通过代码学Sutton强化学习:SARSA、Q-Learning和Expected SARSA 时序差分算法训练CartPole

这一期我们进入第六章:时序差分学习(Temporal-Difference Learning)。TD Learning本质上是加了bootstrapping的蒙特卡洛(MC),也是model-free的方法,但实践中往往比蒙特卡洛收敛更快。我们选取OpenAI Gym中经典的CartPole环境来讲解TD。更多相关内容,欢迎关注 本公众号 MyEncyclopedia。
CartPole OpenAI 环境
如图所示,小车上放了一根杆,杆会根据物理系统定理因重力而倒下,我们可以控制小车往左或者往右,目的是尽可能地让杆保持树立状态。

CartPole 观察到的状态是四维的float值,分别是车位置,车速度,杆角度和杆角速度。下表为四个维度的值范围。给到小车的动作,即action space,只有两种:0,表示往左推;1,表示往右推。
| Min | Max | |
|---|---|---|
| Cart Position | -4.8 | 4.8 |
| Cart Velocity | -Inf | Inf |
| Pole Angle | -0.418 rad (-24 deg) | 0.418 rad (24 deg) |
| Pole Angular Velocity | -Inf | Inf |
离散化连续状态
从上所知,CartPole step() 函数返回了4维ndarray,类型为float32的连续状态空间。对于传统的tabular方法来说第一步必须离散化状态,目的是可以作为Q table的主键来查找。下面定义的State类型是离散化后的具体类型,另外 Action 类型已经是0和1,不需要做离散化处理。
State = Tuple[int, int, int, int]
Action = int
离散化处理时需要考虑的一个问题是如何设置每个维度的分桶策略。分桶策略会决定性地影响训练的效果。原则上必须将和action以及reward强相关的维度做细粒度分桶,弱相关或者无关的维度做粗粒度分桶。举个例子,小车位置本身并不能影响Agent采取的下一动作,当给定其他三维状态的前提下,因此我们对小车位置这一维度仅设置一个桶(bucket size=1)。而杆的角度和角速度是决定下一动作的关键因素,因此我们分别设置成6个和12个。
以下是离散化相关代码,四个维度的 buckets=(1, 2, 6, 12)。self.q是action value的查找表,具体类型是shape 为 (1, 2, 6, 12, 2) 的ndarray。
class CartPoleAbstractAgent(metaclass=abc.ABCMeta):
def __init__(self, buckets=(1, 2, 6, 12), discount=0.98, lr_min=0.1, epsilon_min=0.1):
self.env = gym.make('CartPole-v0')
env = self.env
# [position, velocity, angle, angular velocity]
self.dims_config = [(env.observation_space.low[0], env.observation_space.high[0], 1),
(-0.5, 0.5, 1),
(env.observation_space.low[2], env.observation_space.high[2], 6),
(-math.radians(50) / 1., math.radians(50) / 1., 12)]
self.q = np.zeros(buckets + (self.env.action_space.n,))
self.pi = np.zeros_like(self.q)
self.pi[:] = 1.0 / env.action_space.n
def to_bin_idx(self, val: float, lower: float, upper: float, bucket_num: int) -> int:
percent = (val + abs(lower)) / (upper - lower)
return min(bucket_num - 1, max(0, int(round((bucket_num - 1) * percent))))
def discretize(self, obs: np.ndarray) -> State:
discrete_states = tuple([self.to_bin_idx(obs[d], *self.dims_config[d]) for d in range(len(obs))])
return discrete_states
train() 方法串联起来 agent 和 env 交互的流程,包括从 env 得到连续状态转换成离散状态,更新 Agent 的 Q table 甚至 Agent的执行policy,choose_action会根据执行 policy 选取action。
def train(self, num_episodes=2000):
for e in range(num_episodes):
print(e)
s: State = self.discretize(self.env.reset())
self.adjust_learning_rate(e)
self.adjust_epsilon(e)
done = False
while not done:
action: Action = self.choose_action(s)
obs, reward, done, _ = self.env.step(action)
s_next: State = self.discretize(obs)
a_next = self.choose_action(s_next)
self.update_q(s, action, reward, s_next, a_next)
s = s_next
choose_action 的默认实现为基于现有 Q table 的 -greedy 策略。
def choose_action(self, state) -> Action:
if np.random.random() < self.epsilon:
return self.env.action_space.sample()
else:
return np.argmax(self.q[state])
抽象出公共的基类代码 CartPoleAbstractAgent 之后,SARSA、Q-Learning和Expected SARSA只需要复写 update_q 抽象方法即可。
class CartPoleAbstractAgent(metaclass=abc.ABCMeta):
@abc.abstractmethod
def update_q(self, s: State, a: Action, r, s_next: State, a_next: Action):
pass
TD Learning的精髓
在上一期,本公众号 MyEncyclopedia 的通过代码学Sutton强化学习4:21点游戏蒙特卡洛解得最佳策略介绍了Monte Carlo方法,知道MC需要在环境中模拟直至最终结局。若记 为t步以后的最终return,则 MC online update 版本更新为:
可以认为 向着目标为 更新了一小步。
而TD方法可以只模拟下一步,得到 ,而余下步骤的return, 用已有的 来估计,或者统计上称作bootstrapping。这样 TD 的更新目标值变成 ,整体online update 公式则为:
概念上,如果只使用下一步 值然后bootstrap称为 TD(0),用于区分使用多步后的reward的TD方法。另外,变化的数值 称为TD error。
另外一个和Monte Carlo的区别在于一般TD方法保存更精细的Q值, ,并用Q值来boostrap,而MC一般用V值也可用Q值。
SARSA: On-policy TD 控制
SARSA的命名源于一次迭代产生了五元组 。SARSA利用五个值做 action-value的 online update:
对应的Q table更新实现为:
class SarsaAgent(CartPoleAbstractAgent):
def update_q(self, s: State, a: Action, r, s_next: State, a_next: Action):
self.q[s][a] += self.lr * (r + self.discount * (self.q[s_next][a_next]) - self.q[s][a])
SARSA 在执行policy 后的Q值更新是对于针对于同一个policy的,完成了一次策略迭代(policy iteration),这个特点区分于后面的Q-learning算法,这也是SARSA 被称为 On-policy 的原因。下面是完整算法伪代码。
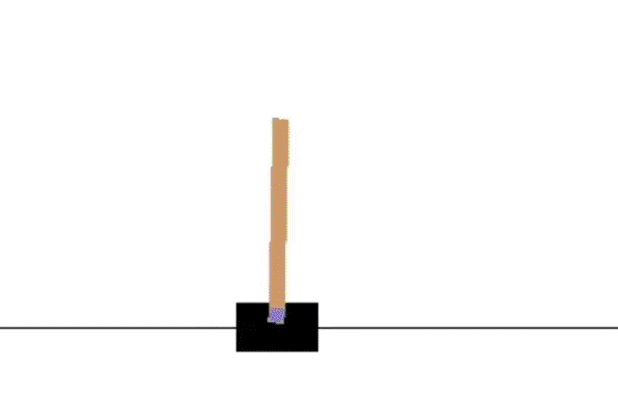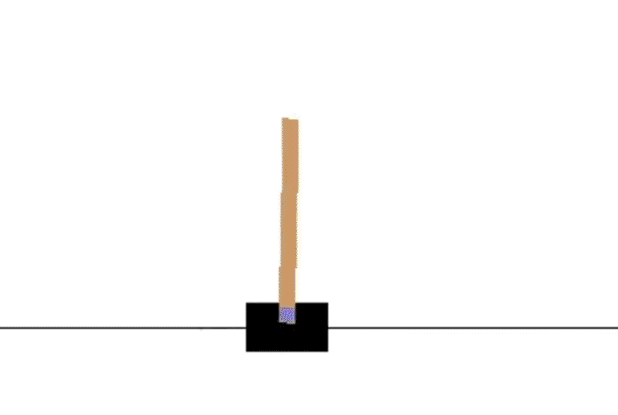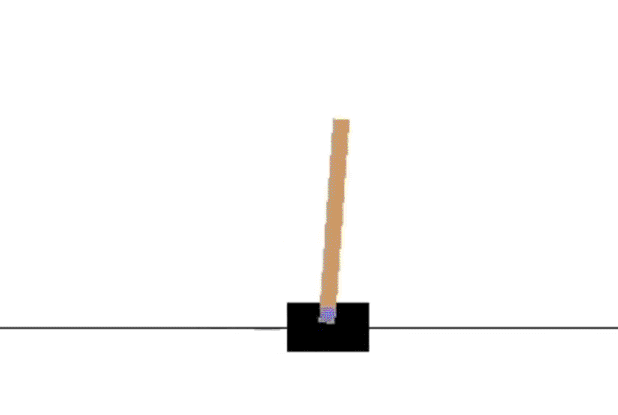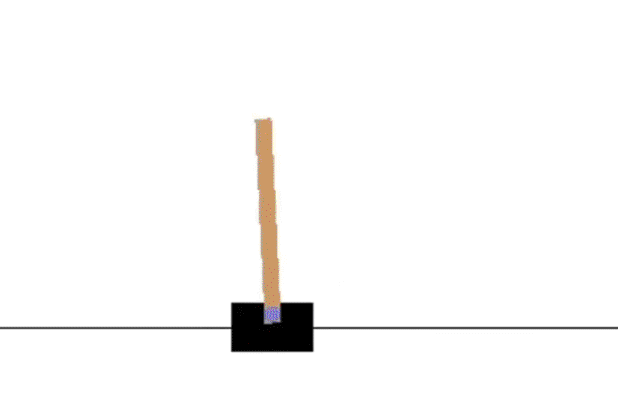
SARSA 训练分析
SARSA收敛较慢,1000次episode后还无法持久稳定,后面的Q-learning 和 Expected Sarsa 都可以在1000次episode学习长时间保持不倒的状态。
Q-Learning: Off-policy TD 控制
Q-Learning 是深度学习时代前强化学习领域中的著名算法,它的 online update 公式为:
对应的 update_q() 方法具体实现
class QLearningAgent(CartPoleAbstractAgent):
def update_q(self, s: State, a: Action, r, s_next: State, a_next: Action):
self.q[s][a] += self.lr * (r + self.discount * np.max(self.q[s_next]) - self.q[s][a])
本质上用现有的Q table中最好的action来bootrap 对应的最佳Q值,推导如下:
Q-Learning 被称为 off-policy 的原因是它并没有完成一次policy iteration,而是直接用已有的 Q 来不断近似 。
对比下面的Q-Learning 伪代码和之前的 SARSA 版本可以发现,Q-Learning少了一次模拟后的 ,这也是Q-Learning 中执行policy和预估Q值(即off-policy)分离的一个特征。
Q-Learning 训练分析
Q-Learning 1000次episode就可以持久稳定住。
SARSA 改进版 Expected SARSA
Expected SARSA 改进了 SARSA 的地方在于考虑到了在某一状态下的现有策略动作分布,以此来减少variance,加快收敛,具体更新规则为:
注意在实现中,update_q() 不仅更新了Q table,还显示更新了执行policy 。
class ExpectedSarsaAgent(CartPoleAbstractAgent):
def update_q(self, s: State, a: Action, r, s_next: State, a_next: Action):
self.q[s][a] = self.q[s][a] + self.lr * (r + self.discount * np.dot(self.pi[s_next], self.q[s_next]) - self.q[s][a])
# update pi[s]
best_a = np.random.choice(np.where(self.q[s] == max(self.q[s]))[0])
n_actions = self.env.action_space.n
self.pi[s][:] = self.epsilon / n_actions
self.pi[s][best_a] = 1 - (n_actions - 1) * (self.epsilon / n_actions)
同样的,Expected SARSA 1000次迭代也能比较好的学到最佳policy。
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏


