兼顾公平与效率?北大NeurIPS 19论文提出多智能体强化学习方法FEN
机器之心报道
机器之心编辑部
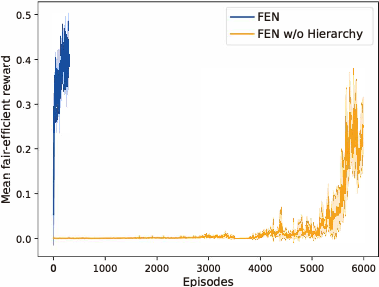
近日,北京大学卢宗青团队提出了一种新的多智能体强化学习方法 Fair-Efficient Network(FEN,「分」),用于多个智能体学习提升系统效率并同时保持公平。这一新方法对任务调度、马太效应和工厂生产等实际情景具有重要意义,该论文已被人工智能顶会 NeurIPS 2019 录用。
提出 fair-efficient reward,用于学习效率与公平。
提出一种 hierarchy 架构,降低学习难度。
提出 FEN 的分布式训练方法。

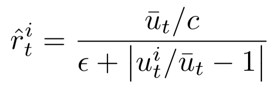
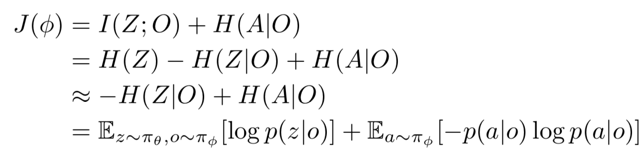
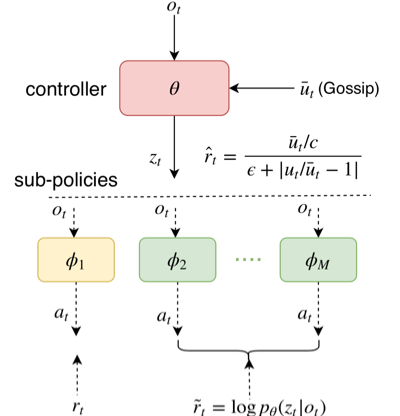

Job Scheduling 环境中存在 4 个智能体和 1 个资源,智能体占据资源会获得奖励,资源在同一时刻只能被一个智能体占据。
The Matthew Effect 环境中存在 10 个 Pac-men 和若干 ghosts。Pac-man 吃掉 ghost 会获得奖励,并且体积和速度变大,更容易吃其他 ghost,因此强者越强。
Manufacturing Plant 环境中存在 5 个智能体和不同种类的矿石,每个智能体采集不同的矿石来生产不同的零件,最终的产量取决于数目最少的零件。

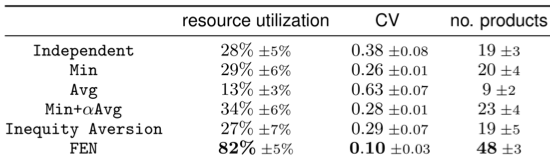
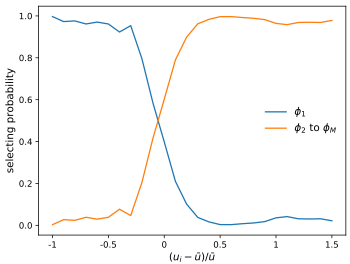
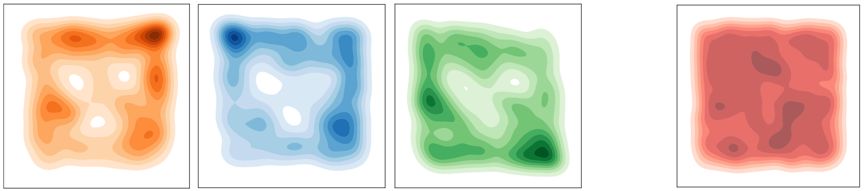
Sub-policies 能够远离三个 ghosts 来保持公平。
三个 sub-policies 分布互不相同,达到了信息论目标的预期。
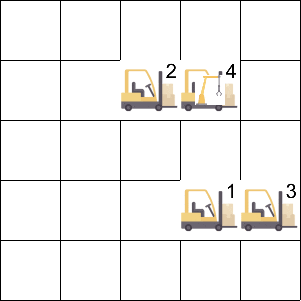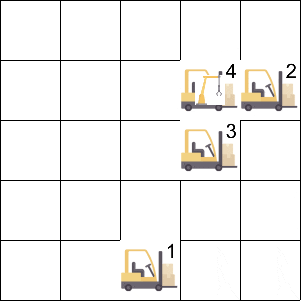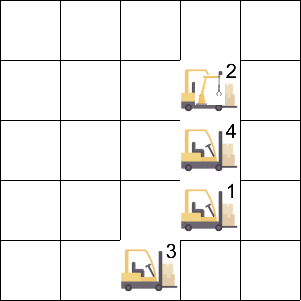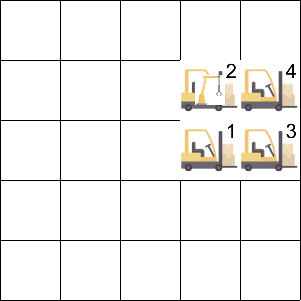
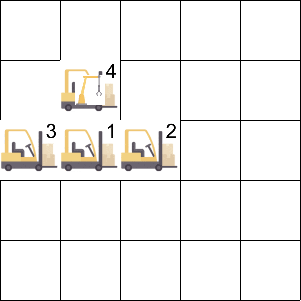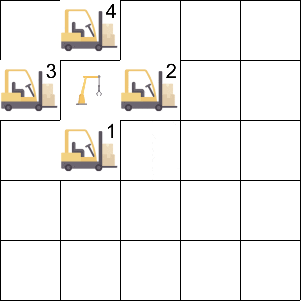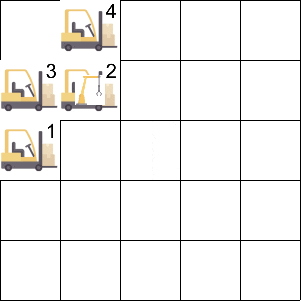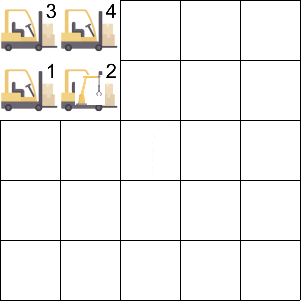
登录查看更多
相关内容
Arxiv
8+阅读 · 2020年4月13日




相关VIP内容
相关资讯
相关论文
Arxiv
8+阅读 · 2020年4月13日