基于CPPN与GAN+VAE生成高分辨率图像(一)
编者按:Google Brain机器学习开发者hardmu使用TensorFlow,基于CPPN与GAN+VAE生成高分辨率图像。一起来看看他是怎么做的吧。

基于CPPN与GAN+VAE的生成式模型
介绍
在数字生成艺术的某些领域,艺术家通常不会直接使用图像编辑器创作。艺术家通常会编程一组过程,由过程生成实际的图像。这些过程由指示机器在特定坐标上绘制线条和形状的指令组成,并以某种数学定义的方式操作颜色。最终的作品(可能作为像素图像呈现,或打印在物理介质上)可以由一组数学过程完全刻画和定义。
许多自然图像具有有趣的数学特性。人们已经编写简单的数学函数来产生自然的分形纹理,如树枝和雪花。像分形一样,一组简单的数学规则有时能生成一个非常复杂的图像,这样的图像可以被无限放大或缩小。
想象一下,如果你可以接受任何图像作为输入,并不将该图像存储为一组像素,而是尝试找出一个逼近图像的数学函数,也就是说,特定位置的像素(x, y)可以由f(x, y)表示。
一旦找到这样的函数,仅仅通过缩放输入就能自动缩放和拉伸图像。如果这个函数有一些有趣的性质或者表现出某种内部结构,那么看看把图像放大到比原始图像大得多的分辨率是什么效果会很有趣。
这个函数也可以定义为一个具有任意架构的神经网络。有人将这类网络称为复合模式生成网络(Compositional Pattern Producing Networks),这类网络是一种用函数表示整张图像的方式。由于神经网络是普适的函数逼近器,给定一个足够大的网络,任何有限分辨率的图像都可以用这种方法表示。

我认为由各种架构的神经网络生成的作品的风格看起来真不赖,所以我打算探索下这类生成式网络是否可以用来生成整类图像,而不仅仅是单个图像。最近有研究使用神经网络来生成某个特定类别的像素图像,我想看看能不能用上述生成式网络达到类似的效果。
在这篇文章中,我将介绍使用CPPN生成高分辨率手写数字图像的经验,作为一个开始,我将在MNIST(28x28 px)上进行训练。将来我可能会尝试在更复杂的图像集上使用这一方法。
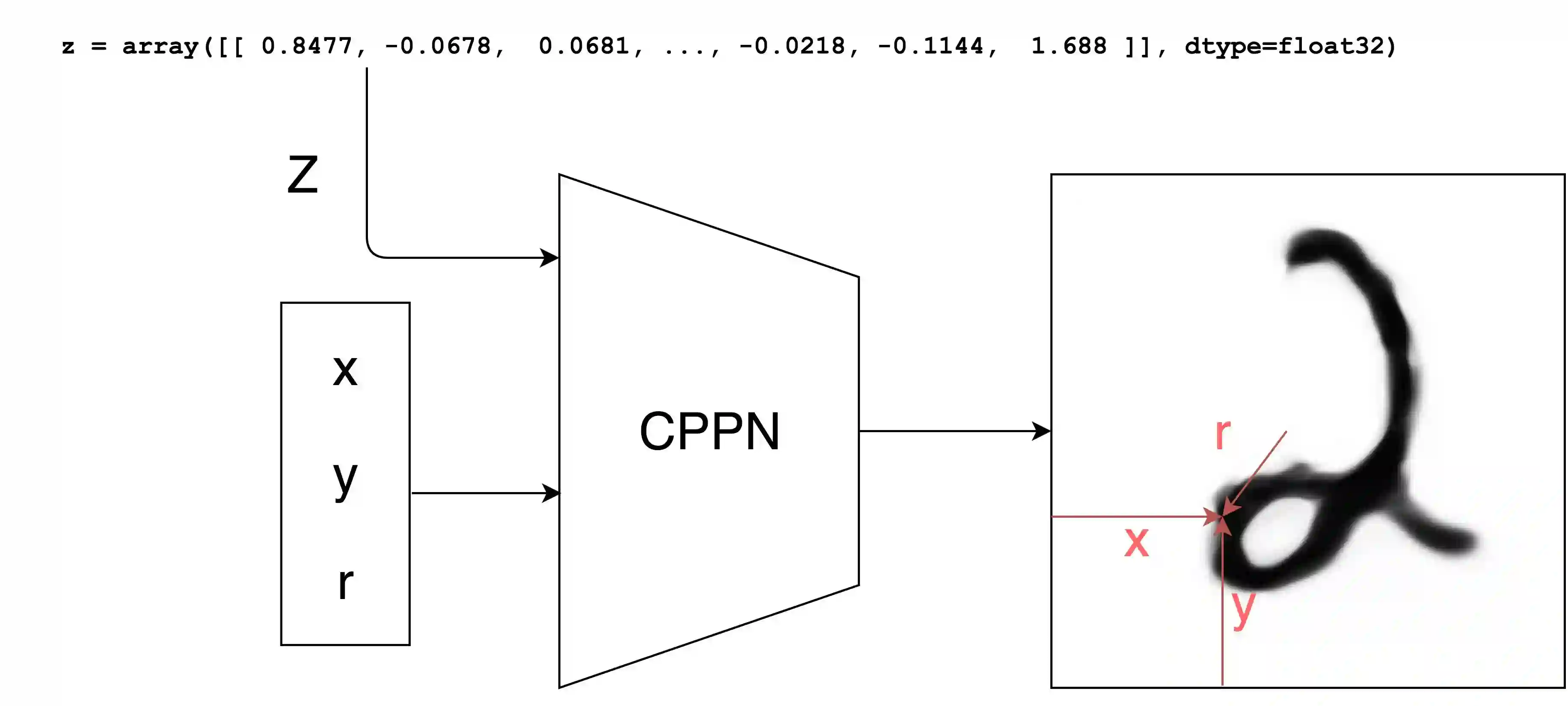
背景
在前一篇文章中,我们探索了使用CPPN生成有趣的随机纹理的高分辨率图像。由于CPPN的输入由某个像素的坐标组成,而输出是该坐标的颜色,因此CPPN可以生成机器内存所允许的任意分辨率的图像。 这一特性为CPPN提供了一些类似于分形的特征,因为只需调整图像所需视图对应的缩放输入坐标,即可任意缩放图像。随机化CPPN的权重可以产生许多在某些人看来很美的抽象纹理。而且,如果我们固定神经网络架构和一组随机权重,我们可以通过调整额外加入网络的潜向量输入来探索CPPN可生成图像的空间。

我之前使用CPPN生成了许多奇怪的图像,并且一直为此方法可以生成的图片范围而感到惊讶。除了随机生成抽象的艺术纹理,这种方法也被用于基因艺术生成。在以前的项目中,艺术通过“基因”慢慢演化,我发现,生成“最好”的艺术需要放弃实际创作某一特定事物的目标。例如,如果一个艺术家想用CPPN-NEAT来生成一张猫的图像,她很可能不会得到任何类似猫的东西。但如果艺术家着手选择她认为看起来有趣的纹理,并将它们混合起来以产生下一代图像,最终她可能会得到看起来更有趣的东西。Ken Stanley在其著作Novelty Search中强调了这一现象,我发现这是一个非常迷人的看待AI研究领域的方法,同时也是一个面对生活的一般方法。
不过,我确实认为让CPPN生成所需的指定图像是可能的。给定一个足够大的网络,而不是一个微小的NEAT网络,我们可以逼近任何东西,甚至karpathy的简单JS绘画演示证明,给定足够大的网络和足够长的训练时间,这一方法可以绘制任何图像。
然而,相比依靠过拟合网络权重来匹配某个目标图像以生成特定的图像,这种网络是否能够产生新概念图像是一件更有趣的任务。例如,我们希望能够让网络生成一只猫的随机图片,并能够让这只猫慢慢渐变为狗。这样的话,网络就不是真的过拟合某个特定的训练图像,而是内在地理解猫和狗的概念,以至于能够想象介于猫和狗之间的新图像。若干年前,我认为这会被视为科学幻想,但我们实际上已经达成了这一点。
最近,我们已经看到了能够生成人、浴室、猫和动漫人物的深度神经网络。这些方法将图像中的像素建模为可观测的随机变量X。除非是像白墙这样非常琐碎的图像集,否则X内所有像素的联合概率分布是非常复杂的,不太可能用一些人类可以理解的更简单的分布来建模。然而,神经网络有可能胜任这一艰巨的任务,学习如何将这种复杂的分布映射到人类可以理解和使用的简单分布,比如高斯分布。所以诀窍就是将这样复杂的可观测的随机变量(一张图像中的所有像素)建模为因变量,它的值取决于一组表示更简单的概率分布的变量,例如由一打单位正态高斯构成的向量。该向量通常记为Z,即潜向量。
所以我们的目标是让神经网络从一个非常简单的由实数组成的潜向量Z中学习能够生成一张非常复杂的图像X的条件概率分布P(X|Z)。此外,一个附赠的学习P(Z|X)的网络也是非常有用的,可以用来将复杂图像编码为潜向量。
回想一下统计学的第一门课程,你会发现这与主成分分析(PCA)有些关系。PCA尝试将一个大的观测集分解成数量较少的因子,改变这些小的因子集可以预测大的观测集会有什么样的改变。唯一的区别是PCA是基于线性代数的,PCA假定数据可以解释为较小因子的线性组合,而这种基于神经网络的方法能够以高度非线性的方式分解大的观测集,因而更为强大。
目前,从潜向量生成图像的前沿技术通常基于生成对抗网络(GAN),变分自动编码器(VAE)或这些方法的组合,下文会描述它们。想要了解更多关于这些方法的信息,请参阅深度卷积生成对抗网络(DCGAN),一个知名的该领域中最先进的技术,而DRAW算法是VAE最前沿的扩展。我对这个领域的研究基于carpedm20的DCGAN实现和Jan Hendrik的VAE实现,两者都使用了TensorFlow库。他们的代码和解释对我的理解有很大帮助。我也研究了这两种方法的结合,同时用了一些技巧来稳定GAN的训练。
就目前的文献而言,训练数据集通常由小图像组成(例如32x32 px或64x64,尽管我看到过使用128x128和256x256的)。为了与训练数据匹配,生成器网络将具有与训练数据的像素数量一样多的输出。因此,通常情况下,在64x64像素的图像数据集上训练的网络也会直接输出64x64像素。目前的方法很难生成分辨率远高于256x256的图像,因为所需的内存可能超过现代显卡的可用显存。
本文将使用CPPN基于MNIST训练集的较小图像生成大图像。由于CPPN可以生成任意大分辨率的图像,我想尝试训练一个生成图像的CPPN会是非常简洁的,就像使用GAN和VAE一样,只是将直接生成所有输出像素的生成网络替换为CPPN而已。训练时,我们可以直接将CPPN的输出分辨率设置为与输入相同。训练后,我们可以增加输出图像的分辨率,看看CPPN如何用由网络定义的内部风格来填补空白。之所以将CPPN的训练分辨率设置为与训练数据相同的大小,是为了让现代的显卡能够承受整个训练过程。
由于CPPN架构的间接编码本质,相比于直接输出所有像素的网络,CPPN可能产生的图像的空间会相当受限。所以就这个立场而言,训练CPPN被证明更具挑战性,在简单的MNIST数据集的训练,相比VAE或GAN模型要花费更多的时间。在一个MNIST之类的简单数据集上,用结合GAN和VAE的CPPN模型得到了一些令人满意的结果后,我们可以考虑未来在更复杂的真实、彩色的物体图像集上测试这种算法。
生成对抗模型
正如背景一节所讨论的,图像生成的挑战是得以对图像中的像素的联合概率分布进行建模。一旦我们有了所有像素逼真的概率分布,我们就可以从该概率分布中采样以生成逼真的图像。然而,由于真实图像非常复杂,人工建模概率分布太恶心了,所以诀窍在于使用神经网络将人类可理解的更简单的概率分布(如单位高斯随机变量)转化为与训练集中正常图像的真实概率分布类似的概率分布。生成概率分布的复杂性受限于神经网络架构的复杂性。在我们的例子中,生成图像的神经网络会是CPPN:
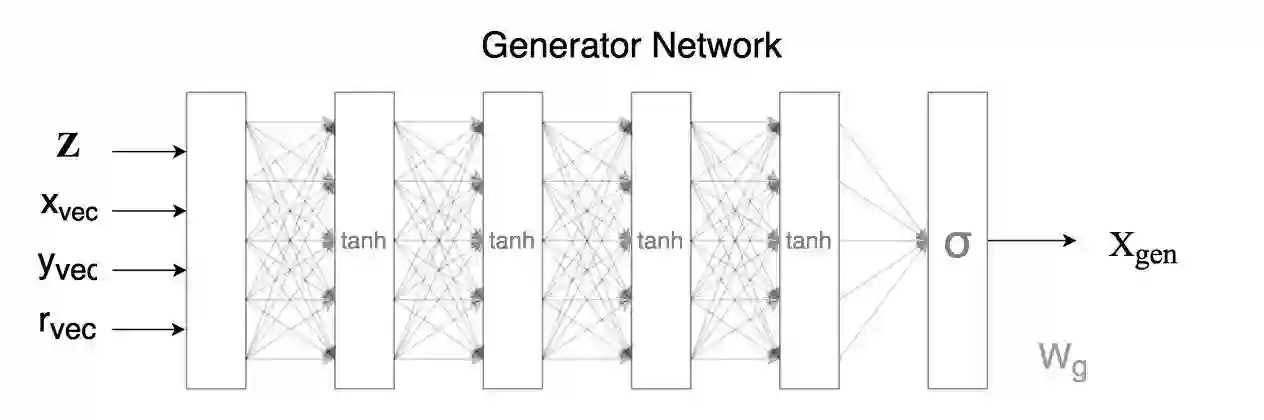
这个网络与上一篇文章中使用的网络属于一类。输入向量Z是从单位高斯随机数生成器中取得的32个实数组成的向量,这些实数均互相独立。向量x、y和r是我们想要计算的图像中的像素亮度的所有可能的坐标,因此对于26x26的图像,我们需要计算共计676个像素的亮度,以构成(32+676+676+676)个网络输入。有很重要的一点需要注意,每个像素强度将基于具有相同权重集合的完全相同的网络计算,所以如果内存有限的话,理论上我们也可以传给我们的网络(32+1+1+1)个输入并得到1个像素,在保持权重不变的前提下,重复这一步骤676次。
正如我们前面所看到的那样,保持网络的权重不变,我们可以通过控制输入Z向量获得丰富的输出图像集。这里的目标是训练我们的网络,对于我们传入的任何随机Z向量,其输出看起来像MNIST训练集中的图像。如果我们能够成功地做到这一点,那么我们就成功使用CPPN建模了MNIST图像的概率分布,并且我们可以通过采样简单的IID单元高斯变量来绘制随机图像。
但是,我们究竟如何训练这个网络的权重,以便将一串单位高斯随机数转换成一张随机MNIST图像呢?活在2013年的人会认为这是科幻小说。但是,如果你没有因为困在一个山洞里导致网络中断的话,那么过去几年你可能会听说过生成对抗网络框架。 GAN背后的概念是引入一个判别(Discriminator)网络来配合上面的生成(Generator)网络。
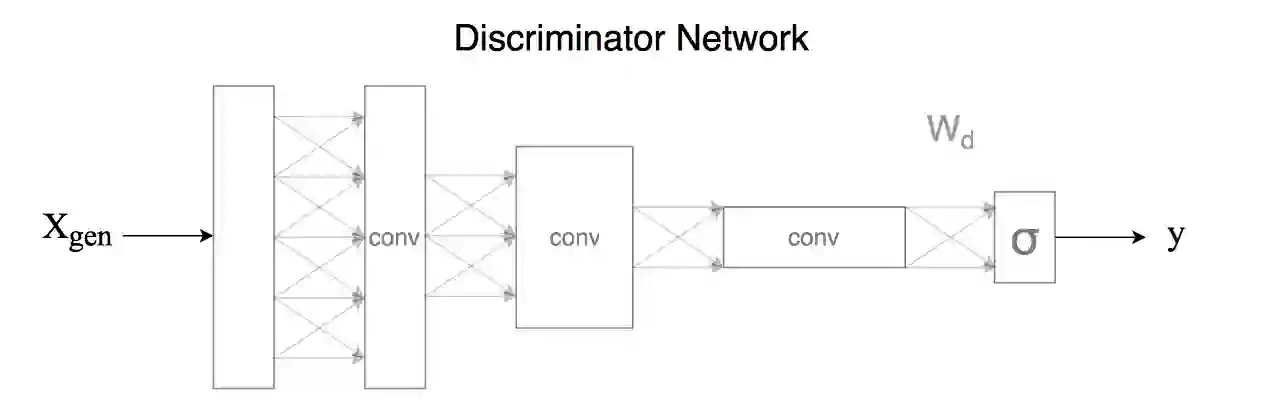
判别网络能够判断图像是否属于训练集。所以它将被用于检测不合法、不真实的MNIST数字的虚假图像。生成网络自然试图产生一个随机的MNIST数字图像,该图像可以欺骗判别网络。如果判别网络的表现足够好,能够达到人类的水平,而此时生成网络还能欺骗判别网络的话,这就意味着生成网络能够生成可以欺骗人类的假MNIST图像,也就意味着我们的工作已经完成了。
我依照DCGAN的类似方法,使用了三个简单的卷积网络层。卷积网络已被证明在图像分类方面非常出色,而且由于判别网络的输出在这种情况下是二元的(真/假),因此这是一个比数字分类更简单的分类问题。
判别网络的输入是图像,输出y是零到一之间的实数。如果y接近1,则判别网络坚信输入图像一定是合法的MNIST数字,如果y接近0,则判别网络坚信图像不是MNIST数字,而是一个试图愚弄和侵蚀其智能的欺诈尝试。如果判别网络的输出接近0.5,那么网络就会感到困惑和悲伤,丧失了它作为正常神经网络发挥功能的信心。
我们可以定义表现指标或损失函数来评估生成网络的表现:
G_loss = -log(y | G生成的图像)
可以看到,如果生成网络表现得很糟糕,那么判别网络的输出y将是一个非常小、接近于零的数字,而一个接近0的很小的数字的对数的相反数,会是一个很大的正数。
如果生成网络表现得很出色,狠狠地愚弄了判别网络,那么输出值y将是一个接近一的数字,而接近1的数字(如0.999)的对数的相反数,会是一个接近零的数字。
如果生成网络创建的图像导致判别网络很困惑,无法分辨出差异,则输出y将是一个接近0.5的数字,而G_loss会是一个接近-log 0.5也就是0.69的数字。
同理,我们可以用类似的方式评估判别网络的表现:
D_loss_real = -log( y | 真实训练样本)
D_loss_fake = -log( 1-y | G生成的图像)
D_loss = 0.5 * D_loss_real + 0.5 * D_loss_fake
如果判别网络表现出色,D_loss_real和D_loss_fake会同时趋向于零。反之,D_loss_real和D_loss_fake会同时趋向于一个很大的数。如果判别网络很困惑,D_loss_real和D_loss_fake将趋向于0.69,因而判别网络在识别真实图像和虚假图像时都存在困难。我们将D_loss定义为两者的平均值。
给定以上的损失函数,使用反向传播来训练判别网络将是非常自然的。反向传播将通过调整权重Wd来学习分辨真假MNIST数字。调整权重的梯度方向将使D_loss在遇到一组真实样本和生成网络新生成的虚假样本后变小。
生成网络同样可以通过反向传播训练。反向传播调整权重的梯度方向将使G_loss变小(因此同时使D_loss变大)。
注意训练生成网络需要花费更多精力,因为在反向传播的过程中,梯度首先将穿过判别网络层,至生成网络所生成的每个像素(因此首先将计算d(G_loss)/d(X_ij))。此后,对应于每个像素的每个损失微分的梯度将反向穿过生成网络的每个权重(Wg)。同时,因为我们使用CPPN算法生成图像,每个像素由权重相同的同一网络生成,只是输入的坐标(x, y, r)不同。由于权重是共享的,累计从像素层次反向传播到梯度的权重可以计算d(G_loss)/d(W_g)。这意味着,如果我们正对一组图像进行minibatch训练,训练CPPN意味着我们将处理batch中的batch。我花了一番工夫才弄清楚如何在TensorFlow中正确实现这个功能,因为许多默认忽略batch处理的快捷方式用不了了。
GAN模型的介绍就到这里,在本文的第二部分,我将介绍如何训练GAN,并融入VAE以解决训练GAN时发现的问题。
未完待续……
原文地址:http://blog.otoro.net/2016/04/01/generating-large-images-from-latent-vectors/






