近期必读的五篇 EMNLP 2020【反事实推理】相关论文和代码
1. Back to the Future: Unsupervised Backprop-based Decoding for Counterfactual and Abductive Commonsense Reasoning
作者:Lianhui Qin, Vered Shwartz, Peter West, Chandra Bhagavatula, Jena D. Hwang, Ronan Le Bras, Antoine Bosselut, Yejin Choi
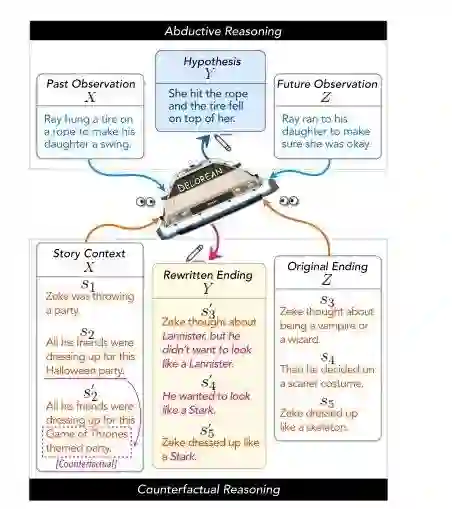
摘要:推理和反事实推理是人类日常认知的核心能力,需要对时间t可能发生的事情进行推理,同时要根据过去和未来的多个背景进行推理。然而,使用生成语言模型(LMS)同时合并过去和未来的上下文可能是具有挑战性的,因为它们要么被训练成仅以过去的上下文为条件,要么被训练成执行范围狭窄的文本填充。
在本文中,我们提出了一种新的无监督解码算法DeLorean,它可以在只使用现成的、从左到右的(off-the-shelf, left-to-right)语言模型,并且无监督的情况下,灵活地合并过去和未来的上下文。我们算法的关键点是通过反向传播与未来相结合,在此过程中,我们只更新输出的内部表示,同时固定模型参数。通过在前向和后向传播之间交替,DeLorean可以解码既反映左上下文又反映右上下文的输出表示。我们证明了我们的方法是通用的,适用于两个非单调(nonmonotonic)推理任务:推理文本生成和反事实故事修改,在这两个任务中,DeLorean基于自动和人工评估,优于一系列无监督和一些监督方法。
代码:
https://github.com/qkaren/unsup_gen_for_cms_reasoning
网址:
https://www.zhuanzhi.ai/paper/97076868b0527e35cc235e57390a1a32
2. Counterfactual Generator: A Weakly-Supervised Method for Named Entity Recognition
作者:Xiangji Zeng, Yunliang Li, Yuchen Zhai, Yin Zhang
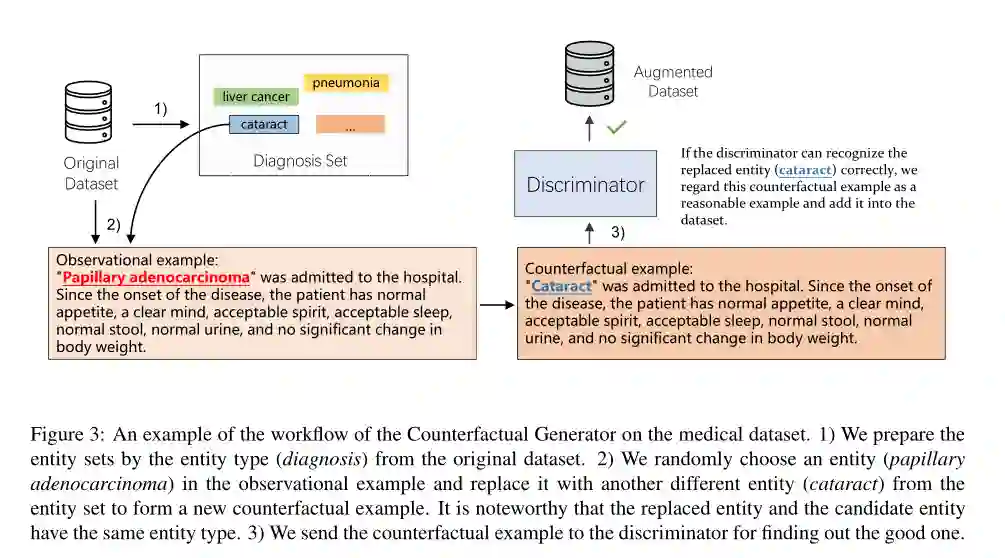
摘要:神经模型的进展已经证明,如果我们有足够的标签数据,命名实体识别(named entity recognition)不再是一个问题。然而,收集足够的数据并对其进行注释是需要大量劳动、耗时和昂贵的。在本文中,我们将句子分解为实体和上下文两个部分,并从因果关系的角度重新思考它们与模型性能的关系。在此基础上,我们提出了反事实生成器,它通过对已有观测实例的干预来增强原始数据集,从而生成反事实实例。在三个数据集上的实验表明,我们的方法在有限的观测样本下提高了模型的泛化能力。此外,我们还使用一个结构因果模型来研究输入特征和输出标签之间的伪相关性,从而提供了理论基础。在非增广和增广两种情况下,我们考察了实体或上下文对模型性能的因果影响。有趣的是,我们发现非伪相关性更多地位于实体表示中,而不是上下文表示中。因此,我们的方法消除了上下文表示和输出标签之间的部分虚假相关性。
代码:
https://github.com/xijiz/cfgen.
网址:
https://www.aclweb.org/anthology/2020.emnlp-main.590/
3. Counterfactual Off-Policy Training for Neural Dialogue Generation
作者:Qingfu Zhu, Wei-Nan Zhang, Ting Liu, William Yang Wang
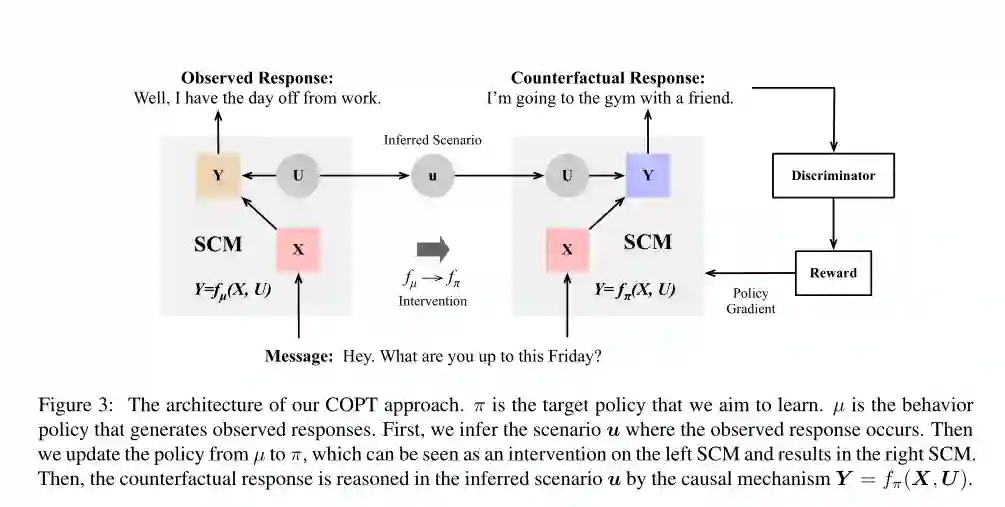
摘要:由于潜在反应( potential responses)的巨大规模,开放式对话生成(Open-domain dialogue generation)存在数据不足的问题。在本文中,我们提出通过反事实推理来探索潜在的反应。给出一个观察到的反应,反事实推理模型会自动推断出可以采取的替代策略的结果。事后合成的反事实反应比从头合成的反应质量更高。对抗性学习框架下的反事实反应训练有助于探索潜在反应空间的高回报领域。在DailyDialog数据集上的实证研究表明,该方法的性能明显优于HRED模型和传统的对抗性学习方法。
网址:
https://www.zhuanzhi.ai/paper/2287217f248f98d2d14492866939f0e8
4. Learning to Contrast the Counterfactual Samples for Robust Visual Question Answering
作者:Zujie Liang, Weitao Jiang, Haifeng Hu, Jiaying Zhu
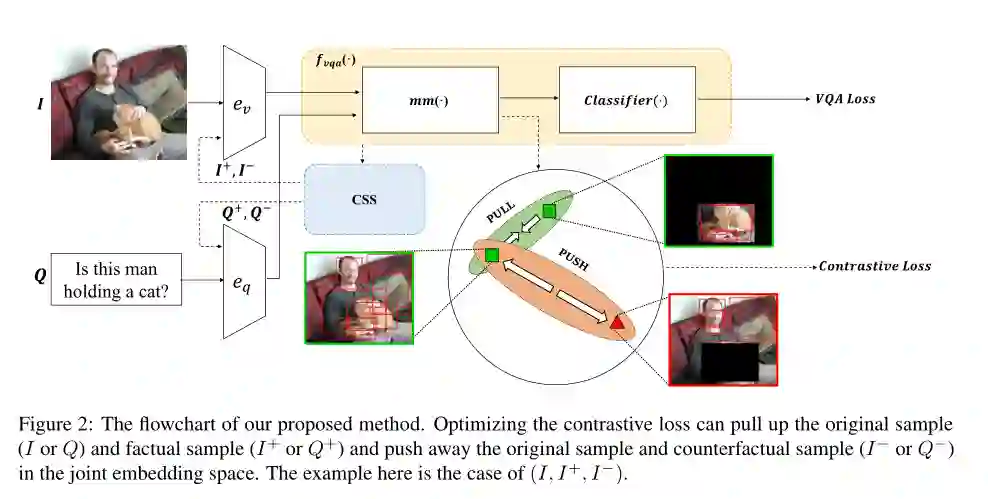
摘要:在视觉问答(VQA)任务中,大多数先进的模型往往会在训练集中学习虚假的相关性,并且在非分布(out-of-distribution)测试数据中表现不佳。为了缓解这一问题,已经提出了一些生成反事实样本的方法。然而,大多数以前的方法生成的反事实样本只是简单地添加到训练数据中进行扩充,没有得到充分的利用。因此,我们引入了一种新的自监督对比学习(contrastive learning)机制来学习原始样本、真实样本和反事实样本之间的关系。通过从辅助训练目标中学习到更好的跨模态联合嵌入,VQA模型的推理能力和稳健性都得到了显著的提高。我们通过在VQA-CP数据集(VQA-CP数据集是评估VQA模型稳健性的诊断基准)上超过当前最先进的模型来评估我们方法的有效性。
网址:
https://www.aclweb.org/anthology/2020.emnlp-main.265/
5. Less is More:Attention Supervision with Counterfactuals for Text Classification
作者:Seungtaek Choi, Haeju Park, Jinyoung Yeo, Seung-won Hwang
摘要:我们的目标是利用人类和机器的智能来进行注意力监督。具体地说,我们证明了人工标注的代价可以保持在合理的低水平,而标注的质量可以通过机器的自监督来提高。具体地说,为了达到这一目标,我们探索了反事实推理相对于通常用于注意监督的联想推理的优势。实验结果表明,在情感分析和新闻分类等文本分类任务中,这种机器增强的人类注意力监督方法比现有的标注代价更高的方法更有效。

网址:
https://www.aclweb.org/anthology/2020.emnlp-main.543/
请关注专知公众号(点击上方蓝色专知关注)
后台回复“EMNLP2020CR” 就可以获取《5篇顶会EMNLP 2020 反事实推理(Counterfactual Reasoning)相关论文》的pdf下载链接~




