从半年前飞桨发布 11 个全新模块,到今天又发布 9 大新开发产品,百度工程师已经「码力」全开。
今年 4 月份,百度首次公布了飞桨平台全景图和多个开发模块。在短短半年之后,百度又在深度学习开发者峰会上发布了 9 大全新开发产品。从 4 个端到端开发套件、飞桨 Master 模式,到图学习框架 PGL 等多种新工具,再到全新发布 EasyDL 专业版,今年第二次发布会诚意满满。
飞桨是一个源于产业的平台,它以 PaddlePaddle 框架为核心构建了一系列工具与组件。截止到当前,飞桨服务了超过 150 万开发者,超过 6.5 万的企业。总体上,基于飞桨的 16.9 万模型很多都是面向应用的,它们有很大一部分直接用于更复杂的产业环境。
正如百度首席技术官、深度学习技术及应用国家工程实验室主任王海峰所说:「深度学习正在推动人工智能进入工业化大生产阶段,而深度学习技术和平台也在不断发展,在未来的时间里也将继续发挥重要作用。我们秉承开源开放的理念,把飞桨平台开源开放,与所有开发者一起,推动科技发展、产业创新和社会进步。」
百度 AI 技术平台体系执行总监、深度学习技术及应用国家工程实验室副主任吴甜介绍到,飞桨是一个源于产业实践的深度学习开源开放平台。它集核心框架、模型库、端到端开发套件、工具组件和服务平台为一体,为深度学习模型的开发、训练和部署等提供标准化、自动化和模块化服务,降低人工智能技术应用门槛,激发技术创新,促进产业升级。
![]()
飞桨就像操作系统那样将机器学习的各个方面联系起来,尽可能为开发者,甚至是为非开发者提供足够强大、足够易用的操作体验。在今天的深度学习开发者峰会中,百度深度学习技术平台部总监马艳军发布了飞桨 21 项新模块与新升级。
从现在的飞桨全景图来看,百度的 AI 生态已经覆盖了人工智能中几乎所有应用方向。
如果读者看看第一版全景图,就会发现从核心框架到工具组件这半年优化了太多方面。马艳军表示:「虽然优化工作很多,但我们做得很投入,做的东西很有意义。飞桨平台的开发要求很高,但我们有能力做好,并做出特色和优势。」
在发布会上,马艳军花费了一个多小时来介绍飞桨的各种新工具。我们发现从最基础的 1.6 版本新特性,到图神经网络和多任务学习等全新的工具组件,再到 ERNIE 和 PaddleDetection 等端到端开发套件,整个飞桨大家庭有太多的更新,这篇文章也只是介绍最为吸引人的新工具,更多的细节可查阅这几天的系列解读文章。
百度 AI 技术平台体系执行总监、深度学习技术及应用国家工程实验室副主任吴甜表示,为了帮助制造业企业转型,百度为制造业提供了端到端的开发套件,包括 PaddleSeg、PaddleDetection 等套件。
在开发套件之外,吴甜还介绍了飞桨平台的 Master 模式,这是一种通过开放平台能力和模型,结合企业特有数据和业务流程,助力企业获得大数据和大模型性能的实现路径。吴甜说:「这种模式就像有一个 Master,我们可以跟着 Master 学习,学到自己场景适用的模型。」
以百度的 ERNIE 预训练模型为例,百度在这一模型的基础上,通过增加百科知识、篇章知识、语法知识等,形成基础模型。而企业可以使用这一预训练模型进行微调和迁移学习,最终在自身的定制化任务上的将工作量大幅降低。
不论是开发套件还是 Master 模式,它们都旨在于实践中更高效地构建更好的模型。
升级为套件的 ERNIE
因为自然语言的广泛应用,百度现在已将 ERNIE 从预训练模型升级为端到端开发套件,将模型作为强大的开发工具,为开发者提供模型性能上的支持。
ERNIE 是基于持续学习的语义理解预训练框架,使用多任务学习增量式构建预训练任务,最新发布的 ERNIE 2.0 中,新构建的预训练任务类型可以无缝的加入训练框架,持续的进行语义理解学习。
项目地址:https://github.com/PaddlePaddle/ERNIE
具体而言,在 ERNIE 预训练模型的基础上,百度为其添加了工具层、平台层和应用层,使其具有了服务能力。只需要调用相关的 API,开发者就可以使用语义表示方面的能力了。
此外,ERNIE 面对不同的用户的需求提出了一些改进。首先,考虑到自然语言处理任务的多样性,ERNIE 进行了多任务学习,用于满足不同任务对数据分布上的要求。其次,自然语言处理有领域上的限制约束。因此,ERNIE 根据面向的领域不同,提供了专门的领域模型,语料和数据都为不同的领域而定制。第三、ERNIE 在应用方面也提供了很多工具,通过使用这些工具,可实现 ERNIE 快速推理和推荐、对 ERNIE 进行模型压缩、快速部署,或根据业务需求进行定制化开发。
![]()
在升级到 2.0 版本之后,ERNIE 模型可以进行多任务和持续学习。同时,还有开源的压缩版本——ERNIE-Tiny。
对于经典的图像分割任务,马艳军表示,现在它在日常生活中越来越广泛,人体特效和智能抠图等应用也非常吸引人。PaddleSeg 在这些日常任务中有很好的效果,也很容易放到实际应用中去。
PaddleSeg 是产业级图像分割库,覆盖了 DeepLabv3+、U-Net、ICNet 三类主流的分割模型。通过统一的配置,帮助用户更便捷地完成从训练到部署的全流程图像分割应用。PaddleSeg 具备高性能、丰富的数据增强、工业级部署、全流程应用的特点。
项目地址:https://github.com/PaddlePaddle/PaddleSeg
![]()
PaddleSeg 目前已支持了 18 个训练模型,覆盖了几乎所有的主流网络架构。
PaddleDetection 是目标检测库,目的是为工业界和学术界提供大量易使用的目标检测模型。PaddleDetection 不仅性能完善,易于部署,同时能够灵活的满足算法研发需求。
项目地址:https://github.com/PaddlePaddle/PaddleDetection
PaddleDetection 目前已支持了超过 60 种模型,其中有很多近年来推出的模型。考虑到图像识别方面的模型较大的问题,PaddleDetection 还有很多小模型版本,这些都是通过模型结构搜索出来的,可以用于部署在移动端小型设备上。
此外,为了推动图像识别对下游图像处理任务方面的促进作用,PaddleDetection 具有模块化拼装的方式,可以很方便地和其他任务组合起来。
在工业领域,CTR 模型的应用非常广泛。本次发布会上,百度也介绍了他们的 ElasticCTR 模块。能够实现分布式训练 CTR 预估任务和 Serving 流程一键部署。为了帮助工业领域进行快速应用,百度提供了端到端的 CTR 训练和二次开发的解决方案。
从模型定义到模型部署,整个开发过程涉及的流程非常多,远不止常规的模型编写。与此同时,模型的应用领域也非常广,远不止常见的视觉、语言等方面。如果想要打造统一的系统,那么这两者都是要覆盖的。对于飞桨来说,全景图中的核心框架承载的是整个模型开发流程,而各种工具组件,旨在提供更便捷好用的成套模块。
如下四大工具,可以让你更好地部署手机端模型、更好地构建多任务学习、图神经网络和联邦学习模型。
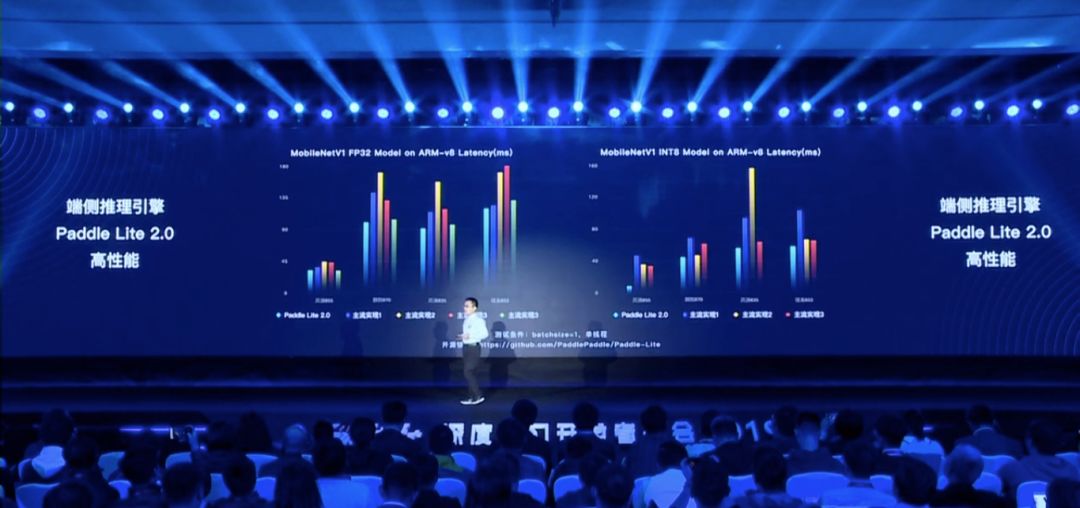
Paddle Lite 是 Paddle-Mobile 的升级版,定位支持包括手机移动端在内更多场景的轻量化高效预测,支持更广泛的硬件和平台,是一个高性能、轻量级的深度学习预测引擎。马艳军表示,Paddle Lite 2.0 具有极高的易用性,它拥有非常多的实际操作指南,从而帮助我们在不同的设备上快速部署模型。
项目地址:https://github.com/PaddlePaddle/Paddle-Lite
马艳军说:「Paddle Lite 2.0 对硬件的支持非常广泛,八种主流的硬件都没有问题,这一次该工具还新增了对华为 NPU 以及 FPGA 的支持。」有了如此多的硬件支持,在与 PaddlePaddle 无缝对接外,Paddle Lite 2.0 也兼容其他训练框架输出的模型。
除了好用外,性能也非常重要。如下图所示,Paddle Lite 2.0 在运行移动端深度学习模型 MobileNet 时的速度,尤其是在 Int8 精度下的推断速度有很大的优势。
Paddle Graph Learning(PGL)是一个高效易用的图学习框架,PGL 提供一系列的 Python 接口用于存储/读取/查询图数据结构,并且提供基于游走(Walk Based)以及消息传递(Message Passing)两种计算范式的计算接口。
利用这些接口,我们可以轻松的搭建最前沿的图学习算法,它覆盖大部分的图网络应用,包括图表示学习以及图神经网络。
项目地址:https://github.com/PaddlePaddle/PGL
百度在 PGL 的接口的设计上做了大量工作,用于提升图神经网络的易用性。同时,为了提升整体性能,PGL 可使用分布式训练的方法进行运行。最终,PGL 和飞桨本身的变长张量特性结合,性能更快。据马艳军介绍,PGL 可支持十亿节点、百亿边的训练。
PaddleFL(Federated Deep Learning)是一个开源联邦学习框架。据介绍,研究人员可以很轻松地用 PaddleFL 复制和比较不同的联邦学习算法。开发人员也可以从 PadderFL 中获益,因为用 PaddleFL 在大规模分布式集群中部署联邦学习系统很容易。
项目地址:https://github.com/PaddlePaddle/PaddleFL
PALM(PAddLE Multitask)是一个灵活易用的多任务学习框架,框架中内置了丰富的模型 backbone(BERT、ERNIE 等)、常见的任务范式(分类、匹配、序列标注、机器阅读理解等)和数据集读取与处理工具。对于典型的任务场景,用户几乎无需书写代码便可完成新任务的添加;对于特殊的任务场景,用户可通过对预置接口的实现来完成对新任务的支持。
项目地址:https://github.com/PaddlePaddle/PALM
在任务方面,PALM 支持了多个人工智能领域的多任务学习。以自然语言处理为例,PALM 可为模型提供自然语言理解、机器阅读理解、机器翻译等方面的多任务学习训练方法。而在计算机视觉方面则包括了图像识别、图像分类、语义分割、图像生成等方面。发布会上,马艳军表示,PALM 已支持 20 行代码进行多任务训练。
除了新工具的推出和旧有工具的优化,百度整体上对飞桨平台进行了一次较大的改进。对于飞桨核心框架(简称 Paddle)的易用性,马艳军说:「我们 6 月份发的版本已经集成了动态图机制,在这次的发布中,动态图编程又有很多新优化。」
飞桨有一个比较好的地方,即最开始设计的时候就充分地考虑了动态图和静态图的兼容性。马艳军表示,采用动态计算图,其呈现的不只有易用性,在动态图的背后,它与静态计算图复用了很多底层性能优化技术,因此飞桨性能和效率的兼顾会做的会比较完善。
全新升级后的飞桨,易用性大幅提升,动态图全新升级、新增大量算子库、优化 API 接口,技术文档更加完善。大规模分布式训练性能领先,分布式 GPU 训练相比其他主流实现可以获得 20%-100% 的速度提升,分布式 CPU 训练最大吞吐量可达竞品的 6 倍以上。官方支持模型库极大丰富,官方模型从 60 多个增加到了 100 多个,提供下载的预训练模型已经超过 200 个。
马艳军表示:「Paddle 新版本只需要改动 5 行代码,就能把单机程序变成分布式训练程序。」这免除了大量的手动工作,将复杂的调配过程都留给了框架本身。
最后,百度在文档上也下了很大功夫,这次更新后,整个中文文档有了很大变化。因此从 API 层面到训练机制、再到开发文档都有显著的改善,开发者用起来很方便,体验上就会有显著的改善。
本次更新多达 21 项新模块与新升级,马艳军说:「这些新的发布和升级都是显性的一些工作,我们在底层核心技术还做了更多的优化,团队的能力也越来越强。这一领域国内人才非常稀缺,随着飞桨平台越来越完善,我们团队得到了更多的锻炼,团队也越来越强大。」
吴甜表示,从一年多之前开始,飞桨有了更强的战略定位,并加大了对飞桨的投入。「在这一年多的时间里,大家把原来的工作都做得更优秀,并同时去做更多的开源与推广。」
在半年时间里做出如此多的更新,确实很多部门通力合作的结果。通过今年两次的大型发布会,我们能清晰地感受到飞桨平台以及 PaddlePaddle 框架变得越来越成熟。最终,飞桨也许会形成完整的系统,将复杂的机制隐藏在底层,将最好用的工具给用户,这会是非常令人兴奋的一件事。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content
@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com