论文浅尝 | BERT:Pre-training of Deep Bidirectional Transformers
论文笔记整理:王春培,天津大学硕士。

链接:https://arxiv.org/pdf/1810.04805.pdf
动机
将预训练语言表示应用于下有任务现有两种策略:基于特征的和基于微调的。文章认为当前技术限制了预训练的能力,尤其是基于微调的方法。很多语言模型是单向的,或者特征抽取器功能不够强大,这些都限制了下游NLP任务的性能。BERT模型通过使用双向编码器来改进基于微调的方法,添加NSP提高模型性能,推进了11项NLP任务的技术。
亮点
BERT的亮点主要包括:
(1)使用双向语言模型,使用能力更强的Transformer提取特征,添加NSP任务,提高模型性能。
(2)推进了11项NLP任务的最新技术,可应用范围非常广。
概念及模型
模型体系结构
BERT的模型架构是一个多层双向Transformer编码器,文中主要报告两种模型参数的结果:
(1)BERTBASE: L=12, H=768, A=12, TotalParameters=110M
(2)BERTLARGE: L=24, H=1024, A=16, TotalParameters=340M
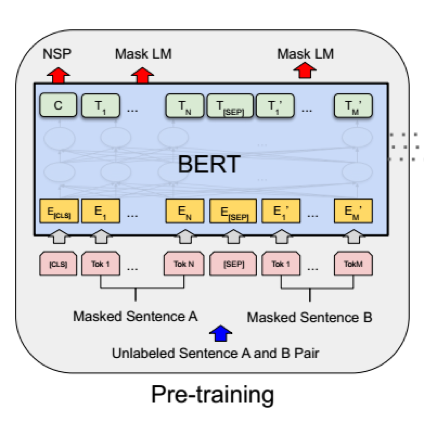
输入表示

输入表示分为三部分:
(1)词嵌入:用##表示分词
(2)位置嵌入:通过学习得到位置嵌入,支持序列长度可达512个令牌
(3)句子嵌入:句子对被打包成一个序列,首先用特殊标记将它们分开。其次,添加一个学习句子A嵌入到第一个句子的每个标记中,一个句子B嵌入到第二个句子的每个标记中,对于单个句子,只是用句子A嵌入。
预训练任务
1、任务#1:Masked LM
文章认为双向语言模型比单向语言模型功能更强大,为了训练双向语言模型,文章采取的方法为随机屏蔽一定比例的输入令牌,然后仅预测那些被屏蔽的令牌,并将这其称为“Masked LM”(MLM),这种做法与CBOW不谋而合。
虽然可以此方法构建双向预训练模型,但这种方法有两个缺点。
首先,预训练和微调之间不匹配,因为[MASK]令牌在微调期间从未出现。为了减轻这种影响,文章提出并不总是用实际的[MASK]令牌替换“掩蔽”词。相反,训练数据生成器随机选择15%的令牌,然后执行以下过程:
(1)80%的时间:用[MASK]标记替换单词
(2)10%的时间:用随机单词替换单词
(3)10%的时间:保持单词不变
Transformer编码器不知道它将被要求预测哪些单词或哪些单词已被随机单词替换,因此它被迫保持每个输入标记的分布式上下文表示。此外,因为随机替换只发生在所有令牌的1.5%(即15%的10%),这似乎不会损害模型的语言理解能力。
第二个缺点是每批中只预测了15%的令牌,这表明模型可能需要更多的预训练步骤才能收敛。
2、任务#2:NSP
许多重要的下游任务都是基于理解两个文本句子之间的关系,而这两个文本句子并不是由语言建模直接捕获的。为了训练理解句子关系的模型,文章预先训练了一个可以从任何单语语料库生成的二值化的下一个句子预测任务。具体地,当为每个预训练示例选择句子A和B时,50%的时间B是跟随A的实际下一句子,并且50%的时间是来自语料库的随机句子。
实验
文章将介绍11个NLP任务的BERT微调结果:
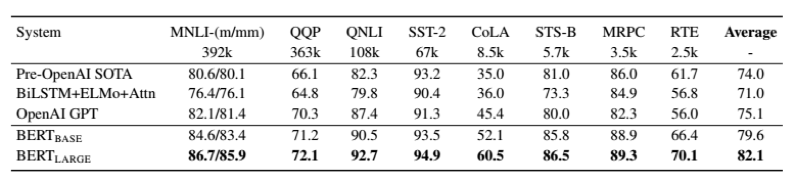
1、GLUE结果
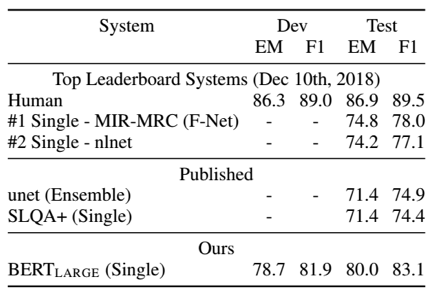
2、SQuAD v1.1

3、SQuAD v2.0
4、SWAG

总结
由于语言模式转换学习的经验改进表明,丰富的、无监督的预训练是许多语言理解系统的一个组成部分。特别是,这些结果使得即使是低资源任务也能从非常深的单向体系结构中受益。文章的主要贡献是将这些发现进一步推广到深度双向架构,允许相同的预训练模型成功解决一系列广泛的NLP任务。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。



