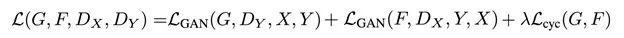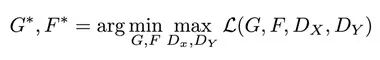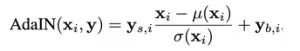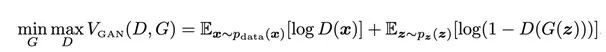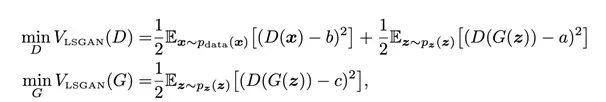![]()
编译 | 王念
编辑 | 丛末
生成式对抗网络(Generative Adversarial Networks, GAN)诞生于2014年,它的作者Ian Goodfellow 因它而声名大噪,被誉为“GAN 之父”。
据说GAN是Goodfellow手握扎啤在酒吧灵机一动所得(咦?这篇文章突然散发出麦芽的香气)。GAN的诞生是AI界的里程碑,为这个本已生机勃勃的领域打开了一扇全新的大门。
近些年,针对GAN的研究层出不穷。科学家们纷纷为自己的工作冠以各种高大上的名字,以此烘托出自己的与众不同和十足的神秘感。
然而所谓科研的实质就是“填坑”,当一个大牛提出了创新技术,它的衍生品自然会层出不穷。
比如在初代GAN诞生后,便有人提出为其“加装轮子”,成为CycleGAN(独轮GAN);但是一个轮子走不稳,于是经过改造就有人忽悠出一辆BiCycleGAN(自行车GAN);自行车忽悠过了,就有人提出ReCycleGAN(轮椅GAN)。照这个架势,相信在不久的将来,我们还会迎来三蹦子GAN、越野车GAN、SUV GAN和SpaceX GAN(狗头保命)。
GAN的成功要归功于其在计算机视觉上的惊人效果。相对于VAE等传统技术,GAN能合成更加逼真的图片,这些图片真的能到以假乱真的地步。GAN在计算机视觉方向的成就斐然,实用性有口皆碑。然而人们不甘止步于此,所以在近些年,大家又在关注如何将其利用到声音、文字等其他数据场景。比如说:
在这篇文章中,让我们共同领略GAN的魅力,一口气看尽GAN领域当下最流行的“弄潮儿”,尤其是这六位:CycleGAN, StyleGAN, DiscoGAN, pixelRNN, text-2-image 和 lsGAN。
在此之前,我们不妨先看下初代 GAN 的相关原理和核心思想:
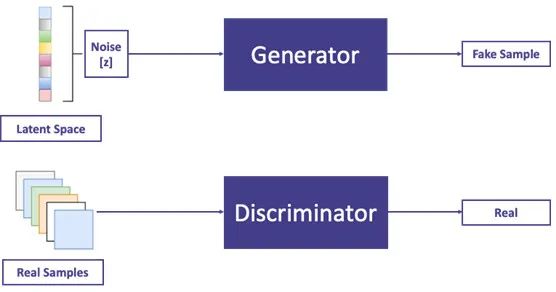
我们知道监督学习包括生成式模型和判别式模型两大类。其中判别式模型可以进行分类任务,比如根据输入的图片判断图中物体的种类。而生成式模型主要用于合成跟训练样本具有类似特征的数据,可以理解成合成“假数据”。
我们可以把生成式模型看作一个数据生成器,它能根据学习到的模式源源不断地产生“看起来类似但不完全相同”的数据样本。今天我们的主角GAN就属于生成式模型。
从数学的角度来看,任何数据都有自己的概率分布特点。生成式模型的任务是从有限的训练数据中总结出这个概率,将这个概率学习成一个“公式”、一个“模型”或者一种“模式”。当它学习到这个样本的分布特点后,模型就能够据此源源不断地生成新的伪数据了。
有些童鞋可能会问这些伪数据有什么用呢?例如在影视作品中,每个群众演员都是很贵的,只要露脸了他的薪酬可能就需要翻番。但在有了GAN之后,导演就能像种树一样合成虚拟的群演——“种人”,从而节省很多人力成本。另外在医疗场景下,患者样本可能特别稀缺,那为了平衡数据集,一生就可以利用GAN产生部分患者数据,避免模型过拟合的问题。
生成器就像是制造伪钞的印刷机,它负责根据随机噪声产生合成样本(伪钞);而判别器就像是验钞机,它负责识别这个输入样本是否为假数据(伪钞)
。生成器的输出都是假数据(Fake Sample),而训练集中的样本就是真样本(Real Sample)。
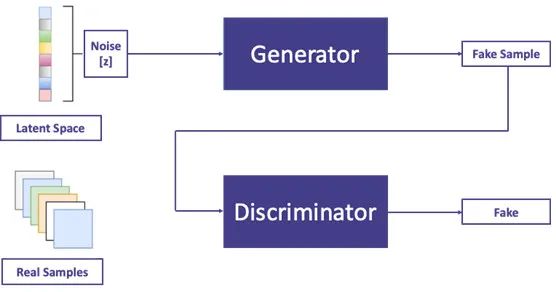
当我们训练判别器时,如果模型的输入是生成器的伪数据,那这个样本对应的标签就是Fake;如果输入的是数据集中的真实样本时,它对应的标签就是Real。这样能形成一个良好的负反馈,在训练判别器“鉴伪”的同时,也逼着生成器增强自己“造假”的能力。
GAN成功之处在于生成器和判别器的“左右互搏之术”。
生成器会竭尽全力生产“假钞”,试图让所生成的假数据通过判别器的严格审查。而判别器也会尽一切努力严格执法,揪出每一个合成数据,让“假钞”们无所遁形。
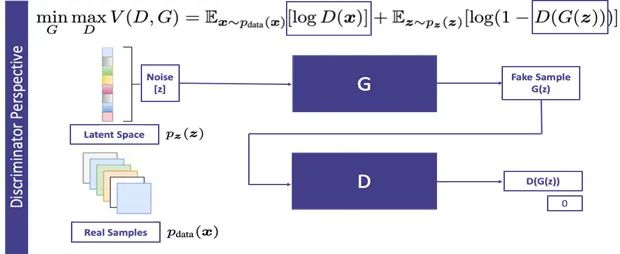
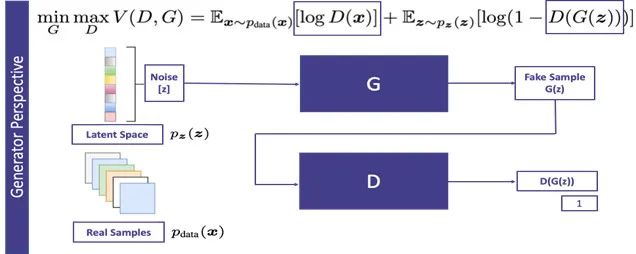
下面我们简单的看一下GAN的目标函数以及优化方法。本质上来说,GAN需要解决和优化的是一个最小-最大优化问题(min-max optimization)。生成器的任务是最小化目标函数,而判别器的任务是最大化这个目标函数。
待优化的目标函数如图3所示。在公式中,D是判别器,G是生成器。Pz是潜在空间的一个概率分布,其实就是一个随机的高斯噪声,它是生成假数据的源头。Pdata是训练数据集的概率分布。当x是从Pdata中真实采样的,我们便希望分辨器将其判别为真样本。G(z)是生成器合成的假数据,当我们将其输入判别器的时候,我们希望判别器能够将其判别为假样本。
判别器的目标是最小化D(G(z)),也就是最大化(1-D(G(z)))。而生成器的目标是最大化D(G(z)),也就是想让判别器犯错,看不出这是个假数据,从而达到以假乱真的效果。所以生成器的目标是最小化(1-D(G(z)))。判别器和生成器的目标相反,所以这是一个
典型的最小-最大优化问题(min-max optimization
)。
不知道大家有没有玩过一款叫做FaceApp的软件,它能让我们“穿越”时光,看看中年、老年时候的我们。译者亲测,效果十分震撼和可怕。译者在第一次使用的时候愣了足足十余分钟,仿佛真的见到了50年后的自己,甚至有种窥透天机的恐惧感。FaceApp中就使用了CycleGAN技术来实现这种“穿越”,或者专业点,叫领域转换(Domain Transformation)。
言归正传,CycleGAN在近些年大火,
它是一种广泛应用于风格转换的GAN模型
。举例来说,它能学习到艺术作品和真实照片之间的映射关系和变换方法。当我们用手机拍一张照片,CycleGAN就能将它自动变成油画;反之,CycleGAN也能还原艺术画作创作时的真实照片,让画面更加真实、让我们身临其境。此外,CycleGAN还能学习到例如马匹和斑马之间的变换,也能让照片里的季节背景自由切换。
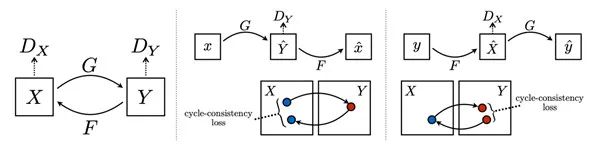
为了方便介绍和陈述,我们用马匹和斑马的变换作为案例。这里设X数据集中都是马匹的图片,而Y数据集中都是斑马的图片。
CycleGAN的目标是学习一个映射函数G,实现马匹到斑马图片的变换。用公式表达起来就是G:X->Y。和普通GAN一样,CycleGAN中也有自己的生成器和判别器。其中生成器的功能是根据输入的马匹图片,输出一张让判别器以为是真实斑马的图片。这个目的能够通过最优化对抗损失(Adversarial loss)来实现。需要注意的是,CycleGAN不光能学到马匹到斑马的映射函数G,也能通过使用循环一致性损失(Cycle-Consistency Loss)学到逆向的、斑马到马匹的映射函数F:Y->X。
在训练的过程中,模型有两组输入。第一组输入样本{X1, Y1}中的每个Xi(马匹)均有其所对应的斑马图片(Yi)。而第二组数据{X2, Y2}中,每个马匹样本Xi和斑马图片(Yi)都是不匹配的。
我们前边提到,CycleGAN能够学习到G和F这两个映射函数。第一个是G,它能将马匹图片X转换成斑马图片Y。第二个是F,它负责将斑马图片Y转换成马匹图片X。所以CycleGAN其实是由两个独立的GAN组成的,也就包括了2个生成器Gx, Gy,以及2个判别器Dx和Dy。
其中Dx的任务是检查输入的Y和真实的斑马Y之间有没有差异。同样的,Dy的任务是检查输入的X和真实的马匹图片集X间有没有差异。这是通过对抗损失的最小化实现的。
此外,CycleGAN中还有另一个损失,就是循环一致性损失(Cycle-Consistency Loss)。它是用来在训练中使用{X2, Y2}这组无匹配样本的数据集。循环一致性损失能够帮助模型最小化重构损失,也就同时实现F(G(x)) ≈ X ,以及G(F(Y)) ≈ Y。
所以总结起来,CycleGAN的损失函数由三个独立的部分组成:
以上就是CycleGAN的技术部分。CycleGAN的实际应用效果十分逼真,比如下面这张图片就使用CycleGAN实现了油画与照片的转换、马匹和斑马的转换,以及季节切换的效果。从结果中我们可以看到,模型学习到了斑马和马匹切换的诀窍,也领悟到了季节变换的精髓。
Linu Torvalds曾经说过:“Talk is cheap. Show me the code(能侃没啥用,有本事贴代码)”。CycleGAN的技术主要体现在损失函数上,所以在这里我们贴上一段损失函数的代码片段。感兴趣的同学可以自行查看论文原文。
![]()
效果没看够?我们再贴一张大图,来看看马匹和斑马之间的变换效果。
论文:https://arxiv.org/abs/1703.10593
CycleGAN的详细教程:https://www.tensorflow.org/tutorials/generative/cyclegan
GAN生成图片不是什么难事,但是真的很逼真吗~哼哼,小编觉得它估计还不行,轻易就能被人眼看穿!那童鞋你猜猜这两张照片哪个是真的哪个是GAN生成的假照片~
“emm…右边这张还有背景,它估计是真货!左边这个背景太单调了,估计是假的!”
哈哈,图样图森破!真相是,它俩都是GAN生成的假货!惊不惊喜、意不意外~(我倒是有点莫名害怕)
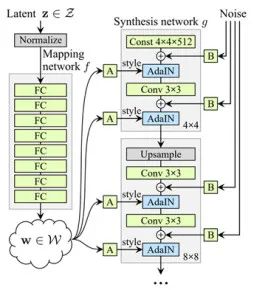
StyleGAN是近些年新出现的一种十分流行的网络模型。它能够生成分辨率为1024*1024的高清图片。
它的主体思想是堆叠很层的GAN,其中第一层用来生成低分辨率的图像,而后的每层都逐渐增加图片的分辨率。
在StyleGAN之前,也有一些人尝试提高图片的分辨率,它们大多是通过在图片中添加随机噪声或者插值的方式实现的。但是这样做的效果通常不好。StyleGAN发现了这个问题,它并没有通过添加无意义的噪声来“自欺欺人”。StyleGAN的做法是学习人脸的特征,并基于这个比较泛在的特点生成一个并不存在的人脸图像。如果你质疑StyleGAN的性能的话, 请戳这里,这个链接在每次打开的时候都会生成一张假的人脸图,这个人脸图是GAN随机产生的,而不是从训练集中粘贴出来的。
典型的StyleGAN的结构如上图所示。网络的输入在经过8层全连接网络的处理后被映射成一个潜在向量z,z中就包括了人脸的各种特征。而生成器的合成器由18层网络组成,它们将向量z从4*4的分辨率一直扩大到1024*1024,实现了分辨率的升高。但此时生成的图像还是黑白的,缺少RGB三个颜色通道。因此,StyleGAN在输出层上使用了独立的卷积结构来添加颜色通道。看到这么深的全连接的时候我们就能猜到,这个网络的参数量极大。事实上,它拥有2620万个参数需要训练,因此StyleGAn需要十分庞大的训练数据集,也需要十分昂贵的计算资源。
在StyleGAN中,每层网络都需要经过AdaIN归一化:
其中每个特征图都会首先进行独立的归一化操作,而后使用目标风格Y对应的属性进行缩放和偏置转换。因此Y的维数应为该层网络特征图数量的两倍。
论文:https://arxiv.org/pdf/1812.04948.pdf
Github代码:https://github.com/NVlabs/stylegan
在这个人人晒图的时代,我们随便上网就能爬到数不胜数的图像数据。但是这些“野生图片”都是没有标签的,而基于无标签数据的无监督学习方法很难学习到数据的分布特点。这个问题一致困扰着我们,直到PixelRNN的出现。
PixelRNN的强大之处在于它能学习到图像的离散概率分布,并预测或生成二维图像中的像素。
我们知道循环神经网络(RNNs)擅长学习数据的条件分布,比如LSTM能够学习到序列数据和序列像素点之间的长时依赖特点。在PixelRNN中,它采取了渐进式的生成方法,当我们给出了X0~Xi的数据后,它预测下一步Xi+1的结果,而基于X0~Xi+1的结果,模型又能输出Xi+2的值……以此类推,模型就能产生无穷无尽的数据了。
理论上来说,GAN网络学习的是数据集隐式的概率分布,而PixelRNN这样的自回归模型学习的是数据集显式的概率分布。这是因为GAN没有明确地在函数中引入概率分布项,它是通过让我们查看观察模型所学到的概率分布来实现相同的目的。
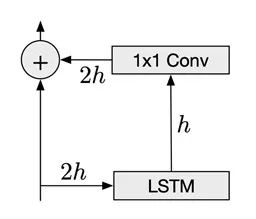
上图中是一个独立的PixelRNN残差块,模型会叠加、串联并训练若干层的残差块。一个典型的PixelRNN LSTM层的输入特征的高度是特征图高度的两倍,即2h。为了减少特征维度,LSTM将状态输入门的尺寸设为h。在递归层之后,PixelRNN使用1*1的卷积来将每个特征的尺寸扩大2倍,并将输入分量加入输出结果之中。
论文:https://arxiv.org/pdf/1812.04948.pdf
Github代码:https://github.com/NVlabs/stylegan
每当我们提起GAN,它给人的印象大概就是“不羁放纵爱自由”,没有太多的约束。它所生成图像的风格和样式都比较随意。
比如说,一个从小猫数据集上训练的GAN网络能够生成很多假的猫图~这些猫在毛色、运动状态、表情等等方面都很随机。比如可能生成一张黑猫在吃饭的图片,或是一张白猫在抓老鼠的图片,也有可能是一张橘猫盯着自己的赘肉惆怅的图片(狗头保命),具有不可控的随机性。当然了,它们都是一个鼻子两个耳朵的正常猫,符合猫的特征。
但是在商业领域中,人们往往需要精准掌控所生成的内容,严格按照人类控制生成一些样本,否则要是出现一些违法或者引起公愤的内容就得不偿失了。因此GAN很少应用在商业场景中。为了减少GAN生成图像的随机性,尽量控制其中的不可控因素,人们就想设计一种模型让GAN能够根据我们的预期和控制生成特定图像。
在这里,我们隆重介绍
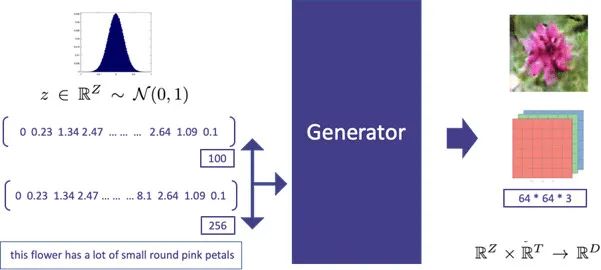
Text-2-Image模型,它能根据输入的文字描述,有针对性地生成特定的图像
。这对于GAN的研究来说是一项意义重大的进步。Text-2-Image的输入是文字描述,输出的是该描述所描绘的图片。
举例来说,当我们输入“一个有许多粉色的小圆花瓣的花花”的句子时,模型就能够产生一张真的有好多粉色花瓣的花朵图片,甚至还能把背后的绿叶背景也加上去:
在Text-2-Image模型中,生成器的输入不再是随机的噪声向量了,而是一段有明确意义和确定描述的文字。这段文字会首先经过嵌入(Embedding)层的处理进行编码,然后在编码的结果后掺入噪声向量并输入生成器模型中。
比如在下面的这个例子中,文字会首先被转换成256维的特征,然后和100维的噪声拼接,形成356维的超级向量。其中的噪声向量通常是从正态分布中随机采样的。
这种方法能够给生成器一个生成规则(就是明确的文字描述),使生成结果符合该规则,从而降低生成结果在该方面的随机性。
这样的设计思想会给判别器带来额外的压力和任务。它既需要判断输入样本是否为假数据,又需要判断输入样本是否符合了文字描述的要求。因此在训练的过程中,我们的输入数据格式就要进行调整,变成(图像, 文字)的数据对。具体来说,一共有三种情况:
(正确图片,正确描述)样式的数据,它的标签为1
(错误图片,正确描述)样式的数据,它的标签为0
(假图片,正确描述)样式的数据,它的标签为0
其中第一类样本是指我们为真实图片提供了正确的文字描述,模型通过它们能学习出图像的模式和文字描述之间的对应关系。第二类样本是指数据集中的描述和图片不相符的情况,模型能够通过它们了解不匹配是怎样一个现象。最后一类样本就是普通GAN中的假数据的判别,生成器通过学习它们来让生成器尽量生成看起来不那么“假”的图像。
具体到我们的花朵生成的例子中,训练数据集共有10种不同的组合:
下面我们来看一下Text-2-Image模型的生成结果,领略一下这台听话的伪钞机的风采~
论文:https://arxiv.org/pdf/1605.05396.pdf
Github代码:https://github.com/paarthneekhara/text-to-image
最近一段时间,DiscoGAN备受学术和工业界的关注。这主要是由于DiscoGAN能够学习跨领域非监督数据间的关联性。
对于人类来说,不同领域之间的关联信息通常是很容易总结和学习的。比如在下图中,我们一眼就能看出第一行的图片都是书包,第二行的图片都是鞋子,第一行和第二行对应图片在颜色特征上是一样的。
然而在人工智能领域,模型很难挖掘出这种不匹配图像之间的关联和共性信息。所以为了解决这个实际存在的问题,研究人员发明了DiscoGAN,希望它能够学习到不同领域数据间的关联信息。
DiscoGAN和CycleGAN的核心思想十分类似。
DiscoGAN也需要学习两个映射函数,一个用来学习领域X到领域Y的正向变换方法,另一个用来学习Y到X的反向的变换函数
。而原始图像和经过两次变换后的重建图像间的不匹配程度使用了重构损失来进行计算。
此外,DiscoGAN的设计规则和CycleGAN也很类似,即希望将领域A的图像先转换到领域B,再将其从领域B转换回领域A,然后想让这个二手的切换回来的结果能够和原始图像尽量匹配,有种“出淤泥而不染”的感觉。
DiscoGAN和CycleGAN的
不同之处在于,DiscoGAN为两个领域都单独使用了一个重构损失函数,而CycleGAN只使用一个统一的损失对其进行表示
。
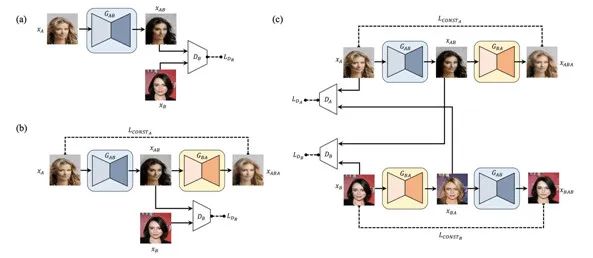
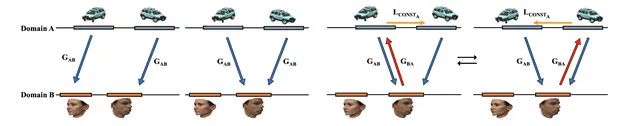
(a)Vanilla GAN (b) 使用了重构损失的GAN (c) DiscoGAN
DiscoGAN中的重要思想是利用重构损失函数表示原始图像和重构图像之间的差异。换个角度来看,它的变换就是从一个领域转换到另一个领域,再从那个领域变换回来。两个领域间来回切换转换的过程是不是像极了夜店蹦迪的大灯球来回照射,难道人们因此才将其称为迪斯科GAN(DiscoGAN)?哈哈。在领域A的数据变换到领域B后,数据被变换到另一个领域中进行编码表达,而在将领域B的数据转换回来的时候,DiscoGAN希望转换回来的二手结果能够跟原始数据尽力那个匹配。所以
从数学的角度来说,DiscoGAN就是希望最小化重构损失值。
总结来说,DiscoGAN包括两个独立的GAN网络,一个是GAB,一个叫GBA。在上图中,模型正在尝试学习汽车和人脸这两个不同领域的数据图像中物体的“方向”信息。在模型重建数据之后,图像中的物体方向应尽量和原始方向一致。
论文:https://arxiv.org/pdf/1703.05192.pdf
Github代码:https://github.com/SKTBrain/DiscoGAN
无监督的数据通常是很便宜的,因为不用人类对其进行昂贵的标记。因此很多研究都在探索将GAN应用在无监督学习的应用上。
在常规的GAN模型中,有一个让人挠头的问题就是梯度消失。梯度消失的原因有很多,其中一个就是判别器中使用的交叉熵损失函数。为了解决这个问题,
LsGAN提出使用最小二乘损失函数替代交叉熵
。实验证明,在这样操作之后LsGAN能够生成更高质量的图像结果。
我们首先回顾一下,在Vanilla GAN中,模型使用最小最大化优化方法训练模型。模型中的判别器是二分类的,输出的结果非真即假。因此Vanilla GAN的判别器中使用了sigmoid对结果进行激活,并且使用交叉熵作为损失。
这样的设计会加剧模型训练中梯度消失的问题,因为对于那些位于决策超平面正确一边的样本来说,它们会远离特征空间中样本分布密集的区域,从而产生极大的梯度(误差值提高了嘛)。而当我们使用最小二乘损失函数的时候就没有这个问题了,它能够让学习的过程更加稳定,从而产生质量更高的图像结果。
下图是LsGAN需要优化的目标函数,其中a是假数据样本的标签,b是真实样本的标记,c是生成器希望判别器器对假样本判别所输出的值。
因此,在这种场景中就有两个独立的待优化损失函数。一个是训练判别器用的,一个是训练生成器用的。
相比于Vanilla GAN来说,LsGAN具有很多优点。在Vanilla GAN中,因为判别器使用二分类交叉熵损失函数,所以如果一个样本的分类结果正确,那它的损失值就=0。
但是在LsGAN中,决策结果并不是损失值的唯一判定标准。在lsGAN中,就算一个数据处于分类超平面中正确的一边,但一旦它距离决策边界很远的话,模型也会给予它很高的损失。
这种惩罚的方式迫使生成器朝向决策边界产生数据。因此这也能在一定程度上解决梯度消失的问题,因为那些远离分类边界的样本就不会产生巨大的梯度了。
论文地址:https://arxiv.org/pdf/1611.04076.pdf
Github 开源地址:https://github.com/xudonmao/LSGAN
文末闲侃
所有GAN网络结构都有一个共性,它们都是基于对抗损失进行构建和训练的。每个网络都有一个生成器,也有一个判别器。它们的任务是互相欺骗,在左右互搏的过程中提升彼此。
GAN在近些年大放异彩,已经成为机器学习领域中最热门的研究方向之一。相信在不久的未来,我们会看到更多更有意思的GAN!
这个Github库系统地整理了GAN相关的研究论文,感兴趣的小伙伴不妨一读哦:
https://github.com/hindupuravinash/the-gan-zoo
参考文献见原文:
https://towardsdatascience.com/6-gan-architectures-you-really-should-know-d0b7373a2585
AI 科技评论希望能够招聘 科技编辑/记者 一名
办公地点:北京
职务:以跟踪学术热点、人物专访为主
工作内容:
1、关注学术领域热点事件,并及时跟踪报道;
2、采访人工智能领域学者或研发人员;
3、参加各种人工智能学术会议,并做会议内容报道。
要求:
1、热爱人工智能学术研究内容,擅长与学者或企业工程人员打交道;
2、有一定的理工科背景,对人工智能技术有所了解者更佳;
3、英语能力强(工作内容涉及大量英文资料);
4、学习能力强,对人工智能前沿技术有一定的了解,并能够逐渐形成自己的观点。
感兴趣者,可将简历发送到邮箱:jiangbaoshang@yanxishe.com
点击"阅读原文",直达“CVPR 交流小组”了解更多会议信息。