BERT蒸馏完全指南|原理/技巧/代码
来自:李rumor
小朋友,关于模型蒸馏,你是否有很多问号:
-
蒸馏是什么?怎么蒸BERT? -
BERT蒸馏有什么技巧?如何调参? -
蒸馏代码怎么写?有现成的吗?
今天rumor就结合Distilled BiLSTM/BERT-PKD/DistillBERT/TinyBERT/MobileBERT/MiniLM六大经典模型,带大家把BERT蒸馏整到明明白白!

模型蒸馏原理
Hinton在NIPS2014[1]提出了知识蒸馏(Knowledge Distillation)的概念,旨在把一个大模型或者多个模型ensemble学到的知识迁移到另一个轻量级单模型上,方便部署。简单的说就是用小模型去学习大模型的预测结果,而不是直接学习训练集中的label。
在蒸馏的过程中,我们将原始大模型称为教师模型(teacher),新的小模型称为学生模型(student),训练集中的标签称为hard label,教师模型预测的概率输出为soft label,temperature(T)是用来调整soft label的超参数。
蒸馏这个概念之所以work,核心思想是因为好模型的目标不是拟合训练数据,而是学习如何泛化到新的数据。所以蒸馏的目标是让学生模型学习到教师模型的泛化能力,理论上得到的结果会比单纯拟合训练数据的学生模型要好。
如何蒸馏
蒸馏发展到今天,有各种各样的花式方法,我们先从最基本的说起。
之前提到学生模型需要通过教师模型的输出学习泛化能力,那对于简单的二分类任务来说,直接拿教师预测的0/1结果会与训练集差不多,没什么意义,那拿概率值是不是好一些?于是Hinton采用了教师模型的输出概率q,同时为了更好地控制输出概率的平滑程度,给教师模型的softmax中加了一个参数T。
有了教师模型的输出后,学生模型的目标就是尽可能拟合教师模型的输出,新loss就变成了:
其中CE是交叉熵(Cross-Entropy),y是真实label,p是学生模型的预测结果, 是蒸馏loss的权重。这里要注意的是,因为学生模型要拟合教师模型的分布,所以在求p时的也要使用一样的参数T。另外,因为在求梯度时新的目标函数会导致梯度是以前的 ,所以要再乘上 ,不然T变了的话hard label不减小(T=1),但soft label会变。
有同学可能会疑惑:如果可以拟合prob,那直接拟合logits可以吗?
当然可以,Hinton在论文中进行了证明,如果T很大,且logits分布的均值为0时,优化概率交叉熵和logits的平方差是等价的。
BERT蒸馏
在BERT提出后,如何瘦身就成了一个重要分支。主流的方法主要有剪枝、蒸馏和量化。量化的提升有限,因此免不了采用剪枝+蒸馏的融合方法来获取更好的效果。接下来将介绍BERT蒸馏的主要发展脉络,从各个研究看来,蒸馏的提升一方面来源于从精调阶段蒸馏->预训练阶段蒸馏,另一方面则来源于蒸馏最后一层知识->蒸馏隐层知识->蒸馏注意力矩阵。
Distilled BiLSTM
Distilled BiLSTM[2]于2019年5月提出,作者将BERT-large蒸馏到了单层的BiLSTM中,参数量减少了100倍,速度提升了15倍,效果虽然比BERT差不少,但可以和ELMo打成平手。
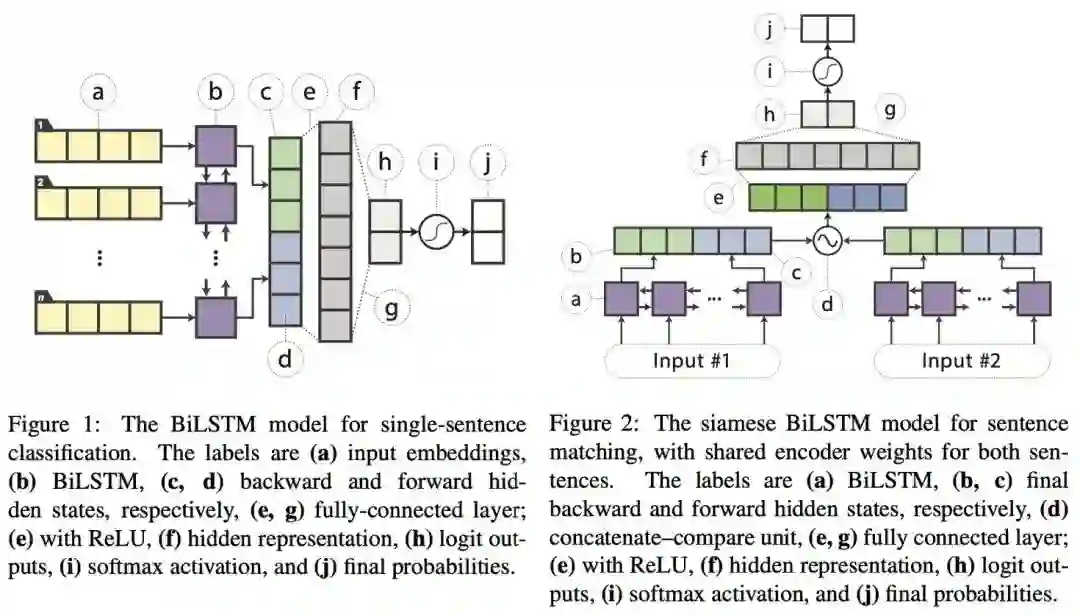
Distilled BiLSTM的教师模型采用精调过的BERT-large,学生模型采用BiLSTM+ReLU,蒸馏的目标是hard labe的交叉熵+logits之间的MSE(作者经过实验发现MSE比上文的 更好)。
同时因为任务数据有限,作者基于以下规则进行了10+倍的数据扩充:
-
用[MASK]随机替换单词 -
基于POS标签替换单词 -
从样本中随机取出n-gram作为新的样本
但由于没有消融实验,无法知道数据增强给模型提升了多少最终效果。
BERT-PKD (EMNLP2019)
既然BERT有那么多层,是不是可以蒸馏中间层的知识,让学生模型更好地拟合呢?
BERT-PKD[3]不同于之前的研究,提出了Patient Knowledge Distillation,即从教师模型的中间层提取知识,避免在蒸馏最后一层时拟合过快的现象(有过拟合的风险)。
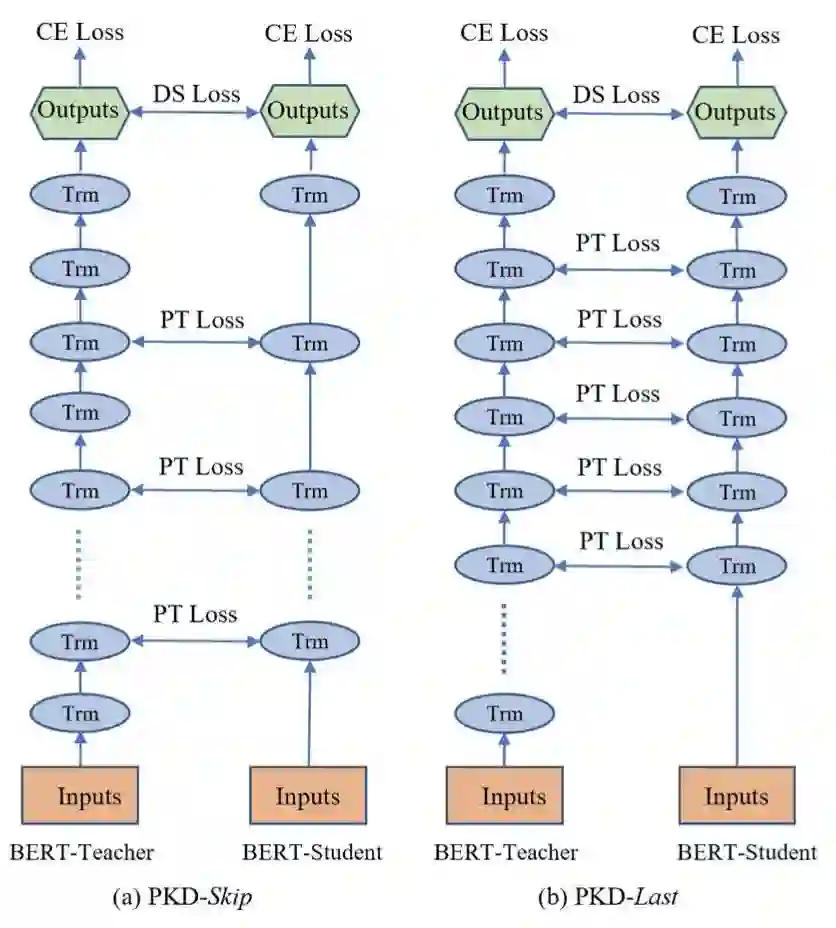
对于中间层的蒸馏,作者采用了归一化之后MSE,称为PT loss。
教师模型采用精调好的BERT-base,学生模型一个6层一个3层。为了初始化一个更好的学生模型,作者提出了两种策略,一种是PKD-skip,即用BERT-base的第[2,4,6,8,10]层,另一种是PKD-last,采用第[7,8,9,10,11]层。最终实验显示PKD-skip要略好一点点(<0.01)。
DistillBERT (NIPS2019)
之前的工作都是对精调后的BERT进行蒸馏,学生模型学到的都是任务相关的知识。HuggingFace则提出了DistillBERT[4],在预训练阶段进行蒸馏。将尺寸减小了40%,速度提升60%,效果好于BERT-PKD,为教师模型的97%。
DistillBERT的教师模型采用了预训练好的BERT-base,学生模型则是6层transformer,采用了PKD-skip的方式进行初始化。和之前蒸馏目标不同的是,为了调整教师和学生的隐层向量方向,作者新增了一个cosine embedding loss,蒸馏最后一层hidden的。最终损失函数由MLM loss、教师-学生最后一层的交叉熵、隐层之间的cosine loss组成。从消融实验可以看出,MLM loss对于学生模型的表现影响较小,同时初始化也是影响效果的重要因素:

TinyBERT(EMNLP2019)
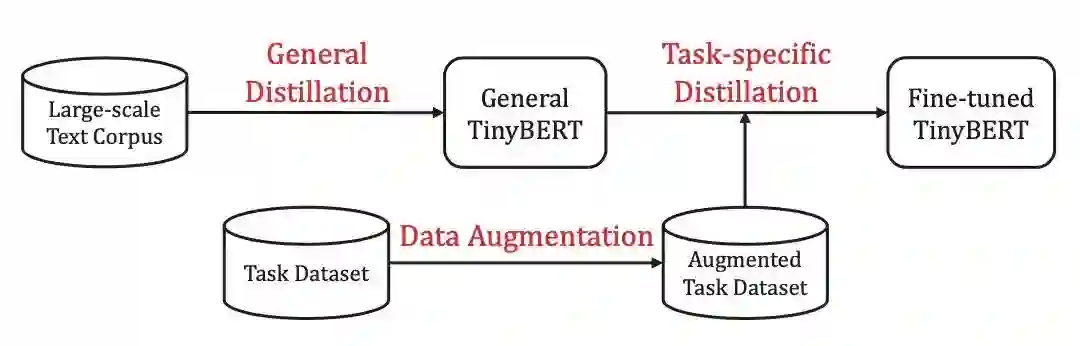
既然精调阶段、预训练阶段都分别被蒸馏过了,理论上两步联合起来的效果可能会更好。
TinyBERT[5]就提出了two-stage learning框架,分别在预训练和精调阶段蒸馏教师模型,得到了参数量减少7.5倍,速度提升9.4倍的4层BERT,效果可以达到教师模型的96.8%,同时这种方法训出的6层模型甚至接近BERT-base,超过了BERT-PKD和DistillBERT。
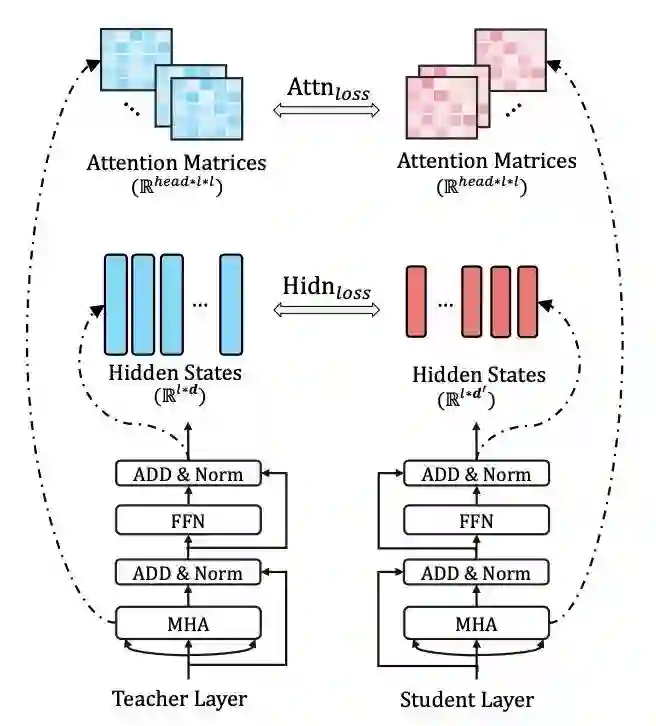
TinyBERT的教师模型采用BERT-base。作者参考其他研究的结论,即注意力矩阵可以捕获到丰富的知识,提出了注意力矩阵的蒸馏,采用教师-学生注意力矩阵logits的MSE作为损失函数(这里不取attention prob是实验表明前者收敛更快)。另外,作者还对embedding进行了蒸馏,同样是采用MSE作为损失。
于是整体的loss计算可以用下式表示:
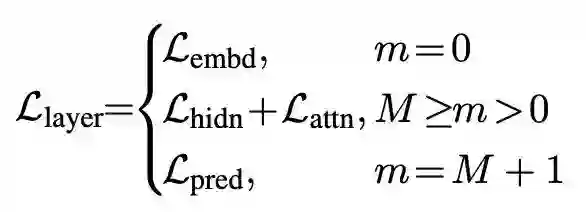
其中m表示层数。 表示教师-学生最后一层logits的交叉熵。
最后的实验中,预训练阶段只对中间层进行了蒸馏;精调阶段则先对中间层蒸馏20个epochs,再对最后一层蒸馏3个epochs。
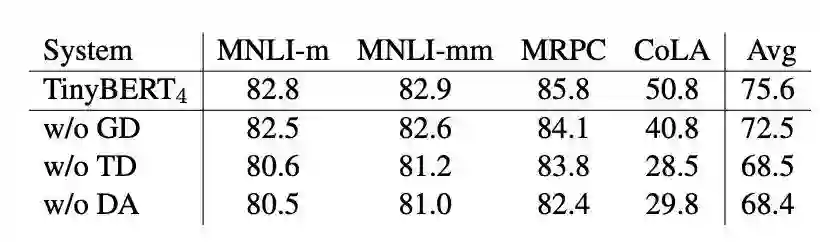
上图是各个阶段的消融实验。GD(General Distillation)表示预训练蒸馏,TD(Task Distillation)表示精调阶段蒸馏,DA(Data Augmentation)表示数据增强,主要用于精调阶段。从消融实验来看GD带来的提升不如TD或者DA,TD和DA对最终结果的影响差不多(有种蒸了这么半天还不如多标点数据的感觉=.=)。
MobileBERT(ACL2020)
前文介绍的模型都是层次剪枝+蒸馏的操作,MobileBERT[6]则致力于减少每层的维度,在保留24层的情况下,减少了4.3倍的参数,速度提升5.5倍,在GLUE上平均只比BERT-base低了0.6个点,效果好于TinyBERT和DistillBERT。
MobileBERT压缩维度的主要思想在于bottleneck机制,如下图所示:
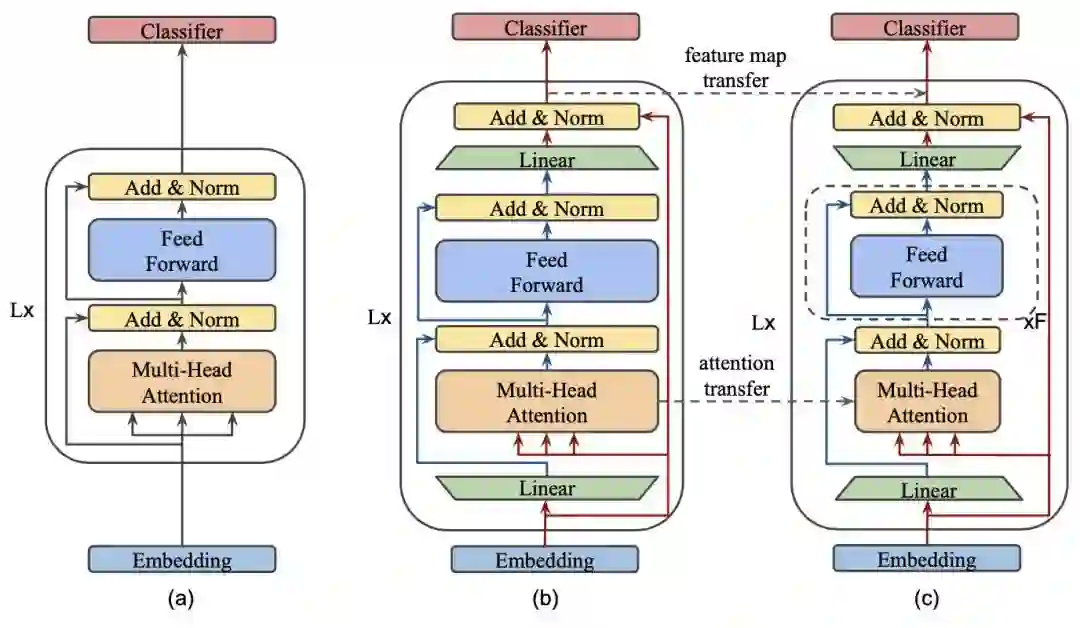
其中a是标准的BERT,b是加入bottleneck的BERT-large,作为教师模型,c是加入bottleneck的学生模型。Bottleneck的原理是在transformer的输入输出各加入一个线性层,实现维度的缩放。对于教师模型,embedding的维度是512,进入transformer后扩大为1024,而学生模型则是从512缩小至128,使得参数量骤减。
另外,作者发现在标准BERT中,多头注意力机制MHA和非线性层FFN的参数比为1:2,这个参数比相比其他比例更好。所以为了维持比例,会在学生模型中多加几层FFN。
MobileBERT的蒸馏中,作者先用b的结构预训练一个BERT-large,再蒸馏到24层学生模型中。蒸馏的loss有多个:
-
Feature Map Transfer:隐层的MSE -
Attention Transfer:注意力矩阵的KL散度 -
Pre-training Distillation:
同时作者还研究了三种不同的蒸馏策略:直接蒸馏所有层、先蒸馏中间层再蒸馏最后一层、逐层蒸馏。如下图:
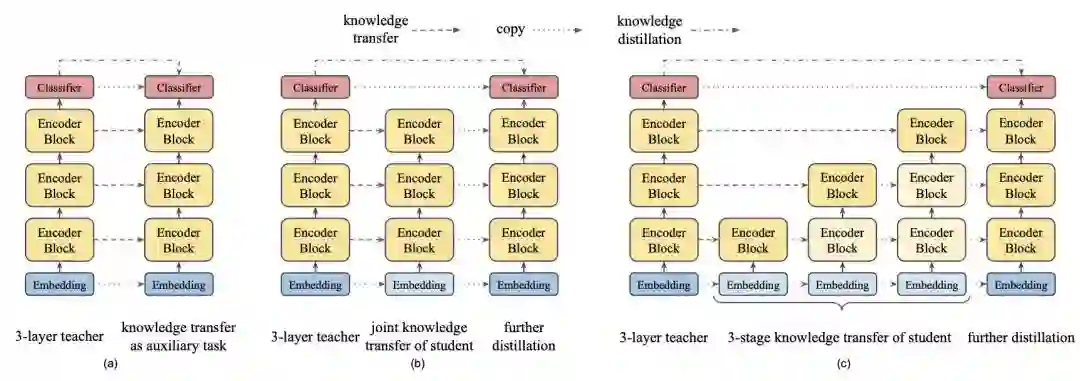
最后的结论是逐层蒸馏效果最好,但差距最大才0.5个点,性价比有些低了。。
MobileBERT还有一点不同于之前的TinyBERT,就是预训练阶段蒸馏之后,作者直接在MobileBERT上用任务数据精调,而不需要再进行精调阶段的蒸馏,方便了很多。
MiniLM
之前的各种模型基本上把BERT里面能蒸馏的都蒸了个遍,但MiniLM[7]还是找到了新的蓝海——蒸馏Value-Value矩阵:
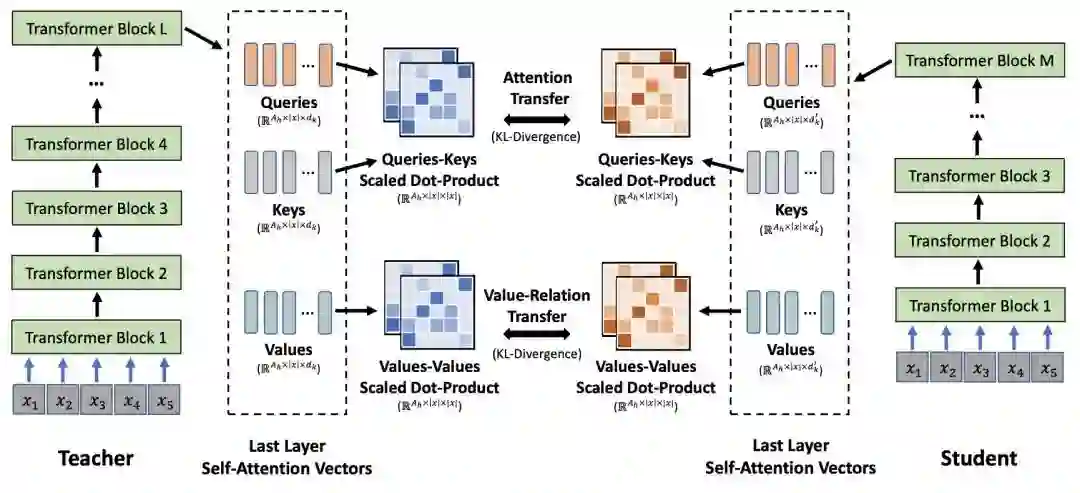
Value-Relation Transfer可以让学生模型更深入地模仿教师模型,实验表明可以带来1-2个点的提升。同时作者考虑到学生模型的层数、维度都可能和教师模型不同,在实验中只蒸馏最后一层,并且只蒸馏这两个矩阵的KL散度,简直是懒癌福音。
另外,作者还引入了助教机制。当学生模型的层数、维度都小很多时,先用一个维度小但层数和教师模型一致的助教模型蒸馏,之后再把助教的知识传递给学生。
最终采用BERT-base作为教师,实验下来6层的学生模型比起TinyBERT和DistillBERT好了不少,基本是20年性价比数一数二的蒸馏了。
BERT蒸馏技巧
介绍了BERT蒸馏的几个经典模型之后,真正要上手前还是要把几个问题都考虑清楚,下面就来讨论一些蒸馏中的变量。
剪层还是减维度?
这个选择取决于是预训练蒸馏还是精调蒸馏。预训练蒸馏的数据比较充分,可以参考MiniLM、MobileBERT或者TinyBERT那样进行剪层+维度缩减,如果想蒸馏中间层,又不想像MobileBERT一样增加bottleneck机制重新训练一个教师模型的话可以参考TinyBERT,在计算隐层loss时增加一个线性变换,扩大学生模型的维度:
对于针对某项任务、只想蒸馏精调后BERT的情况,则推荐进行剪层,同时利用教师模型的层对学生模型进行初始化。从BERT-PKD以及DistillBERT的结论来看,采用skip(每隔n层选一层)的初始化策略会优于只选前k层或后k层。
用哪个Loss?
看完原理后相信大家也发现了,基本上每个模型蒸馏都用的是不同的损失函数,CE、KL、MSE、Cos魔幻组合,自己蒸馏时都不知道选哪个好。。于是rumor我强行梳理了一番,大家可以根据自己的任务目标挑选:
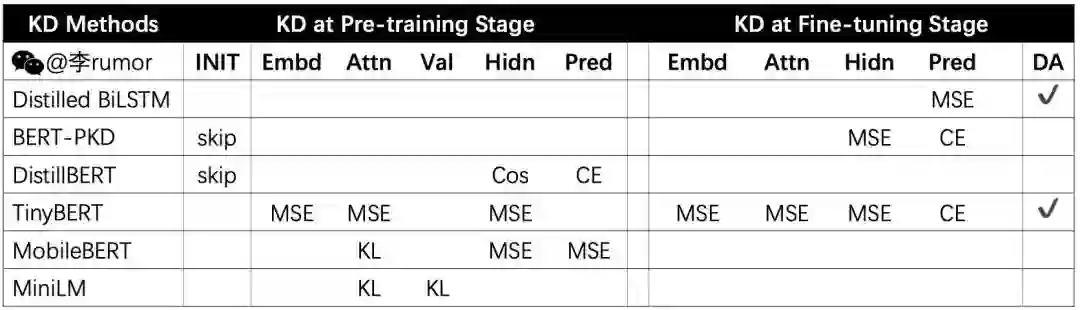
对于hard label,使用KL和CE是一样的,因为,训练集不变时label分布是一定的。但对于soft label则不同了,不过表中不少模型还是采用了CE,只有Distilled BiLSTM发现 更好。个人认为可以CE/MSE/KL都试一下,但MSE有个好处是可以避免T的调参。
中间层输出的蒸馏,大多数模型都采用了MSE,只有DistillBERT加入了cosine loss来对齐方向。
注意力矩阵的蒸馏loss则比较统一,如果要蒸馏softmax之前的attention logits可以采用MSE,之后的attention prob可以用KL散度。
T和 如何设置?
超参数 主要控制soft label和hard label的loss比例,Distilled BiLSTM在实验中发现只使用soft label会得到最好的效果。个人建议让soft label占比更多一些,一方面是强迫学生更多的教师知识,另一方面实验证实soft target可以起到正则化的作用,让学生模型更稳定地收敛。
超参数T主要控制预测分布的平滑程度,TinyBERT实验发现T=1更好,BERT-PKD的搜索空间则是{5, 10, 20}。因此建议在1~20之间多尝试几次,T越大越能学到teacher模型的泛化信息。比如MNIST在对2的手写图片分类时,可能给2分配0.9的置信度,3是1e-6,7是1e-9,从这个分布可以看出2和3有一定的相似度,这种时候可以调大T,让概率分布更平滑,展示teacher更多的泛化能力。
需要逐层蒸馏吗?
如果不是特别追求零点几个点的提升,建议无脑一次性蒸馏,从MobileBERT来看这个操作性价比太低了。
蒸馏代码实战
目前Pytorch版本的模型蒸馏有一个非常赞的开源工具TextBrewer[8],在它的src/textbrewer/losses.py文件下可以看到各种loss的实现。
最后输出层的CE/KL/MSE loss比较简单,只需要将两者的logits除temperature之后正常计算就可以了,以CE为例:
def kd_ce_loss(logits_S, logits_T, temperature=1):
'''
Calculate the cross entropy between logits_S and logits_T
:param logits_S: Tensor of shape (batch_size, length, num_labels) or (batch_size, num_labels)
:param logits_T: Tensor of shape (batch_size, length, num_labels) or (batch_size, num_labels)
:param temperature: A float or a tensor of shape (batch_size, length) or (batch_size,)
'''
if isinstance(temperature, torch.Tensor) and temperature.dim() > 0:
temperature = temperature.unsqueeze(-1)
beta_logits_T = logits_T / temperature
beta_logits_S = logits_S / temperature
p_T = F.softmax(beta_logits_T, dim=-1)
loss = -(p_T * F.log_softmax(beta_logits_S, dim=-1)).sum(dim=-1).mean()
return loss
对于hidden MSE的蒸馏loss,则需要去除被mask的部分,另外如果维度不一致,需要额外加一个线性变换,TextBrewer默认输入维度是一致的:
def hid_mse_loss(state_S, state_T, mask=None):
'''
* Calculates the mse loss between `state_S` and `state_T`, which are the hidden state of the models.
* If the `inputs_mask` is given, masks the positions where ``input_mask==0``.
* If the hidden sizes of student and teacher are different, 'proj' option is required in `inetermediate_matches` to match the dimensions.
:param torch.Tensor state_S: tensor of shape (*batch_size*, *length*, *hidden_size*)
:param torch.Tensor state_T: tensor of shape (*batch_size*, *length*, *hidden_size*)
:param torch.Tensor mask: tensor of shape (*batch_size*, *length*)
'''
if mask is None:
loss = F.mse_loss(state_S, state_T)
else:
mask = mask.to(state_S)
valid_count = mask.sum() * state_S.size(-1)
loss = (F.mse_loss(state_S, state_T, reduction='none') * mask.unsqueeze(-1)).sum() / valid_count
return loss
蒸馏attention矩阵则也要考虑mask,但注意这里要处理的维度是N*N:
def att_mse_loss(attention_S, attention_T, mask=None):
'''
* Calculates the mse loss between `attention_S` and `attention_T`.
* If the `inputs_mask` is given, masks the positions where ``input_mask==0``.
:param torch.Tensor logits_S: tensor of shape (*batch_size*, *num_heads*, *length*, *length*)
:param torch.Tensor logits_T: tensor of shape (*batch_size*, *num_heads*, *length*, *length*)
:param torch.Tensor mask: tensor of shape (*batch_size*, *length*)
'''
if mask is None:
attention_S_select = torch.where(attention_S <= -1e-3, torch.zeros_like(attention_S), attention_S)
attention_T_select = torch.where(attention_T <= -1e-3, torch.zeros_like(attention_T), attention_T)
loss = F.mse_loss(attention_S_select, attention_T_select)
else:
mask = mask.to(attention_S).unsqueeze(1).expand(-1, attention_S.size(1), -1) # (bs, num_of_heads, len)
valid_count = torch.pow(mask.sum(dim=2),2).sum()
loss = (F.mse_loss(attention_S, attention_T, reduction='none') * mask.unsqueeze(-1) * mask.unsqueeze(2)).sum() / valid_count
return loss
最后是只在DistillBERT中出现的cosine loss,可以直接使用pytorch的默认接口:
def cos_loss(state_S, state_T, mask=None):
'''
* Computes the cosine similarity loss between the inputs. This is the loss used in DistilBERT, see `DistilBERT <https://arxiv.org/abs/1910.01108>`_
* If the `inputs_mask` is given, masks the positions where ``input_mask==0``.
* If the hidden sizes of student and teacher are different, 'proj' option is required in `inetermediate_matches` to match the dimensions.
:param torch.Tensor state_S: tensor of shape (*batch_size*, *length*, *hidden_size*)
:param torch.Tensor state_T: tensor of shape (*batch_size*, *length*, *hidden_size*)
:param torch.Tensor mask: tensor of shape (*batch_size*, *length*)
'''
if mask is None:
state_S = state_S.view(-1,state_S.size(-1))
state_T = state_T.view(-1,state_T.size(-1))
else:
mask = mask.to(state_S).unsqueeze(-1).expand_as(state_S).to(mask_dtype) #(bs,len,dim)
state_S = torch.masked_select(state_S, mask).view(-1, mask.size(-1)) #(bs * select, dim)
state_T = torch.masked_select(state_T, mask).view(-1, mask.size(-1)) # (bs * select, dim)
target = state_S.new(state_S.size(0)).fill_(1)
loss = F.cosine_embedding_loss(state_S, state_T, target, reduction='mean')
return loss
关于更多的蒸馏实战经验,可以参考知乎@邱震宇同学的模型蒸馏技巧小结[9]。
总结
短暂的学习就要结束了,蒸馏虽然费劲,但确实是目前小模型提升效果的主要方法之一,在很多研究中都有用到。另外,模型蒸馏有一个好处是可以利用大批量的无监督数据,只要能找到任务相关的,就可以蒸馏提升模型的泛化能力。标注数据少的同学还等什么?快去试试叭!
参考资料
Distilling the Knowledge in a Neural Network: https://arxiv.org/abs/1503.02531
[2]Distilling Task-Specific Knowledge from BERT into Simple Neural Networks: https://arxiv.org/abs/1903.12136
[3]Patient Knowledge Distillation for BERT Model Compression: https://arxiv.org/abs/1908.09355
[4]DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter: https://arxiv.org/abs/1910.01108
[5]TinyBERT: Distilling BERT for Natural Language Understanding: https://arxiv.org/abs/1909.10351
[6]MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices: https://arxiv.org/abs/2004.02984
[7]MINILM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers: https://arxiv.org/abs/2002.10957
[8]TextBrewer: https://github.com/airaria/TextBrewer
[9]模型压缩实践收尾篇——模型蒸馏以及其他一些技巧实践小结: https://zhuanlan.zhihu.com/p/124215760
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套!
![]()
![]()
![]()
后台回复【五件套】
下载二:南大模式识别PPT
![]()
后台回复【南大模式识别】




由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!




