使用 TensorFlow 在 CERN LHC 一次性重构数千颗粒子


发布人:Jan Kieseler(来自 CERN,EP/CMG)


在 CERN LHC(大型强子对撞机)等大型对撞机上,高能粒子束发生碰撞,从而按照众所周知的方程式 E=mc2 从碰撞能量中产生大量甚至可能未知的粒子。这些新产生的粒子大多数都不稳定,并且几乎会立即衰变为更稳定的粒子。检测这些衰变产物并精确测量其性质是了解整个高能碰撞过程的关键,并且有可能阐明暗物质起源等重大问题。
为此,碰撞相互作用点将被大型探测器环绕,以尽可能覆盖衰减产物所有可能的方向和能量。这些探测器可进一步拆分为子探测器,由每个子探测器收集补充信息。最里面的探测器最接近相互作用点,是包含多个层级的跟踪器。与照相机类似,每一层都可以检测带电粒子穿过的空间位置,从而可以访问其轨迹。与强磁场结合,该轨迹使得粒子电荷和粒子动量得以进入。
跟踪器仅用于测量轨迹,同时最大限度限制粒子的任何进一步相互作用和散射,而下一个子探测器层则用于完全阻止粒子。通过完全停止粒子,这些热量计可以提取初始粒子能量,还可以检测中性粒子。能穿过这些热量计的唯一粒子是 μ 子,可通过构成最外层探测器外壳的附加 μ 子腔室进行识别,并使用与跟踪器相同的探测原理。
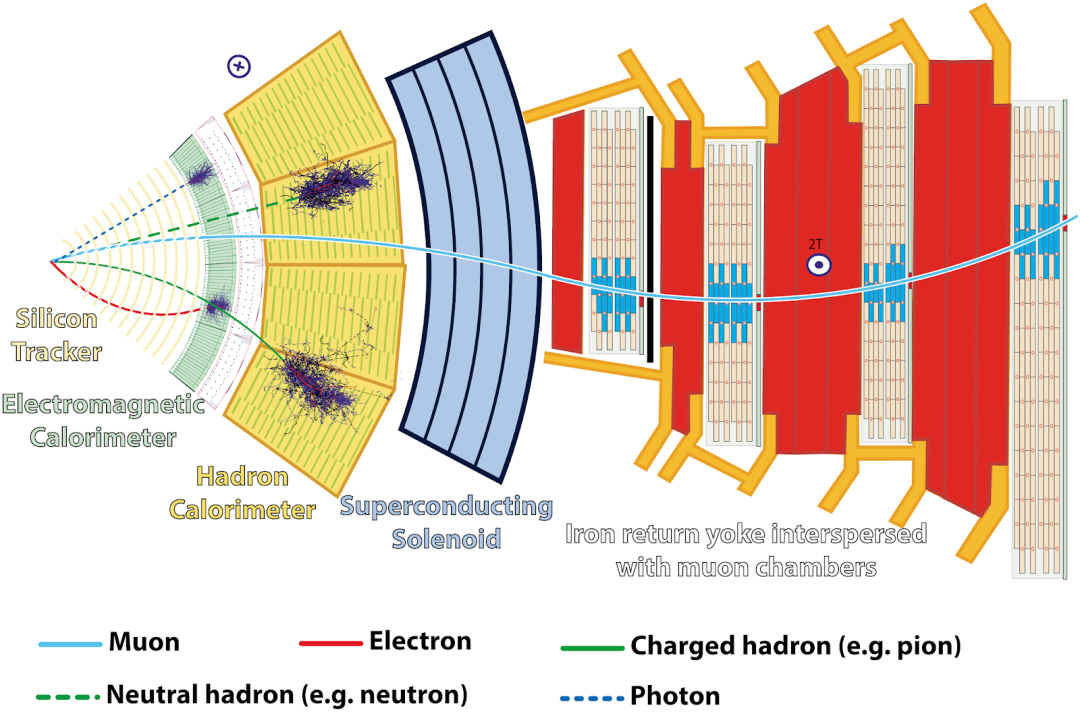
CMS 探测器的布局,显示与子探测器相互作用的不同粒子种类
合并所有此类子探测器收集的信息以重建最终粒子是一项艰巨的任务,不仅因为我们希望达到最佳的物理性能,而且因为开发和调整重建算法所需的计算资源和人力。特别是对于设计用于收集空前数据量的高亮度 LHC(CERN LHC 的扩展),在 40 MHz 的给定碰撞速率且每次碰撞中同时发生多达 200 次交互作用的情况下,将通过所有子探测器产生大约一百万个信号,因此这些算法必须要有出色的表现。
即使是使用触发器,对感兴趣事件进行快速、逐步的过滤,磁盘收集到的总数据量仍然有数个拍字节 (PB),因此高效算法在所有阶段都都必不可少。
高能物理学中的经典重构算法在很大程度上依赖于单个步骤的分解和大量专业(物理学)知识。尽管算法的表现相当不错,但是开发这些算法所需要的理想假设仍然会限制性能,因此机器学习方法经常用于优化经典重构的粒子,并将其纳入越来越多的重构链中。机器学习方法得益于所有探测器组件和物理过程的非常精确的模拟,在多个数量级上均显示有效,因此可以在很短的时间内非常轻松地生成大量标记数据。这进而促成基于神经网络的识别和回归算法的兴起,并在 Compact Muon Solenoid(CMS) 实验的软件框架中纳入 TensorFlow 作为标准推理引擎。
机器学习重构方法还具有以下优势:在构建时算法必须具备可自动优化的能力,并且需要损失函数来训练以量化最终的重建目标。相比之下,经典方法通常不需要定义这样一个包容性的量化指标就可以进行优化,并且需要手动调整参数,这需要许多专家参与进来,并且需要花费大量人力来开发新算法而不是调整现有算法。因此,一般来说,改为使用差异化的机器学习算法(例如深度神经网络)也可以帮助更有效地利用人力资源。
但是,将基于机器学习的算法扩展到从碰撞中重构粒子的第一步(而不是仅优化已重建的粒子)面临两大主要挑战:数据结构,以及将重构解析为最小化问题。
由于包含多个子探测器,每个子探测器都有自己的几何形状,因此探测器数据高度不规则。但是,即使在子探测器(如跟踪器)中,也可以根据物理属性设计几何形状,在靠近相互作用点的位置分辨率较高,而在较远的位置则较低。此外,各个跟踪器层并非密集封装在一起,而是在各层之间具有相当大的空间,并且在每个事件中,实际上只有一小部分传感器处于活动状态,进而会改变事件之间的输入量。因此,尽管具有良好的性能和高度优化的实现方式,但要求有规则网格的神经网络(例如卷积神经网络体系结构)仍然不适用。
图神经网络可以弥补这一缺陷,并且理论上可以从探测器的几何形状进行提取。最近,在优化高能物理中已重构粒子的背景下,我们研究了来自计算机科学领域的数种图神经网络建议。但是,由于数据的输入维数很高,因此许多建议无法用于直接通过撞击重构粒子,因此需要自定义解决方案。其中一个解决方案是 GravNet,通过使用稀疏的动态邻接矩阵并执行大多数操作而没有内存开销,从而在构建时显著减少了资源需求,同时保持了良好的物理性能。
GravNet
https://link.springer.com/article/10.1140%2Fepjc%2Fs10052-019-7113-9
TensorFlow 在这一方面尤其有效,可以轻松实现自定义内核并将其加载到图形中,并为融合操作集成自定义分析梯度。只有组合自定义内核和网络结构,才能将完整的物理事件加载到 GPU 内存中,在其上训练网络并执行推理。
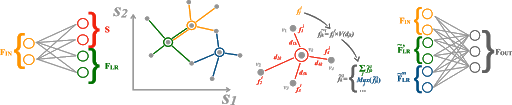
GravNet 层架构(从左到右):将点特征投影到特征空间 FLR 和低维坐标空间 S 中;在 S 中确定 k 个最近的邻接特征;累积距离加权邻接特征的均值和最大值;并将累积的特征与原始特征相结合
由于许多重构任务(甚至是已重构粒子的优化)都依赖于未知数量的输入,因此 TensorFlow 最近纳入并支持不规则数据结构的操作在原则上开启了许多新的可能性。尽管集成还不足以构建完整的神经网络体系结构,但是,将来对不规则数据结构的完全支持是重要的一步,可以将 TensorFlow 甚至更深层次地集成到重构算法中,从而淘汰某些自定义内核。
不规则数据结构
https://tensorflow.google.cn/guide/ragged_tensor
使用深度神经网络直接通过撞击重构粒子面临的第二大挑战在于:训练网络从未知数量的输入中预测未知数量的粒子。有很多算法和训练方法可用于检测密集数据中的密集对象(例如图像),但是虽然在某些情况下可以放宽对密集数据的要求,但这些算法中的大多数仍然依赖于密集或者具有清晰边界的对象,这样才能利用对象的锚定框或中心点。然而,探测器中的粒子通常会在很大程度上重叠,并且粒子的稀疏性不允许定义中心点或清晰的边界。此问题的一种解决方案是对象凝结,其中对象属性在每个对象的至少一个代表性凝结点处凝结,而凝结点可以由网络通过高置信度分数自由选择。
对象凝结
https://link.springer.com/article/10.1140/epjc/s10052-020-08461-2
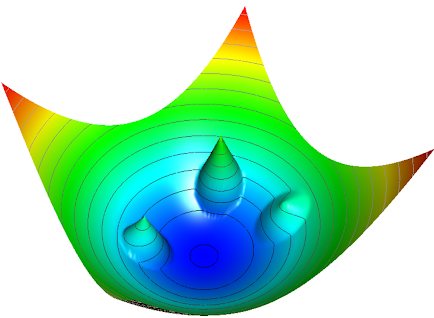
为了解决歧义,使用电势函数将其他点聚集在它们所属的对象周围(如上所示)。但是,这些电势以可调整的方式通过置信度分数进行缩放,因此网络应该执行的分割量可调整到一个点,如果我们仅希望了解最终对象属性,那么在该点上,除凝结点之外的所有点都可以自由浮动。
该算法的某些部分与上一篇论文中提出的方法非常相似,但目标完全不同。尽管先前的方法构成了一种非常强大的分割算法,通过朝向中心点将像素向图像中的集群对象移动,但此处的凝结点直接承载了对象的属性,并且通过选择电势函数,可以将集群空间与输入空间完全分离。后者在具有重叠粒子的稀疏探测器数据的适用性方面具有重大意义,但也没有在概念上区分 “stuff” 和 “things”,为单阶段全景分割提供新的视角。
不过,我们回到粒子重构,如对应论文(对象凝结)所示,即使在与经典算法的理想假设非常接近的简化问题上,对象凝结也可以胜过经典粒子重构算法。因此,对象凝结可替代直接通过撞击重构粒子的经典传统方法。
以此项颇有前景的研究为基础,我们正在研究将此方法扩展到高粒度量热计的模拟事件中。高粒度量热计即为欧洲核子研究组织 (CERN) 计划的 CMS 实验新子探测器,带有 200 万个传感器,涵盖了特别具有挑战性的“前行”区域,该区域靠近产生最多粒子的入射光束。与已发布的概念验证相比,这种现实的环境更具挑战性,并且需要优化网络结构以及更多自定义 TensorFlow 操作(在 github 上的开发存储库中可找到相关操作),同时需要使用 DeepJetCore 作为与高能物理中常用数据格式对接的接口。目前,研究人员特别关注如何实现快速 k 近邻算法,这是 GravNet 的关键构建块,可以处理较大的输入维度;同时,其他操作的不规则实现,以及对象凝结损耗的实现也受到关注。
开发存储库
https://github.com/cms-pepr/HGCalML
DeepJetCore
https://github.com/DL4Jets/DeepJetCore
总而言之,深度神经网络在重构任务中的应用正呈现出一种从优化以经典方式重构的粒子到直接重构粒子及其特性的转变,这种转变是一种可优化且高度可并行化的方式,可以应对未来在人力和计算资源需求方面的挑战。这项开发将带来更多的自定义实现,并将使用 TensorFlow 和 tf.keras 中的更多前沿功能,例如不规则数据结构,因此,我们可以预见,高能物理重构开发者与 TensorFlow 开发者之间的联系将越来越紧密。
我衷心感谢 Google 公司员工 Thiru Palanisamy 和 Josh Gordon 给予的支持,感谢他们共同帮助撰写这篇博文,以及提供的积极反馈。

点击“阅读原文”访问 TensorFlow 官网

不要忘记“一键三连”哦~

分享

点赞

在看




