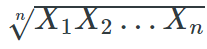本文约6771字,建议阅读10分钟
本文介绍了NLP 基准测试所面临的挑战、机遇和一些改进的建议。
![]()
在过去几年的改进下,NLP 模型的能力越来越强大。性能大幅提升导致之前的基准测试已经无法满足当下的需求。如AI Index Report 2021所言,最近的模型在SuperGLUE和SQuAD等测试的基准上面达到了超越人类的表现。
这是否说明,我们已经掌握了处理自然语言的方法呢?答案是没有。
现在的模型具备强大的语言理解能力,我们很难再用准确率、BLEU 这种单一指标和静态基准、抽象任务公式的传统做法评估 NLP 模型。所以,我们需要设计新的基准来评估模型,并且让它在今后发挥作用。
这篇文章的主要内容是:
NLP 基准测试所面临的挑战、机遇和一些改进的建议
。我们希望这篇文章可以让读者了解这方面科研的最新进展,也要让初学者全面了解NLP。文中还涉及到最近的论文、ACL 2021 演讲以及ACL 2021 基准测试研讨会的观点,其中许多观点涉及到了过去、现在和未来。
基准起初被定义为测量员在水泥结构中帮助水平尺测量数据的水平标记。后来基准的定义渐渐变成
对比事物的标准参考点
。形象地说,基准是一个可以相互比较的标准参考点。基准在ML或NLP中通常由以下几个部分组成:一个或多个数据集、一个或多个相关指标以及聚合性能的方法。
我们为基准设置了一个评估社区商定系统的标准,确保基准被社区接受。具体操作是要么给基准选择一组有代表性的标准任务,如GLUE或XTREME;要么积极征求社区的任务提案,比如SuperGLUE、GEM或BIG-Bench等等。
对于该领域的人来说,基准是跟进事件发展的重要工具,阿拉温德·乔希说:
没有基准评估我们的模型,我们就像“不造望远镜的天文学家想看星星”。
对于领域外的人来说,基准为他们提供了客观的视角,帮助他们认识了有用的模型,还为他们提供了跟踪一个领域进展的服务。例如,《2021年人工智能指数报告》使用SuperGLUE和SQuAD作为自然语言处理总体进展的代理。
有些基准在使用的过程中达到了和人类近似的表现,它们被记入这一领域发展的历史中。例如 AlphaFold 2在CASP 14竞赛中达到与实验方法竞争的性能就标志着结构生物学领域的重大科学进步。
"
创建好的基准比大多数人想象的要难
。"-约翰·马西;系统基准(2020)前言
基准很久之前就被用来测量计算机性能了。1988年成立的基准性能评估公司(SPEC)是最老的计算机硬件性能基准测试的组织之一。每年SPEC都会发布不同的基准集,每个基准集由多个程序组成,性能以每秒数百万指令的几何平均值来衡量。值得一提的是,SPEC 得到了该领域很多重要公司的支持。
最近一个名为MLCommons的公司组织了一场MLPerf系列绩效的基准测试。测试重点是模型训练和推理。与SPEC相似,MLPerf得到了学术界和工业界的广泛支持,这项基准测试建立在以前衡量绩效的个人努力的基础上,如百度的DeepBench或斯坦福的DAWNBench。
对于DARPA和NIST等美国机构来说,基准在衡量和跟踪科学前沿方面发挥了至关重要的作用
。早在1986年DARPA 就资助了,TIMIT和Switchboard等自动语音识别的基准,并由NIST协调。后来在MNIST等ML其他领域有影响力的基准也是依赖 NIST上的数据开始改进。
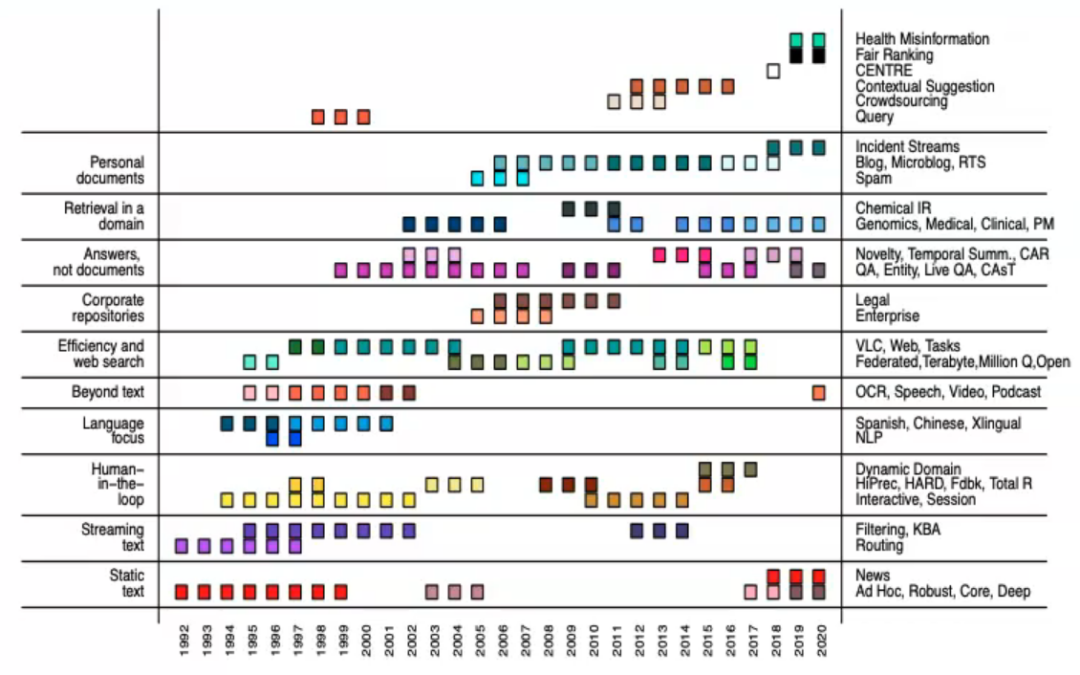
在语言技术和信息检索(IR)方面,NIST举办了DARPA资助TREC的系列研讨会,会议内容涵盖面很广,如下图所示。TREC曾经组织了20世纪60年代克兰菲尔德开创的评估范式竞赛,在该范式中,模型基于一组测试集合进行评估。由于不同主题的表现差异很大,许多主题的得分都是平均的。所以TREC的标准广泛可用。TREC精心构建的数据集也在IR奠定了进一步创新的基础。
1992-2020年TREC研讨会的任务和主题(信贷:艾伦·沃里斯)
近期基准的规模都很大,比如ImageNet、SQuAD或SNLI等。它们是由资金雄厚的大学学术团体开发的。在深度学习时代,大规模数据集被认为是推动科技进步的支柱之一,自然语言处理或生物学等领域见证了它们的“ImageNet时刻”。
随着时间的变化,越来越多的基准开始面向应用,它们
从单任务转向多任务,从单域转向多域基准
。例如,从关注核心语言任务(如词性标注和依赖解析)向更接近现实世界的任务(如面向目标的对话和开放域问题回答)转变(Kwiatkowski et al.,2019);多任务数据集(如GLUE)的出现以及多模态数据集(如WILDS)的出现。
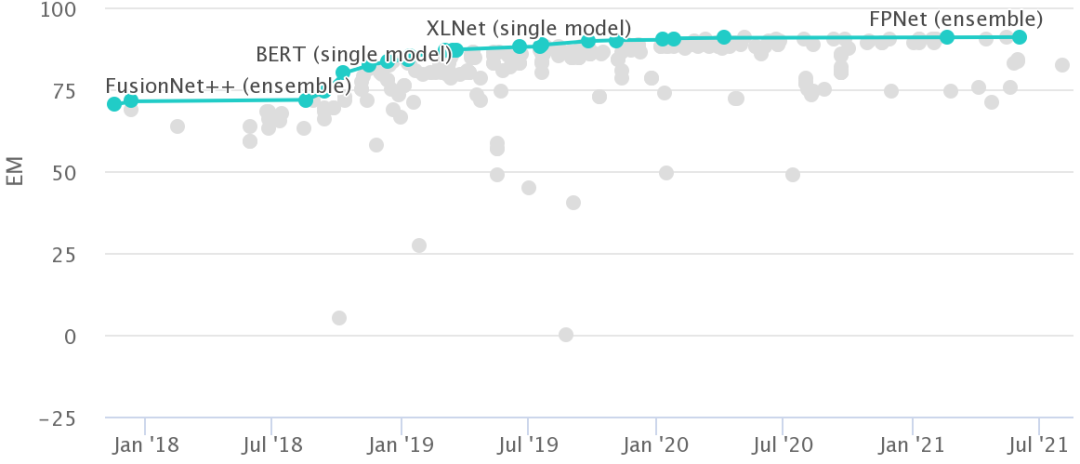
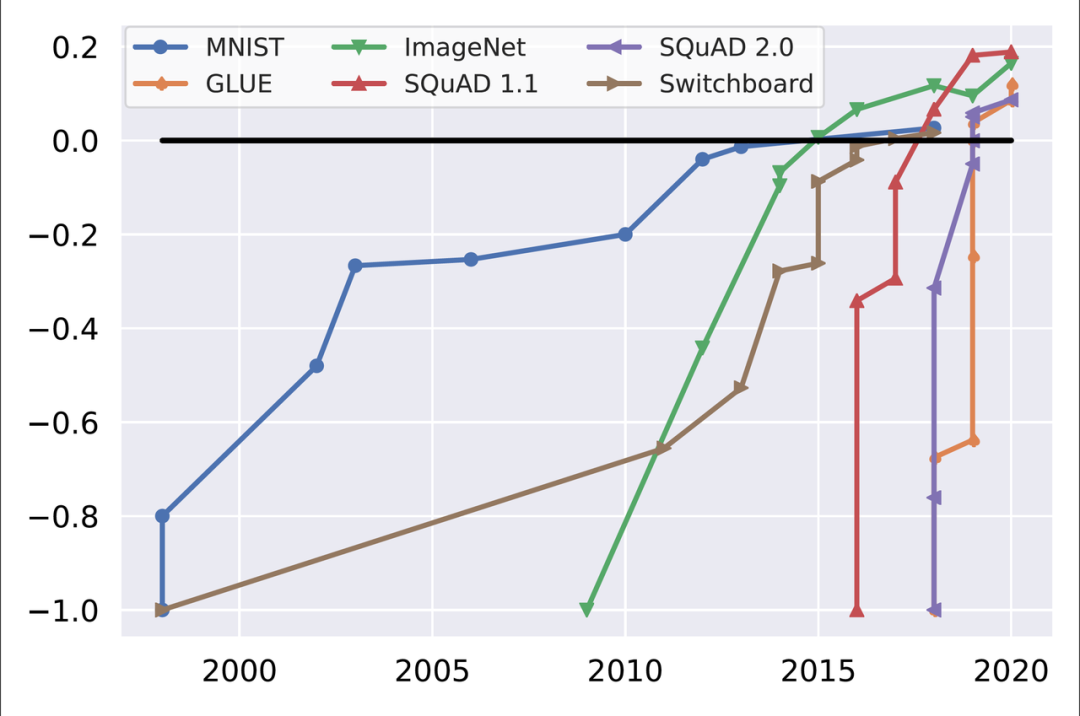
如下图所示, MNIST和 Switchboard等经典基准,实现超人性能花了15年。而GLUE和SQuAD 2.0等基准在模型发布一年后就能实现超人性能,但是我们也知道这只是基准的测试能力,它们的实际处理能力连一般问答都没办法解决。
随着时间的推移,流行基准的基准饱和度。初始性能和人类性能分别正常化为-1和0(Kiela et al.,2021)
导致基准容易饱和的另一个原因是,相比于早期,近期的数据集中的人工注释痕会被模型快速学习并用于捷径识别
。我们在SNLI中得出,人工注释依赖于启发式,这样模型就可以在不同情况下基于假设自动预测出正确的结果,同时在 SQuAD上训练的模型会受到对抗性插入语句的影响。
如今,行业的发展趋势是对抗性数据集的崛起。这些数据集如对抗性NLI(Nie et al.,2020)、Beat the AI(Bartolo et al.,2020)等等。Dynabench 就是一个最近被设计出来促进这类数据集发展的开源平台。这类基准的好处是,随着新模型的出现,可以不断自我更新,从而使基准不会太快饱和。
“当你能衡量你在说什么并用数字表达时,你就知道你在讨论什么。但是当你不能衡量它并用数字表达时,你的知识是非常贫乏和令人不满的。”-开尔文勋爵
指标在衡量模型效果中很重要,但是它没有受到应有的重视。
对于分类任务,准确率和F-1分数等一般都是默认使用的指标,但实际上对于不同的任务,不同类型的错误会产生不同的成本。
比如对细粒度的情绪进行分析,搞不清积极和很积极可能没有问题,但是搞不清非常积极和非常消极问题就大了。Chris Potts还列举了很多这种例子,其中包括指标不足造成更大错误的情况。
想要设计好一个指标,就需要专业的领域知识。比如ASR(语音识别),最初只使用正确转录单词的百分比(类似于准确率)作为指标。后来社区使用了词错率( word error rate),因为它可以反映出纠错成本。
Mark Liberman曾表示:“
研究设计可用几十年的指标,与为实际应用短期发展设计的指标之间,存在很大的差异。若要开发能用十年的技术,我们就需要更高效的指标,哪怕细节上错点都行,但是大方向不能错
。”
Mark Liberman想要的指标是像ASR中的词错率(假设所有单词都同等重要)和机器翻译中的BLEU(假设词序不重要)一类的指标。
但是对于实际技术的评估,我们需要根据特定的应用要求设计度量标准,并研究不同类型的错误。
近年来,随着模型性能的迅速提高,我们从十年的长期应用机制转向许多短期的应用机制。有意思的是,在这样的环境下,我们仍然在大范围使用衡量长期研究进展的指标。Marie等人(2021)在最近的一项报告分析中发现,2019-2020年间82%的机器翻译(MT)论文仅使用BLEU进行评估,虽然在过去十年中人们为MT评估提出了108个替代指标,其中许多指标与人类判断相差不大。但是随着模型的变大,BLEU很难再成为表现最佳的模型了。
虽然自然语言生成 (NLG) 模型的评估是出了名的困难,但标准的基于 n-gram 重叠的指标(例如 ROUGE 或 BLEU)不太适合具有丰富词法的语言,使得这些语言将被分配相对较低的分数。
NLG最近的发展趋势是开发自动度量,比如 BERTScore会利用大型预训练模型(Zhang et al.,2020)。这种方法使其
更适合短期MT评估,具体操作是将更大的权重分配给更困难的token,即少数MT系统才能正确翻译的token
。
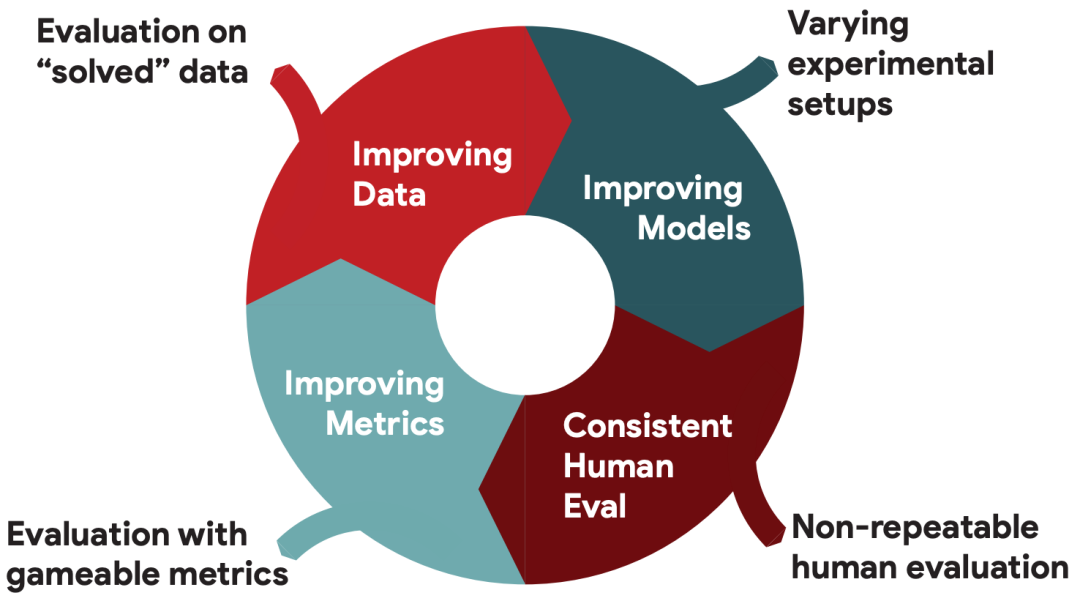
因此,我们需要不断更新完善度量标准,用特定应用的度量标准替代简单的度量标准,例如,最近的GEM基准将度量指标作为一个组件,其需要随着时间的推移而不断改进,如下图所示。
Opportunities (circle) and challenges of benchmark evaluation (Gehrmann et al., 2021).
-
-
-
“[...]基准塑造了一个领域,无论是好是坏。好的基准与实际应用一致,但坏的基准却不一致,迫使工程师在帮助最终用户的改变和只帮助营销的改变之间做出选择。”-大卫·帕特森;系统基准(2020)前言
NLP技术在现实世界里的应用越来越广泛,从创造性的个性化语言表达到欺诈检测都可以看到NLP的身影。我觉得我们该要重视它在现实世界里的应用机制了。
所以基准测试的数据和评估协议应该反映现实世界的用例。例如,FewRel数据集面对关系分类缺乏现实属性,这些属性在 TACRED地址中很少见。IMDb数据集在二元情绪分类的时候,只考虑高度两极分化的正面和负面评论,标签是不变的。这种基准测试在简单的信息检索中是可行的,但在现实世界中就不太合理了。
NLP社会责任的第一条规则是“完全按照你说的去做”。这句话是由 Chris Potts提出的。作为该领域的研究人员,我们应该得出基准上的绩效反映了什么,以及这与现实世界的环境是如何对应的。同时, Bowman 和 Dahl 认为基准上的良好绩效应该意味着任务领域内的稳健绩效。
因为任务的实际应用可能会产生与训练分布不同的数据。所以评估模型的稳健性以及评估模型对此类分布数据的泛化程度值得被关注。同理,具有时间偏移的数据和来自其他语言变体的数据也需要受到关注。
另外,由于 NLP研究中的语言种类很简单,而且要避免使用英语作为研究的单一语言。所以在设计基准时,我们
要涉及到其他语言的测试数据,这样可以减少研究的片面性,为多语言交汇提供可能。同时,也能在问答和总结等任务中利用其他语言数据集为模型的多功能性能提供证据
。
我们知道,在接下来的道路上,语言技术会给我们带来很多困难,但也会为我们的评估和基准提供新的灵感。基准是我们领域最自豪的成果,它通常会指引我们一个新的研究方向,同时基准在反映我们现实世界的技术和野心时至关重要。
-
-
-
-
“不管人们多么希望绩效是一个单一的数字,但即使是没有分布的正确均值也会误导人,而错误的均值肯定也好不到哪里去。”-约翰·马西
技术的下游用例可以为我们的评估提供指标。尤其是,下游应用程序需要考虑的不是单一指标,而是一系列约束。Rada Mihalcea希望我们不要只关注准确率,还应该关注实际应用的其他方面,比如特定环境中什么最重要。简单的说,NLP的功能取决于用户的需求。
机器学习研究一般不会过分强调社会需求。但是在实际应用中,
模型不能表现出不利于社会的行为
,所
以在特定任务的测试中这种表现会成为评估模型的一部分标准。
实际应用最注重的是效率。效率的高低与样本效率、FLOPS和内存约束有关。就是说,如果内存不够或是其他资源有限,评估模型就只能转向其他研究方向。比如,NeurIPS 2020的高效质量保证竞赛(min等人,2020)展示了检索增强和大量弱监督问答对集合的好处(Lewis等人,2021)。
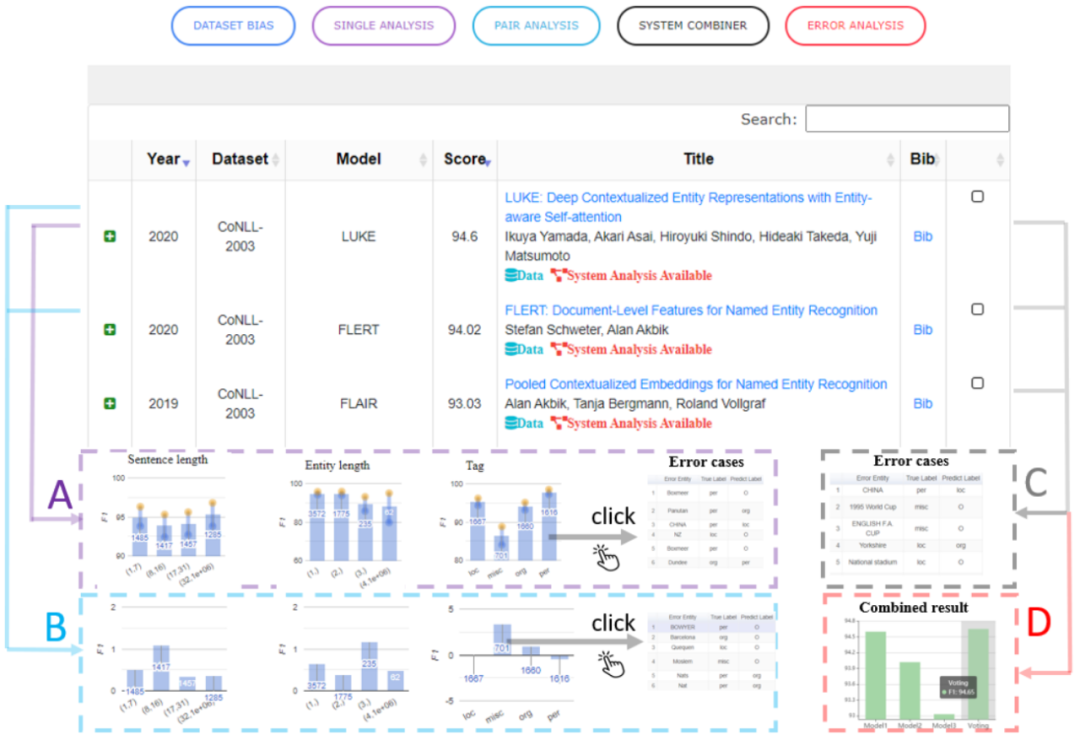
为了更了解模型的优缺点,我们会对单一指标进行细粒度评估,标注模型擅长和失败的示例类型。ExplainaBoard(Liu et al.,2021)在不同任务中实现了模型性能的细粒度细分,如下所示。获得模型性能更细粒度估计的另一种方法是为特定现象和模型行为创建测试用例,例如使用CheckList框架(Ribeiro et al.,2020)。
用于三个最佳系统的CoNLL-2003 NER数据集的ExplainaBoard接口,包括最佳系统的单系统分析(A)、前2个系统的成对分析结果(B)、公共误差表(C)和组合结果(D)(Liu et al.,2021)
As individual metrics can be flawed, it is key to evaluate across multiple metrics. When evaluating on multiple metrics, scores are typically averaged to obtain a single score. A single score is useful to compare models at a glance and provides people outside the community a clear way to assess model performance. However, using the arithmetic mean is not appropriate for all purposes. SPEC used the geometric mean, nx1x2…xnn, which is useful when aggregating values that are exponential in nature, such as runtimes.
一般用单个指标可能会出现缺陷,需要跨多个指标评估,通常我们会将分数平均,以获得单个分数。单个分数有助于快速发现模型的区别,并为其他领域的人提供评估模型性能的方法。不过这种算数平均方法不适合所有模型。SPEC使用几何平均值,在聚合指数性质的值。
另一个减少缺陷的方法是使用
加权总和
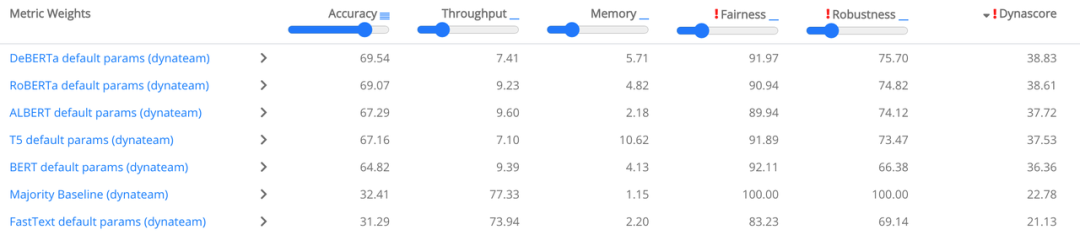
,让用户能够自己定义每个组件的权重。DynaBench使用这种方法来衡量模型的性能,同时也用这种方法评估模型吞吐量、内存消耗、公平性和稳健性。在下图中,用户可以定义自己的排行榜(Ethayarajh 和 Jurafsky,2020 年)。
DyaBench自然语言推理任务排行榜中的动态度量加权
-
-
-
-
因为当前模型在分布内示例上的表现很好,所以我们开始关注分布的尾部、异常值和非典型示例上。
现在我们不但关注平均情况,也开始关注模型表现最差的数据子集。
随着时间的推进,模型越变越强,模型性能也发生了变化。所以强模型和最佳模型的示例的比例将会变小。为了确保这个长尾示例评估的可靠性,基准测试需要足够庞大才能检测到性能的微小差异。值得一提的是,
规模较大的模型不一定有较大的优势
。
除了扩大模型规模,我们还可以开发机制,仅用很少的例子就能辨别出最佳的系统。这种方法在昂贵的测试环境下有很大优势。比如,在自然语言生成的人类评估中 Mendonça et al.(2021)将此框定为MT背景下的在线学习问题。
最近对抗基准采取的方向是解释更难的例子,这种基准如果不偏向特定模型就可以补充常规基准。这些对抗基准采取的方向在评估方法的帮助下,可以识别或者生成尖锐的例子来评估模型性能,也能帮助注释者更好地理解模型的决策边界。
由于基准的预算(以及规模)通常保持不变,统计显著性测试会很重要,因为它使我们可靠地检测系统之间的性能差异
。
基准的注释在正确的情况下才能进行比较。但是有些看起来错误的例子其实不是注释的错误,而是注释产生的歧义。也是不久前Bowman and Dahl (2021)强调了模型如何利用这种歧义的线索在基准上达到超人的性能。
如果可以,基准能收集多个注释来识别例子。这些注释会帮助基准分析错误。同时也会增加标准指标的重要性,因为这种多注释会给模型的基准性能设置上限。
-
-
-
-
"当一个措施成为目标时,它就不再是一个好的措施."-古德哈特定律
GLUE等多任务基准已经成为领域进步的关键指标,但这种静态基准很快就过时了。
模型的更新使跨任务的进展无法统一
。虽然模型在多数GLUE任务上都取得了超人的表现,但在 CoLA 等一些任务上与人类仍有差距(Nangia 和 Bowman,2019 年)。同时在XTREME 上,模型的跨语言检索方面有了很大改进。
因为模型改进太快,我们
需要更灵活的模型评估机制
。具体来说,就是除了动态单任务评估(例如DynaBench),还有就是定义基准数据集的动态集合。该集合由社区管理,等到模型达到人类性能并定期添加新的数据集时,社区会删除或降低数据集的权重。这样的集合需要进行版本控制,以便能够在学术审查周期之外进行更新,并且与以前的方法进行比较。
现有的多任务基准测试,例如GEM ( Gehrmann et al., 2021 ),旨在成为“活的”基准测试,通常包括大约 10-15 个不同的任务。
由于不断发布的新数据集的数量,如果要将基准测试限制为一小部分代表性任务,还不如将包含更大的 NLP 任务得出的结果有用
。同时NLP 中任务的多样性,将为模型性能提供更稳健和最新的评估。百度的LUGE是朝着如此庞大的中文自然语言处理任务集合迈出的一步,目前由28个数据集组成。
任务的集合可以通过各种方式分解,分解后得到对模型能力的更细粒度的评估
。如果任务根据模型正在测试的行为分类,则这种细分会非常有洞察力。BIG-Bench是最近的语言模型探测协作的基准,包括按关键字分类。
这种大规模多任务评估的一个重要挑战是可访问性。就是说,任务需要以通用输入格式导入,以便它们可以轻松运行。此外,任务应该高效运行,即使没有太多计算要求,基础设施也要可用于运行任务。
另外,这样的集合有利于大型通用模型,为财力雄厚的公司或机构提供训练。而且,这些模型已经被用作当前大多数研究工作的起点,一旦经过训练,就可以通过微调或修剪使之更有效地使用。
-
考虑收集和评估大型、多样化、版本化的 NLP 任务集合。
为了追上建模发展的速度,我们需要重新审视很多默认的基准测试,比如F1分数和BLEU等简单指标。还需要从语言技术的现实应用中思考现实设置给模型带来的影响。另外也应该关心分布的长尾,因为这是许多应用程序可以观察的到的地方。最后,我希望我们可以通过多指标和统计显著性测试来严格的评估我们的模型,使之越来越完善。
原文链接:https://ruder.io/nlp-benchmarking/