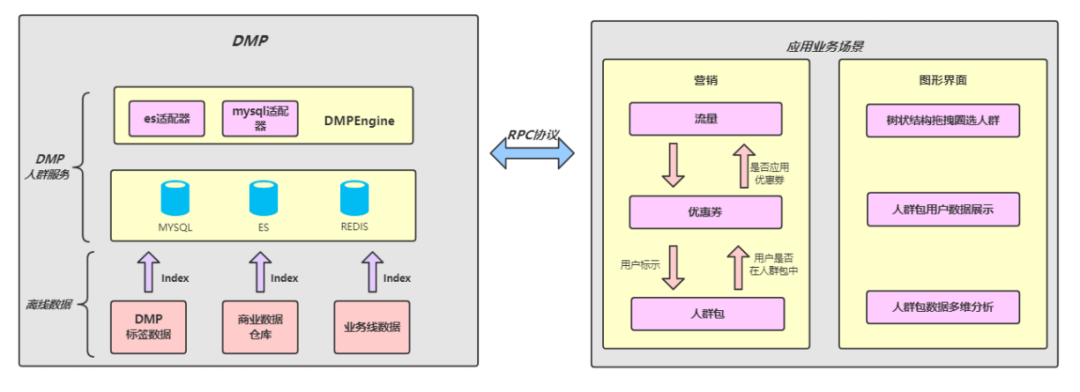
人群服务主要是给营销产品提供人群圈选的功能,用来做智能营销的场景,主要包括创建人群包和通过人群来查询相关的用户即基于多个维度的标签属性筛选分析用户特点。目前创建人群包主要支持标签组合和自定义上传两种模式。
创建人群的具体流程如下:
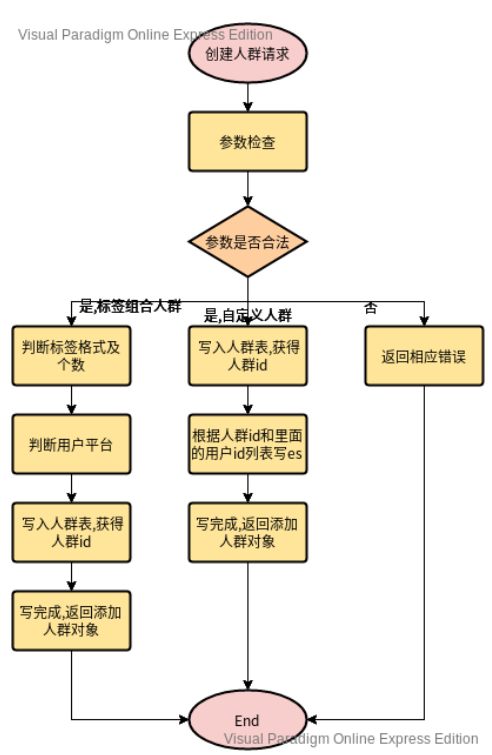
创建完人群包之后,即可根据创建的人群包进行相关的人群圈选功能。具体流程如下:
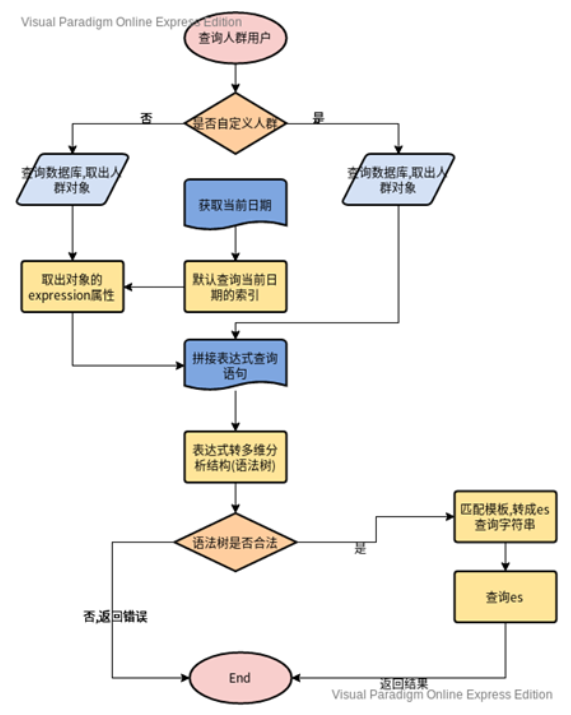
在整个查询过程中,通过人群包进行人群圈选直接查询es的性能会有一定延迟,为此我们进行了架构的优化和调整:
对于t+1之前已经创建的人群包,每天离线数据导入的时候会将相关人群包对于的圈选人群直接圈选出来持久化到redis中,从而满足在线场景的实时查询。
对于新创建的人群包,按照上述流程进行查询,同时将查询结果缓存到redis中,方便后续的重复查询。
未来我们希望可以借助商业DMP的能力,进一步为公司赋能提效:
1. 构建OneService
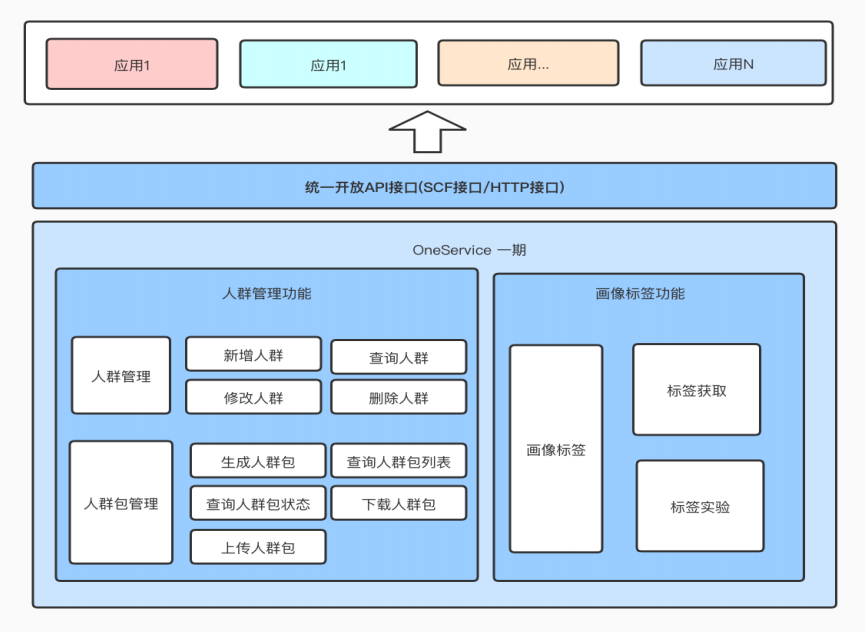
通过服务升级,能够对外提供统一的用户画像服务、标签管理、统一开放API、人群管理。
2. 引入Doris
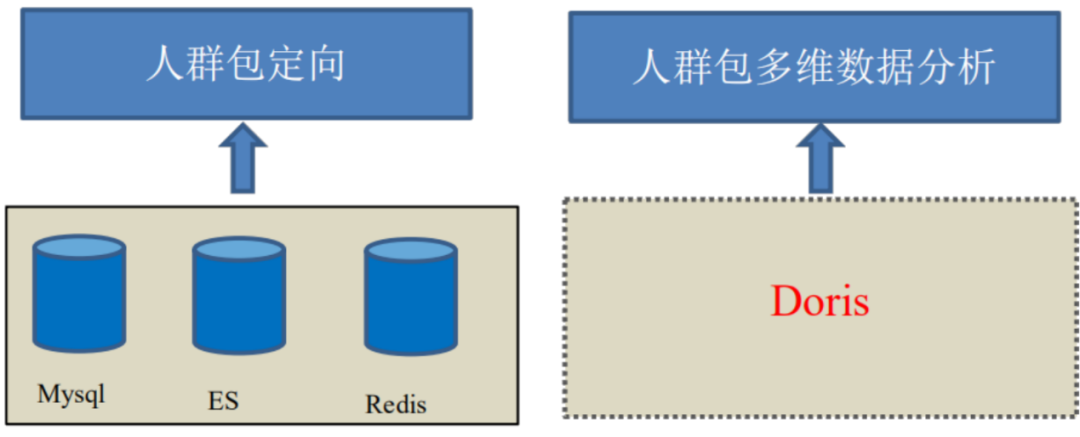
引入Doris计算引擎,支持人群包更实时和灵活的多维度分析功能。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个三连击呗~~
分享嘉宾:

林鹏
58同城 | 大数据架构师
欢迎加入 DataFunTalk 大数据交流群,跟同行零距离交流。如想进群,请识别下面的二维码,根据提示自主入群。

文章推荐:
关于我们:
DataFunTalk 专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100场线下沙龙、论坛及峰会,已邀请近500位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章300+,百万+阅读,7万+精准粉丝。

🧐分享、点赞、在看,给个三连击呗!👇