2021数据科学就业市场最全分析:Python技能最重要,5到10年经验最吃香
作者:Sujan ShirolR、oberto Iriondo
机器之心编译
编辑:蛋酱、杜伟
分析了 3000 多个数据科学相关的岗位招聘内容,他们总结出了十点重要规律。

import pandas as pdimport numpy as npfrom selenium import webdriverfrom selenium.common.exceptions import NoSuchElementExceptionchromepath = r'D:\Drivers\Chrome Driver\chromedriver.exe'url_list = []for i in range(1, 50):print('Opening Search Pages ' + str(i))page_url = 'https://jobportalexample.com/data-scientist-jobs-'+str(i)driver = webdriver.Chrome(chromepath)driver.get(page_url)print('Accessing Webpage OK \n')url_elt = driver.find_elements_by_class_name("fw500")print('Success')for j in url_elt:url = j.get_attribute("href")url_list.append(url)driver.close()
url_list_copy_cleaned = [i for i in url_list]out_company_df = pd.DataFrame(url_list_copy_cleaned, columns=['Website'])out_company_df.head()

jobs={'roles':[],'companies':[],'locations':[],'experience':[],'skills':[]}driver = webdriver.Chrome(chromepath)for url in out_company_df['Website']:driver.get(url)try:name_anchor = driver.find_element_by_class_name('pad-rt-8')name = name_anchor.textjobs['companies'].append(name)except NoSuchElementException:jobs['companies'].append(np.nan)try:role_anchor = driver.find_element_by_class_name('jd-header-title')role_name = role_anchor.textjobs['roles'].append(role_name)except NoSuchElementException:jobs['roles'].append(np.nan)try:location_anchor = driver.find_element_by_class_name('location')location_name = location_anchor.textjobs['locations'].append(location_name)except NoSuchElementException:jobs['locations'].append(np.nan)try:experience_anchor = driver.find_element_by_class_name('exp')experience = experience_anchor.textjobs['experience'].append(experience)except NoSuchElementException:jobs['experience'].append(np.nan)try:skills_anchor = driver.find_elements_by_class_name("chip")each_skill = []for skills in skills_anchor:each_skill.append(skills.text)jobs['skills'].append(each_skill)except NoSuchElementException:jobs['skills'].append(np.nan)driver.close()

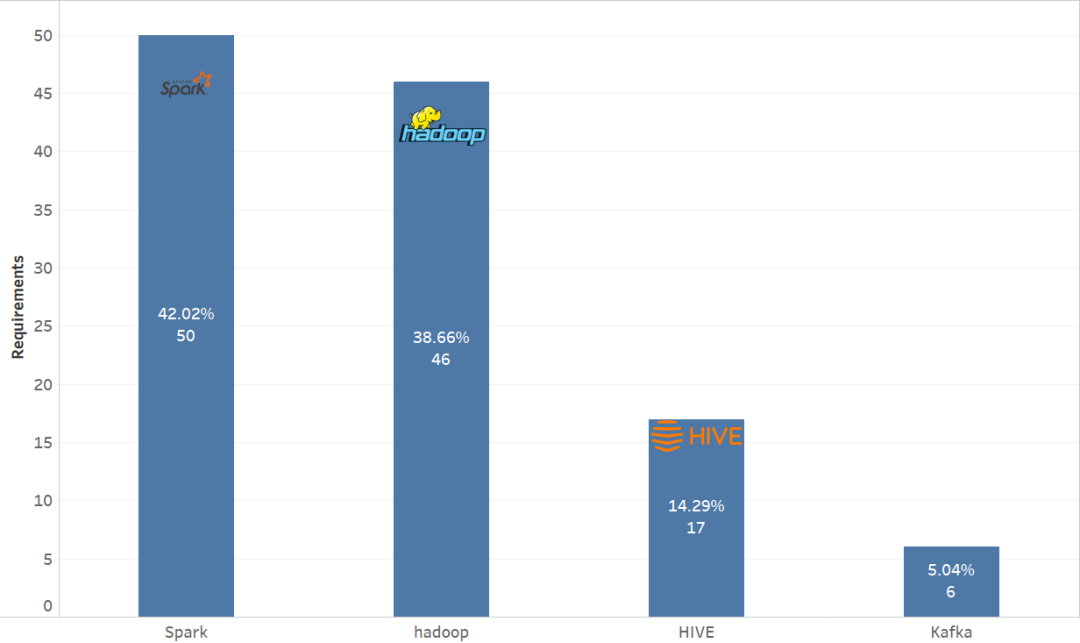
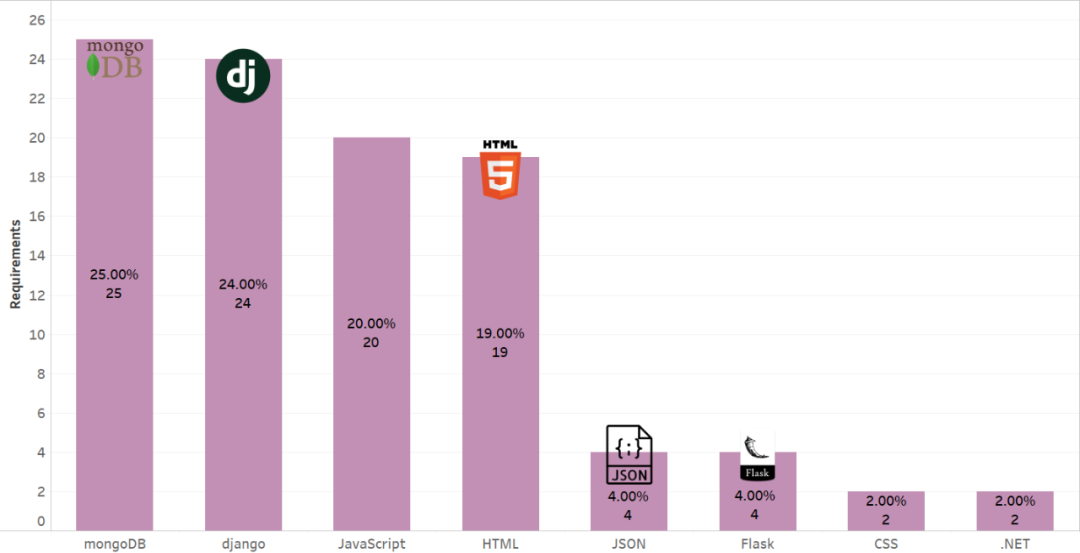
CVPR 2021 线下论文分享会

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
登录查看更多
相关内容

Arxiv
17+阅读 · 2021年7月10日




相关VIP内容
相关资讯
相关论文
Arxiv
17+阅读 · 2021年7月10日