案例分享 | 前端代码是怎样智能生成的 - 字段绑定篇
文 / 笑翟 阿里巴巴
原文:https://juejin.im/post/5e4a86c5e51d4526d43f2b3b

概述
imgcook 是专注以各种图像(Sketch / PSD / 静态图片)为原材料烹饪的匠心大厨,通过智能化手段将各种视觉稿一键生成可维护的前端代码,含视图代码、数据字段绑定、组件代码、部分业务逻辑代码。
智能字段绑定是其中一部分,实现准确识别营销以及其他垂直业务视觉稿的可绑定数据字段,大幅提升模块研发效率,从而强化视觉稿还原结果,其拆分为数据类型规则、是否静态文案、图片绑定和文本字段绑定几个部分。
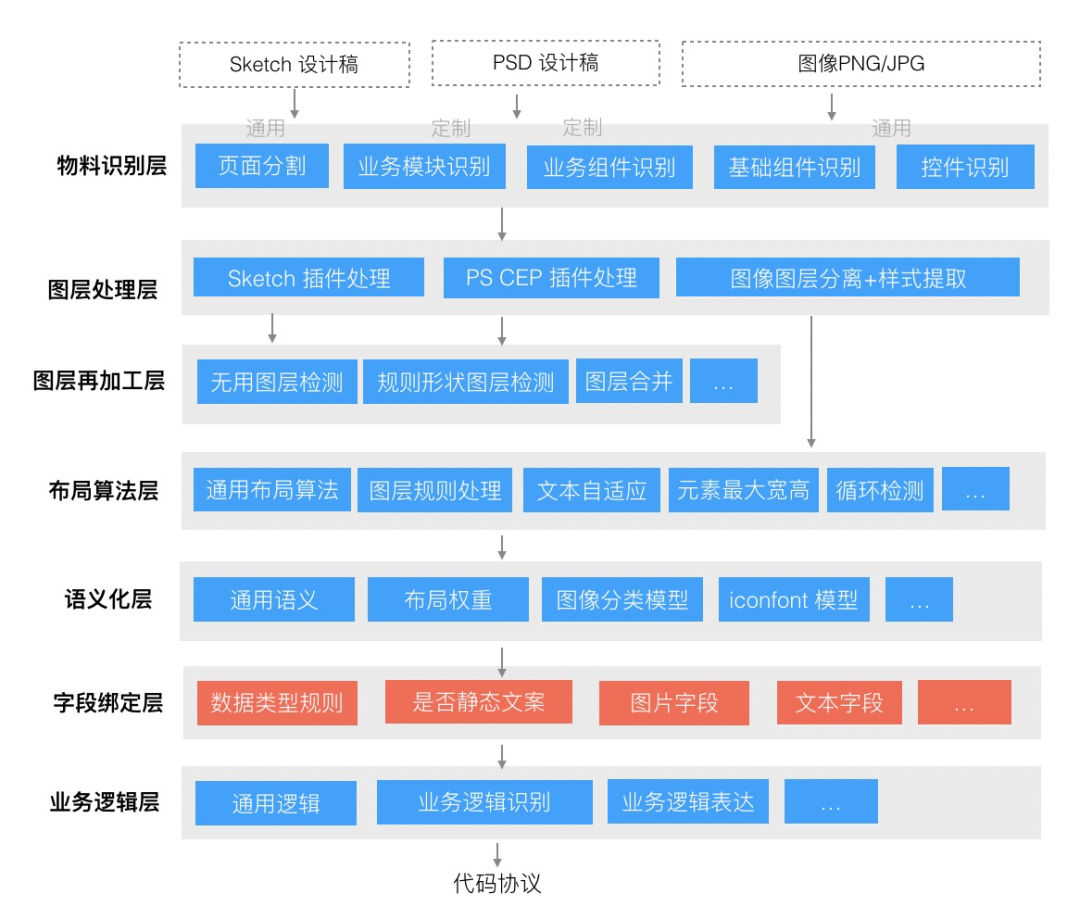
在 imgcook 大图位置
如图所示,服务位于字段绑定层,包括数据类型规则、是否静态文案、图片字段,文本字段等部分。
预研
-
语义与字段绑定联系过深 -
问题:导致的问题语义与字段绑定结果关联过紧,灵活度不够 优化:语义与字段绑定 的判定流程分离,移除置信度概念
-
语义层规则层过硬 -
问题:现有规则层过硬,以判断为主 优化:硬规则使用分类算法,统一定性对标到w3c的节点标准上
-
语义层机器学习算法使用程度不足 -
问题:仅使用了实体识别、句法分析和翻译 优化:图像分类使用深度模型,文字分类使用传统机器学习
-
业务域字段频繁变更 -
问题:映射的字段不同业务域下不同 优化:提供不同配置自身智能绑定映射关系的能力
-
硬规则层扩展 -
问题:现有规则不够多 优化:根据设计稿,提炼新的规则,扩充规则层
技术方案
字段绑定主要通过文本 NLP 识别和图片分类识别 vdom 中内容来决策映射到数据模型中的字段从而实现智能绑定字段,整体流程入下图:
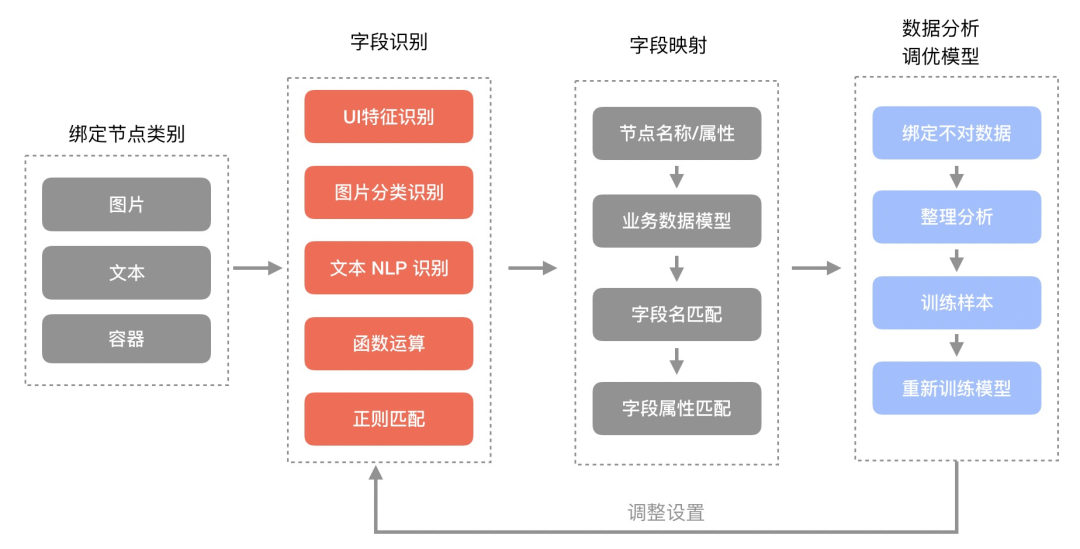
字段绑定核心流程图
在字段绑定中主要核心是文本 NLP 识别和图片分类模型,下面着重介绍下。
文本 NLP 识别
调研
淘系设计稿文字所有动态部分分类分析:
业务域下常见的字段和设计稿文字的关系,下面举几个例子。
1. 商品名称/标题(itemTitle)
-
设计稿文字:产品产品名称最多十二个字、产品名称十二个字、商品名超过十个字显示 真实意图文字:Nike AF1 JESTER XX、海蓝之谜睡眠面膜保湿补水神器饱满焕发、Galanz/格兰仕G80F23CN3XL、德国双立人Specials30cm中立炒锅套装、SOPOR/苏泊尔CFXB40FC8028
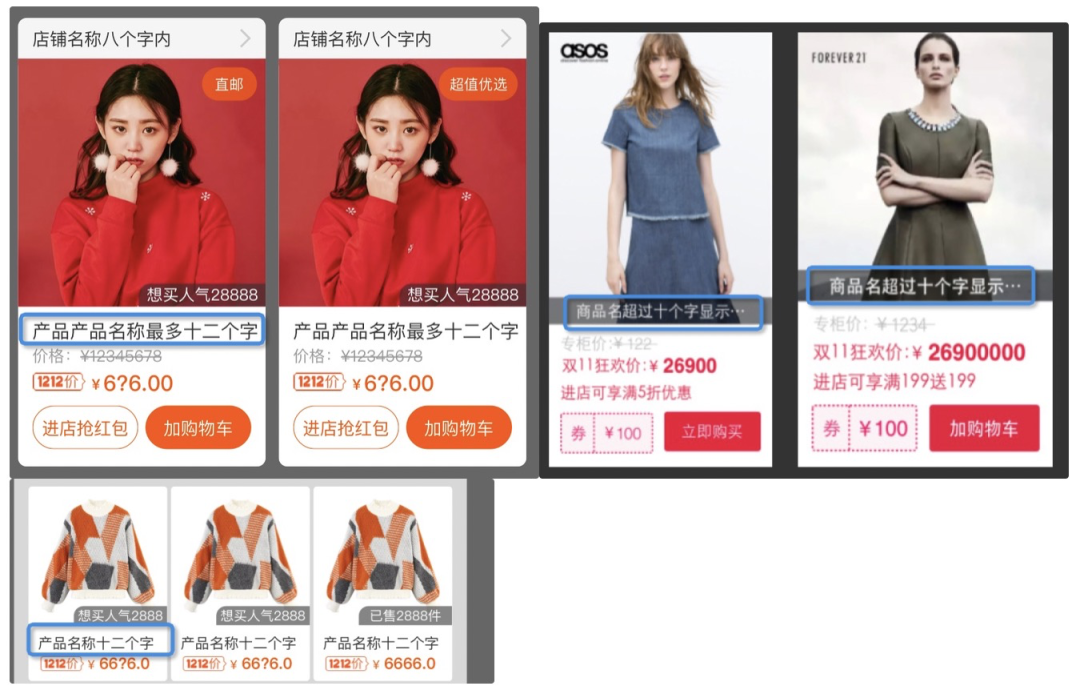

商品名称/标题设计稿
2. 店铺名称 (shopName)
-
设计稿文字:店铺名最多八个字、店铺名称店铺、店铺名可以八个字、店铺名称店铺名称最多放十五个字 真实意图文字:优衣库体验舒适人生、NIKE 海淘精品、匡威官方旗舰店、ZARA 服饰旗舰店、Mays 官方海外旗舰店

店铺名称设计稿
3. 店铺利益点 (shopDesc)
-
设计稿文字:店铺利益点八字内、利益点超过十个字显示、利益点仅七个字、利益点可以两条利益点文案最多十个字 真实意图文字:满199返199、进店可享满5折优惠、进店可享满199送199、冬新品第二件满减包邮、全场满1999送199

店铺利益点设计稿
技术选型
1. 朴素贝叶斯
我们在字段绑定中进行 NLP 识别的一个问题是样本量不够。尤其我们依赖于租户上传自己的样本对他们特定的业务进行训练,往往租户并没有特别大量的数据,在这种情况下,我们考虑选择朴素本叶斯分类器来进行分类,原因是朴素贝叶斯公式源于古典数学,其对于后验概率的得出源于先验概率和调整因子,并不依赖于数据量,对小数据和噪声点非常健壮。核心算法是这个贝叶斯公式:
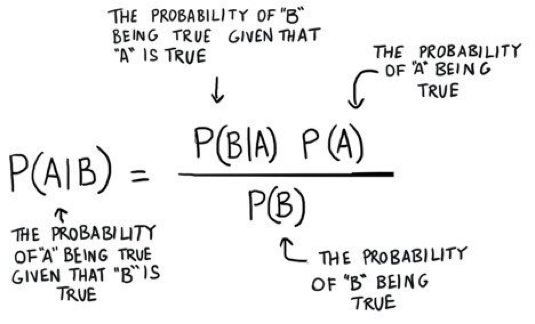
换个形式表达就清楚多了,如下:

最终求 P(类别 | 特征)即可。
2. 分词
对于每条样本,我们在分类前需要首先进行特征点提取,在这个问题中也就是对样本进行分词,在机器学习平台中默认使用了 AliWS 来进行分词,AliWS(Alibaba Word Segmenter 的简称)是服务于整个阿里巴巴集团的词法分析系统。被广泛应用于集团的各项业务中。AliWS 的主要主要功能包括:歧义切分,多粒度切分,命名实体识别,词性标注,语义标注,支持用户自己维护用户词典,支持用户干预或纠正分词错误。其中,在我们的项目中,命名实体识别包括:简单实体,电话号码,时间, 日期等。
模型搭建
我们主要是使用了机器学习平台的能力进行了快速模型链路的搭建,机器学习平台对于 ALiWS 的分词算法和朴素贝叶斯多分类进行了很好的组件封装,下图是我们的模型搭建

文本 NLP 模型训练链路
从上图看第一步会执行 SQL 脚本从数据库拉取训练样本,然后对样本进行分词操作处理。之后会按找一定比例将样本拆分为训练集和测试集,对于训练集的样本,进行朴素贝叶斯分类器,对于测试集,则是拿到分类器的结果进行预测和评估,最后会把模型结果通过 odps cmd 指令上传存储到 oss。
图片分类模型
调研
-
标: label 为矩形小图,背景纯色,上有白色短文字点名心智 -
icon: icon 大概率圆形。通常是抽象化的符号 -
头像: avator 通常圆形,中心为人物面部 -
店铺 logo: logo 通常用于突出性展示一个概念,文字或抽象化的图片作为主体 -
场景图: picture 最常见的商品图,内容较多,主体通常不为一个。突出商品或人物在真实环境中的表现 -
白底图: purePicture 主体单一,背景纯白。突出主体自身 -
氛围图: pureBackground 有明显色系,形状构成的背景图 高斯模糊:blurBackground 高斯模糊效果的背景图
在之前的模式下,我们主要是根据图片大小和图片位置等相关信息通过一些规则来进行图片识别。但这种模式下的识别存在不准和不灵活的问题,比如不同业务下可能 icon 的大小不尽相同,以及位置等信息存在极大的不确定性,同时由于基于这些类别进行分析,发现图片本身的内容已经足够区分开来,所以我们考虑使用深度学习模型进行图片分类识别。
技术选型
1. CNN 网络
图片分类问题,我们首选是当前图像处理最热门的 CNN 网络,卷积神经网络的想法来源于人类的视觉原理,而这种通过卷积核分析图片相较于传统的神经网络极大的降低了待训练参数数量。同时,相较于传统的机器学习模型,CNN 在特征提取上表现出了极高的优势。
简单介绍下 CNN 网络如何实现的,在介绍卷积神经网络前,我们先看看人类的视觉原理:
人类的视觉原理
深度学习的许多研究成果,离不开对大脑认知原理的研究,尤其是视觉原理的研究。
1981 年的诺贝尔医学奖,颁发给了 David Hubel(出生于加拿大的美国神经生物学家) 和TorstenWiesel,以及 Roger Sperry。前两位的主要贡献,是“发现了视觉系统的信息处理”,可视皮层是分级的。
人类的视觉原理如下:

人类的视觉原理
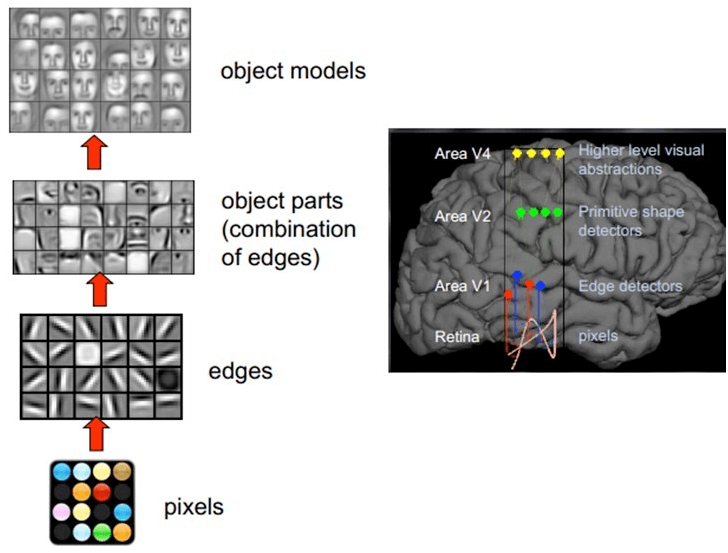
人脑进行人脸识别示例,图片来自网络
对于不同的物体,人类视觉也是通过这样逐层分级,来进行认知的:

人类视觉对不同物体逐层分级,图片来自网络
我们可以看到,在最底层特征基本上是类似的,就是各种边缘,越往上,越能提取出此类物体的一些特征(轮子、眼睛、躯干等),到最上层,不同的高级特征最终组合成相应的图像,从而能够让人类准确的区分不同的物体。
那么我们可以很自然的想到:可不可以模仿人类大脑的这个特点,构造多层的神经网络,较低层的识别初级的图像特征,若干底层特征组成更上一层特征,最终通过多个层级的组合,最终在顶层做出分类呢?答案是肯定的,这也是许多深度学习算法(包括CNN)的灵感来源。
卷积神经网络(CNN)的基本原理
卷积神经网络包括输入层、隐含层、输出层,其中隐含层包括卷积层、池化层和全连接层3类常见构筑,这3类分别负责的分工是卷积层对输入数据进行特征提取,池化层用来大幅降低参数量级(降维、防止过拟合),全连接层类似传统神经网络的部分,用来输出想要的结果。

CNN的基本原理
2. 迁移学习
由于我们的图片数据主要来自于内部网络,同时受制于计算资源的问题,我们需要选择一种训练方式来尽可能的适应数据量少和计算资源少的问题,于是我们考虑使用迁移训练。迁移训练是一种基于其他已经训练好的模型进行再训练的技术,基于诸如 ImageNet 等数据集经过大量运算训练出的如 VGG,Resnet 或 MobileNet 等模型本身已经具备了很好的提取图像特征和输出信息的能力,这就好比站在前人的基础上做事情,只需要再这基础上让模型适应我们的数据就好,这会大大节省训练的成本。
3. ResNet
在我们的项目中,我们考虑在使用 Resnet 的基础上来进行迁移学习。ResNet 最根本的动机就是所谓的“退化”问题,即当模型的层次加深时,错误率却提高了,这是由于深度加深导致的优化变的苦难的问题,残差网络通过短路连接,在网络向后传播梯度的时候,永远不会出现梯度消失的情况,很好的解决了网络过深带来的问题。
4. TensorFlow 和 机器学习平台
机器学习平台,为传统机器学习和深度学习提供了从数据处理、模型训练、服务部署到预测的一站式服务。机器学习平台底层支持 TensorFlow 框架,同时支持 CPU/GPU 混合调度和高效的资源复用,我们将借机器学习平台的计算能力和 GPU 资源进行训练,同时将 inference 模型部署至 机器学习平台的在线预测服务 EAS。
模型搭建
数据清洗:通过 odps 的大促表爬取了每个类别约 1000 张图片,但是其中很多图片由于是商家上传的,可能会有无效数据,丢失数据甚至是错误数据,比如我们在处理这些图片的时候发现很多白底图和商品图是混淆的,我们将会对这些数据首先进行一轮清理。
人工样本:在常见类别中,我们发现诸如氛围图这类很难爬取到很多,同时这类样本具有明显的特征,于是我们将根据这种特征进行样本制造。我们使用了 node-canvas 人工制作了约 1000 张样本,同时,高斯模糊这一类别实际上往往就是一些商品图进行模糊之后的效果,所以我们对爬取到的商品图使用 opencv 进行高斯模糊,得到样本。
数据增强:由于我们场景的特殊性,我们不能采用一些传统的数据增强的方式,比如高斯模糊(因为我们有一类就是高斯模糊),但是我们进行了一些简单的诸如位移和轻微旋转等数据增强方式。
TFRecord 转化:TFRecord 是 TensorFlow 官方设计并推荐的一种数据存储格式,每个 TFRecord 内部存储了多个 TF Example,可可以想象每个 TFExmaple 就是对应一组数据 (X,y),TFExample 其实是一种 谷歌官方开发的数据框架序列化格式,类似于Javascript 序列化输出的 JSON 或者 Python 序列化输出的 Pickle 等格式,但是 protobuf 体积更小,数据更快,效率更高,从 TensorFlow 源码中也可以随处可见这种数据格式。以下从我们代码中截取的片段是针对一组数据创建 TFExample 。
其中我们制定了三个 Feature 我们之后再训练中将会用到的,image/encoded 就是图片的 bytes 流,label 是分类的类别,image/format 是图片类型,将会在之后 slim.tfexample_decoder.Image 函数解析 TFRecord 中使用。
1. 模型构建
迁移训练模型建立
TF-slim 是 TensorFlow 轻量级的高阶 API,可以很方便的定义,训练和评估模型。TF-slim 官方提供了很多知名的CNN 网络的预训练模型。用户可以通过官方 Github 进行模型参数的下载,同时调用 tensorFlow.contrib.slim.net 中的方法加载模型结构,以下是我们定义的 predict 函数,此函数将在训练时和预测时提供定义流图中经过模型的部分。注意预训练模型只提供了卷积层的实现,为符合我们的分类问题,我们还需要把输出的卷积结果压平,同时加一层全链接层加 softmax 函数进行预测。
2. 模型训练
我们通过 slim 提供的 assign_from_checkpoint_fn 函数加载下载的 mobileNet 预训练模型的参数,使用之前定义的数据流图进行训练,同时在训练的过程中输出 checkPoint 和 相关 Log
3. 模型预测
-
.meta 文件:保存了模型的数据图 -
.ckpt.data 文件:保存了模型变量的信息,包含 weights,bias 等信息 -
.ckpt.index:描述了张量的 key 和 value 的对应信息 .checkpoint:保存的模型和模型的相关信息
实际上可以看到模型保存时会生成相当多的信息,而其中的很多信息其实在使用模型进行预测时并不是必须的,那么我们就需要对导出的记录信息进行优化,实现高性能的预测。
首先,我们将对保存的模型进行冻结,TensorFlow 模型冻结是指把计算图的定义和模型权重合并到同一个文件中,并且只保留计算图中预测需要的部分,而不再需要训练相关的部分,下面我们的代码片段就是将计算图中所有的变量转化为常量。
产品方案
我们考虑到不同业务的数据模型和智能识别及绑定的字段不一样,因此实现了一套可以在线新增分类并配置样本,在线训练模型生成服务,然后通过配置方式使用。
流程图
产品流程图
还原模块自动绑定效果
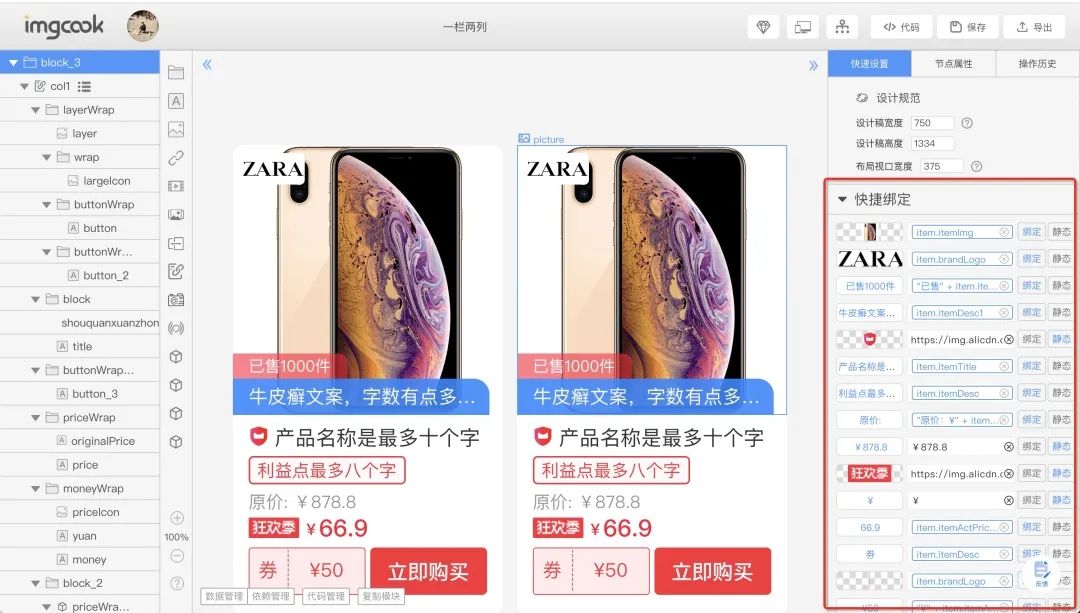
字段绑定效果
未来展望
-
对不同场景静态文案分析,我们分析影响绑定准确率的一个部分原因是不同设计和模块里的静态文案多样性,导致的识别出符合预期的结果,后面我们会着重针对不同业务场景静态文案梳理,识别前对静态文案过滤,同时完善通用配置及识别能力。
-
对 NLP 识别和图片分类识别模型优化,对识别绑定不准的数据进行反馈召回,再对反馈召回的数据分析重新优化识别模块和链路,最终提高绑定准确率。 字段标准化推进。
更多推荐
imgcook 官网
https://www.imgcook.com/ 体验一键智能生成代码imgcook 知乎专栏
https://zhuanlan.zhihu.com/imgcook 为你带来前端智能化前沿资讯imgcook 掘金专栏
https://juejin.im/user/5e1401a06fb9a0481831192d 设计稿智能生成代码
** 欢迎加入我们:
[社招/校招] [杭州] [阿里淘系技术部-频道与 D2C 智能] 前端招聘 (https://juejin.im/post/5e44f08bf265da572a0cee7e)



加入案例分享,请点击 “阅读原文” 填写您的用例与相关信息,我们会尽快与你联系。