Python 爬取 B 站数据分析,宋智孝李光洙谁最受中国粉丝喜爱


作者 | 左伊雅
责编 | 胡巍巍
《Running Man》是韩国SBS电视台在《星期天真好》单元推出的户外竞技真人秀节目。
节目致力于打造一个不同于Real variety的新型态娱乐节目。每期有不同的主题,由不同的嘉宾参演,分为不同的队伍进行比赛,通过完成各种游戏任务,最后获胜一方将获得称号或奖品。
成员组成包括原六位成员刘在石、池石镇、金钟国、HAHA(河东勋)、宋智孝、李光洙 ,以及两位新成员全昭旻、梁世灿。
抓取数据
自从限韩令发布后,Running man在除B站以外的各大视频网站均下架,所以本文从B站出发,抓取相关视频的所有评论。
由于相关视频非常多,本文选择了最具代表性,点击量观看次数最多的视频。
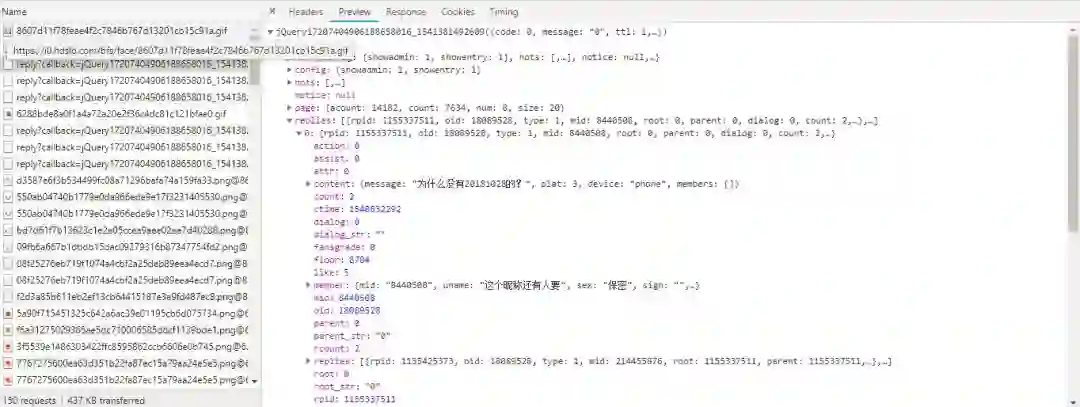
进入这个页面后开始抓包(https://www.bilibili.com/video/av18089528?from=search&seid=16848360519725142300)。
不断点击下一页,可以发现reply?callback=这个文件一直在出现。

打开其中一个文件以后可以看到每一面的评论都在里面;只需构建出类似的URL就可以把所有的评论都爬下来啦。
分析一下这个URL:
https://api.bilibili.com/x/v2/replycallback=jQuery17201477141935656543_1541165464647&jsonp=jsonp&pn=368&type=1&oid=18089528&sort=0&_=1541165714862
pn是页面数,_对应距离1971年1月1日的秒数,直接用time.time就可以获得,其余参数保持不变。数据格式是Json,但是B站有点小狡猾啊~
它把所有的Json数据都存在jQuery17201477141935656543_1541165464647这个里面。
所以提取的时候要处理一下(Talk is cheap,show me the code)。
html=requests.get(url,headers=headers).text
html=json.loads(html.split('(',1))[1][:-1])
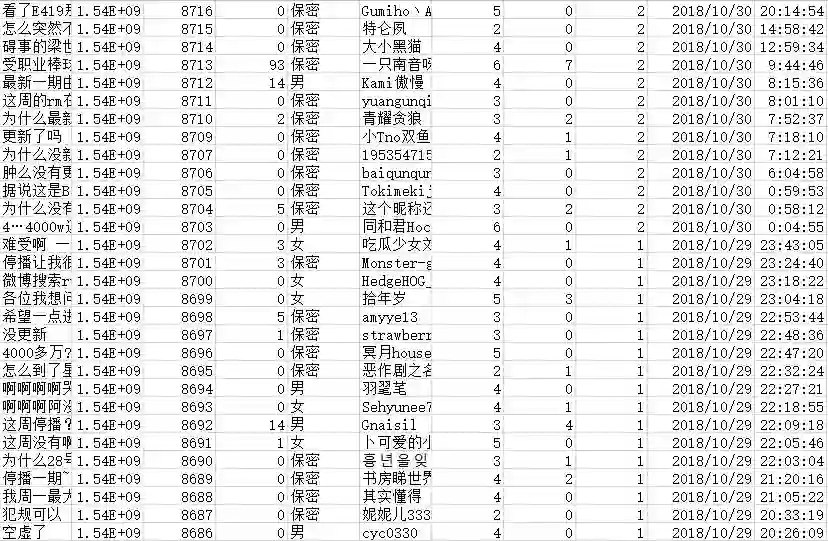
最后我们把所有的评论都抓取下来存入Excel中,数据格式是这样子的:
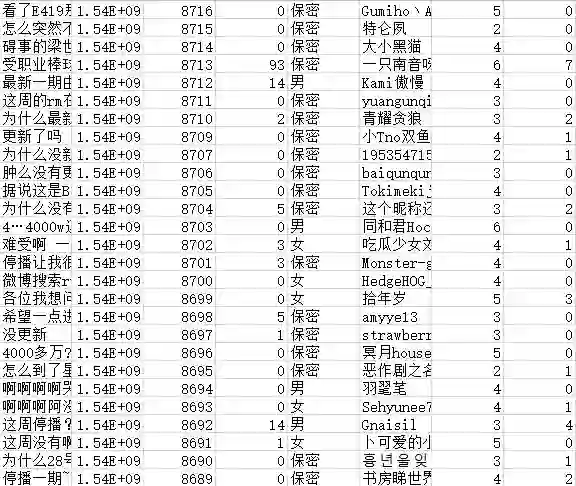
写入CSV的时候一定要记得encoding='utf-8',就因为少了这个,数据总会乱码,因为各种奇葩的原因(点了一下,拉宽了一下,原地保存一下)。
数据清洗
对于B站的各种缺失数据,就直接用0替换;对于诗歌类的评论,它存到CSV时是一句占一行,而它的其余信息都会存到最后一行。
所以在处理时,把前面的n-1行打包append到n行的评论中,再把n-1行删除;对于B站返回的时间(类似于1540882722);用time.strftime('%Y-%m-%d %H:%M:%S,time.localtime())变换成2018/11/12 22:15:15。
数据分析
清理后一共得到7513*11条数据,接下来对数据进行一些分析,数据分析通过Python和R完成。
男女分布
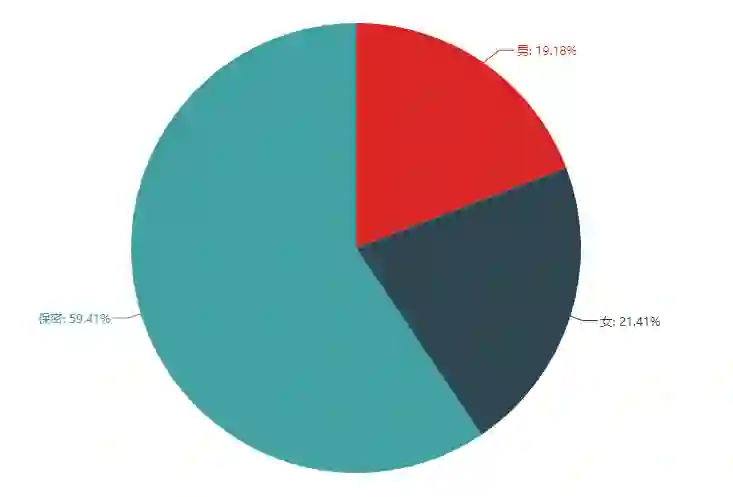
从饼图可以看出,近六成的人选择保密个人信息,公开信息显示女生仅比男生多3%。这个结论是出乎意料的。原来不论男女都很喜欢Running man。
def male(sex):
att=['男','女','保密']
val=[]
for i in att:
val.append(sex.count(i))
pie = Pie("", "性别饼图", title_pos="right", width=1200, height=600)
pie.add("", att, val, label_text_color=None, is_label_show=True, legend_orient='vertical',
is_more_utils=True, legend_pos='left')
pie.render("sexPie.html")

评论周分布
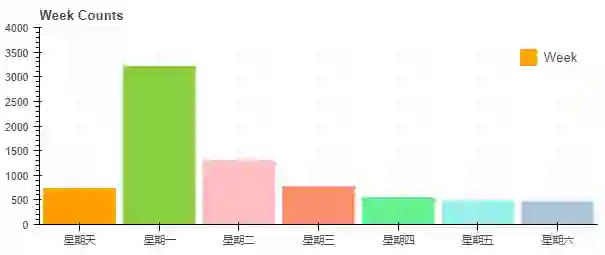
Running man在韩国的更新时间是每周天下午,但是要到周一B站才会有所更新。
因此从评论周分布图可以看到,星期一的评论数是远远大于其他时间的,其次是星期二和星期天,正好在Runnning man 更新前后,对比其他时间段评论数有一定增长。
def ana_week(week):
weeks=['星期天','星期一','星期二','星期三','星期四','星期五','星期六']
output_file('week_bar.html')
count=[]
for i in sorted(set(week)):
if not numpy.isnan(i):
count.append(week.count(i))
source = ColumnDataSource(data=dict(weeks=weeks, counts=count,color=['orange','yellowgreen','pink','darksalmon','lightgreen','paleturquoise','lightsteelblue']))
p=figure(x_range=weeks, y_range=(0,4000), plot_height=250, title="Week Counts",
toolbar_location=None, tools="")
p.vbar(x='weeks', top='counts', color='color',width=0.9, legend="Week", source=source)
p.legend.orientation = "horizontal"
p.legend.location = "top_right"
show(p)
评论时间分布
除了每周评论数,对于评论数的日趋势也十分好奇,大家一般会在什么时间段内观看评论呢?
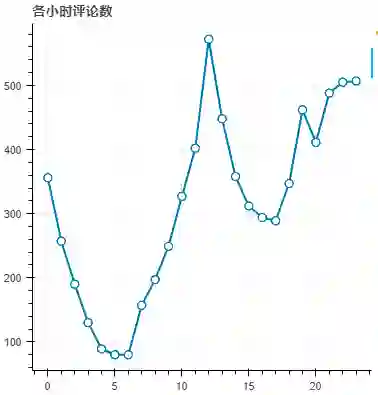
根据上图可以看到,在6点以后迎来一个爆炸性增涨,在11点-13点之间达到峰值,其次是在15点-17点之间迎来第二波小高潮。
在晚间,除了20点有一定下降外,评论数都接近500条。而午夜评论数最少,不过还是有不少夜猫子啊。
def ana_hour(hour):
h,k=[],[]
for i in range(len(hour)):
if isinstance(hour[i],str):
h.append(hour[i][:2])
for i in sorted(set(h)):
k.append(h.count(i))
print(k)
output_file('hour_line.html')
p = figure(plot_width=400,title='各小时评论数', plot_height=400)
p.line(sorted(set(h)), k, line_width=2)
p.circle(sorted(set(h)), k, fill_color="white", size=8)
show(p)
评论字数与点赞数
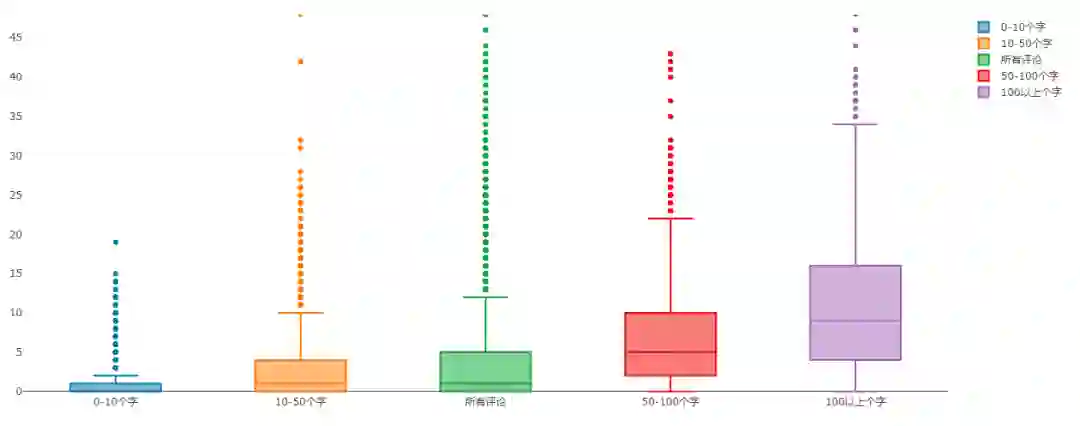
对比每条评论的字数与点赞次数,从上图可以看到,评论的字数越多,获得赞的概率就越大:100字以上的评论获得赞的平均次数远高于100字以下的评论,而那些10个字以内的评论基本没有获得赞,所以只要你是认真评论写出大家的心声,就能获得大家的认同。
def com_zan(com,zan):
q,w,e,r,t=[],[],[],[],[]
for i in range(len(com)):
if len(com[i])<10:
q.append(zan[i])
if 10<=len(com[i])<50:
w.append(zan[i])
if 50<=len(com[i])<100:
e.append(zan[i])
if 100<=len(com[i]):
r.append(zan[i])
a=go.Box(y=q,name='0-10个字')
b=go.Box(y=w,name='10-50个字')
c=go.Box(y=e,name='50-100个字')
d=go.Box(y=r,name='100以上个字')
e=go.Box(y=zan,name='所有评论')
data=[a,b,e,c,d]
layout = go.Layout(legend=dict(font=dict(size=16)),orientation=270)
fig = go.Figure(data=data, layout=layout)
plotly.offline.plot(data)

情感分析
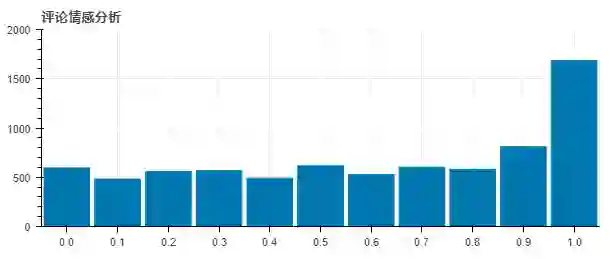
将大家的评论分别进行情感分析,越接近1说明正面情感越强烈;相反越靠近0负面情绪越强。
从上图可以看到,虽然有近600人的评论是非常负能量,但是绝大多数的人都是1分、0.9分。
在Running man给我们带来欢乐与感动的同时,大家对Running man是满满的宠爱啊。
def snownlp(com):
q=[]
for i in com:
s=SnowNLP(i)
q.append(round(s.sentiments,1))
emotion=[]
count=[]
for i in sorted(set(q)):
emotion.append(str(i))
count.append(q.count(i))
#count=[596, 481, 559, 566, 490, 617, 528, 601, 581, 809, 1685]
#emotion=['0.0', '0.1', '0.2', '0.3', '0.4', '0.5', '0.6', '0.7', '0.8', '0.9', '1.0']
output_file('评论情感分析.html')
source = ColumnDataSource(data=dict(emotion=emotion, counts=count))
p = figure(x_range=emotion, y_range=(0, 2000), plot_height=250, title="评论情感分析",
toolbar_location=None, tools="")
p.vbar(x='emotion', top='counts', width=0.9, source=source)
p.legend.orientation = "horizontal"
show(p)

话题度排行

一直都很好奇在观众心中哪个mc的话题度最高,所以做了一个话题度排行。从上图可以看到haha是最具话题性的mc(这个结果有点出乎意料呢)其次是李光洙和宋智孝。
因为笔者统计的是2018年的Running man ,所以Gary的数据是有点凄惨的。对比两个新成员,全妹的话题度比世赞高的不是一点点。
def hot(com):
#print(com)
output_file('各成员话题度.html')
jzg=['金钟国','钟国','能力者']
gary=['gary','狗哥']
haha=['haha','HAHA','哈哈']
qsm=['全昭敏','全妹','全昭body']
lsz=['梁世赞','世赞','小不点']
name=['池石镇','刘在石','宋智孝','李光洙','金钟国','gary','haha','全昭敏','梁世赞']
csz,lzs,szx,lgz,jzg,gary,haha,qsm,lsz=[],[],[],[],[],[],[],[],[]
for i in com:
if '池石镇'in i or'石镇' in i or'鼻子'in i:
csz.append(i)
if '刘在石'in i or '在石' in i or '大神' in i or '蚂蚱' in i:
lzs.append(i)
if '宋智孝' in i or '智孝'in i or '懵智'in i or '美懵'in i:
szx.append(i)
if '李光洙'in i or '光洙'in i or '一筐猪'in i:
lgz.append(i)
if '金钟国'in i or '钟国'in i or '能力者'in i:
jzg.append(i)
if 'gary'in i or'狗哥'in i:
gary.append(i)
if 'haha'in i or 'HAHA'in i or '哈哈'in i:
haha.append(i)
if '全昭敏'in i or '全妹'in i or'全昭body'in i:
qsm.append(i)
if '梁世赞'in i or'世赞'in i or'小不点'in i:
lsz.append(i)
count=[len(csz),len(lzs),len(szx),len(lgz),len(jzg),len(gary),len(haha),len(qsm),len(lsz)]
source = ColumnDataSource(data=dict(name=name, counts=count,color=['orange',
'yellowgreen', 'pink', 'darksalmon','lightgreen','paleturquoise','lightsteelblue',
'hotpink','yellow']))
p = figure(x_range=name, y_range=(0, 600), plot_height=250, title="话题度排行",
toolbar_location=None, tools="")
p.vbar(x='name', top='counts', color='color', width=0.9, source=source)
p.legend.orientation = "horizontal"
show(p)
Running man一直都不缺CP,前有周一情侣Gary和宋智孝,权力夫妇刘在石和金钟国,老年line刘在石和池石镇,我兄我弟金钟国和haha,背叛者联盟必触cross。
现在又有国民兄妹刘在石和全昭敏,麻浦兄妹宋智孝和haha,烤肉line金钟国haha等等。
他们的关系错综复杂,所以笔者打算好好扒一扒观众眼中的各种line。
成员关系矩阵
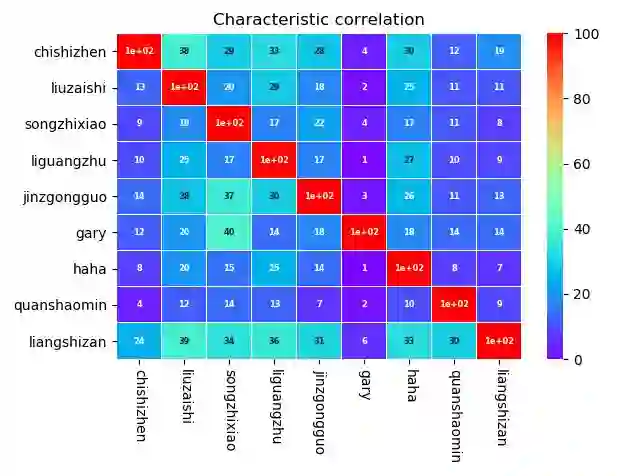
满分为100分,可以看到池石镇和刘在石;刘在石和李光洙;金钟国和宋智孝;Gary和宋智孝;haha和李光洙;全昭敏和宋智孝的相关性均非常高,其中Gary和宋智孝的相关性居然达到40,也就是说评论中如果有Gary那么有四成的概率会出现宋智孝,周一情侣真的是深入人心。
其次是宋智孝和金钟国,看来之前还一直有人说他俩会结婚也不是空穴来潮;而梁世赞与其余成员的相关性都很高,这说明大家都不怎么单独提到他,希望世赞可以早日找到自己的定位;获得观众的认可!
def network_edg_csv(com):
df=pandas.DataFrame(columns=['池石镇','刘在石','宋智孝','李光洙','金钟国','gary','haha','全昭敏','梁世赞'],index=['池石镇','刘在石','宋智孝','李光洙','金钟国','gary','haha','全昭敏','梁世赞'])
df.loc[:,:]=0.0
for i in com:
if (i in '池石镇'in i or'石镇' in i or'鼻子'in i):
df['池石镇']['池石镇'] = df['池石镇']['池石镇'] + 1
if('刘在石'in i or '在石' in i or '大神' in i or '蚂蚱' in i):
df['池石镇']['刘在石'] = df['池石镇']['刘在石'] + 1
df['刘在石']['池石镇'] = df['刘在石']['池石镇'] + 1
#成员关系矩阵df计算方式:在同一个评论中,如果同时出现刘在石和池石镇,那么他们的联系值+1;再用(刘在石和池石镇的联系值/池石镇出现在评论的次数)*100得到他们的相关性系数。
for i in df.index:
s=df.loc[i][i]
for j in ['池石镇','刘在石','宋智孝','李光洙','金钟国','gary','haha','全昭敏','梁世赞']:
df.loc[i][j]=df.loc[i][j]/s*100
fig=pyl.figure() names=['chishizhen','liuzaishi','songzhixiao','liguangzhu','jinzgongguo','gary','haha','quanshaomin','liangshizan']
ax=fig.add_subplot(figsize=(100, 100))
ax=seaborn.heatmap(df, cmap='rainbow',linewidths = 0.05, vmax = 100,vmin = 0,annot = True, annot_kws = { 'size': 6, 'weight': 'bold'})
pyl.xticks(np.arange(9) + 0.5, names,rotation=-90)
pyl.yticks(np.arange(9) + 0.5, names,rotation=360)
ax.set_title('Characteristic correlation') # 标题设置
pyl.show()
社交网络关系网

在社交网络关系网中,按红、黄、绿、蓝将联系的紧密程度划分为四个等级,其中红色代表联系非常紧密,而蓝色是不紧密。
可以看到,李光洙、haha、刘在石三人联系非常紧密,同时金钟国和宋智孝的关系也非常密切。对于Gary,自从他退出Running man以后,各成员和他的联系都非常小。
def network():
data=pandas.read_csv('run_edge.csv',encoding='utf-8',engine='python')
G = nx.Graph()
pyl.figure(figsize=(20,20))
for i in data.index: G.add_weighted_edges_from([(data.loc[i]['one'],data.loc[i]['two'],data.loc[i]['count'])])
n=nx.draw(G)
pyl.show()
pos=nx.spring_layout(G)
large=[(x,y) for (x,y,z)in G.edges(data=True) if z['weight']>100]
middle = [(x, y) for (x, y, z) in G.edges(data=True) if 50<z['weight'] <= 100]
middlev = [(x, y) for (x, y, z) in G.edges(data=True) if 10 < z['weight'] <= 50]
small=[(x,y)for (x,y,z)in G.edges(data=True) if z['weight']<=10]
nx.draw_networkx_nodes(G,pos,alpha=0.6)
nx.draw_networkx_edges(G,pos,edgelist=large,width=3,edge_color='red')
nx.draw_networkx_edges(G, pos, edgelist=middle, width=2, edge_color='yellow')
nx.draw_networkx_edges(G, pos, edgelist=middlev, width=1, edge_color='yellowgreen')
nx.draw_networkx_edges(G, pos, edgelist=small, width=0.5, edge_color='green')
nx.draw_networkx_labels(G,pos,font_size=10,font_family='simhei')
pyl.axis('off')
pyl.show()
词云图

这个词云图我是用R做的,但是R的词云图背景是要全黑和全白,所以就放弃了给词云加个图案的想法。
回到词云图,可以看出,大家对于节目本身,各位成员的讨论是很多的,同时在评论里也表达了自己对Running man各种喜爱之情。
def comment(com):
df=pandas.DataFrame()
pl=[]
stopword=['的','了','是','。',',',' ','?','!','就','\n',':','“','”','*','=','(',')','吗','吧','(',')','・','[',']','、','°','?','!','.','-','`',';',',','《','》']
for i in range(len(com)):
cut_list=jieba.cut(com[i],cut_all=False)
w='/'.join(cut_list)
w=w.split('/')
for j in w:
if not j in stopword:
pl.append(j)
for s in set(pl):
if len(s)>1:
if pl.count(s) > 50:
x = {}
x['word']=s.strip('\n')
x['count']=pl.count(s)
df=df.append(x,ignore_index=True)
print(df)
df.to_csv('jieba.csv',encoding='utf-8',index=False, mode='a', header=False)
print(df)
#下面用R生成词云图
library(wordcloud2)
data<-read.csv(header=FALSE,'C:/Users/伊雅/PycharmProjects/untitled/venv/share/doc/
jieba.csv')
f=data.frame(data)
f
wordcloud2(f)
最后,希望Running man 给我们带来越来越多欢乐,收视率越来越好噢。
相关代码上传到Github(https://github.com/zuobangbang/running-man--Bilibili)。
作者简介:左伊雅,目前在南京某211大学读研二,喜欢数据挖掘和爬虫,如果你对该方向感兴趣,可关注作者公众号:zuobangbang
推荐阅读: