learn to see in the dark-低照度图像增强算法
本文由知乎ID赵春林授权发布,转载请联系原作者
我们知道在暗光条件下拍出来的照片噪点多,清晰度差,采用针对低光照条件下的图像增强算法可以明显提升图片质量。传统的方法有直方图均衡,同态滤波,基于暗通道的去噪等等。深度学习的有HDR Net,稀疏降噪自编码器等等。今天要介绍的是来自CVPR 2018,由UIUC,Intel,腾讯联合出品的一篇文章:learn to see in the dark。效果惊艳!如下图所示,左侧是传统方法的结果,右侧是本文要介绍算法的结果。

背景
有较为丰富的拍照经验或者有过图像处理经验的人都知道,在暗光条件下拍出来的照片不清晰,噪声很大。对于照相机,其输出的信号的信噪比可由下式表示:

上式中,C表示输入电容,T表示绝对温度。在照相设备不变的前提下,分母不会改变。分子Qs与一个光敏单位所承载的光电子数目成正比。因此,光照好,信噪比高;反之则反。
要想提高信噪比,改善图像质量,可以改善硬件,或者延长曝光时间,也可以通过图像后处理算法。改善硬件意味着增加成本,延长曝光时间可能会放大噪声,同时带来运动模糊。这里主要讨论图像后处理算法。
暗光照条件下的图像增强算法有很多,比如直方图均衡,同态滤波,BM3D降噪,HDR Net等等。这些方法都存在各自的弱点,比如只解决单一问题,金标准都来自于仿真数据,无法适用于极端自然场景等等。针对这一系列的问题,这篇文章主要做了两个方面的工作来实现暗光照条件下图像的增强:1、建立了一个自然场景下的数据集;2、利用这个数据集训练了一个FCN网络。
数据集
想要建立一个好的数据集,绝对不是一件简单的事,特别是对于以数据作为驱动的深度学习算法。我个人在项目上,曾经有过比较惨痛的教训,以至于做到一半时不得不从头再来。先说说我自己对于如何建立一个数据集的一点点反思:首先需要明确自己的目的,其次是要明确数据的标准,再次是要确立好标记的工具,然后是需要考虑扩展性,接着是调研类似的数据集,最后一点也是十分重要的一点要明确自己能够调动的资源。最最最最最重要的一点是一定要review,在小批量标记之后一定要相互之间review。
下面看看这篇文章的作者他们是怎么建立数据集的。
首先,明确自己的目的:自然场景、极端低光照。那么,这个数据集不能用仿真数据,必须实地采集。同时,也需要包含室内室外。最后,为了和其他算法(比如burst denoising,需要多帧低光照图像)做对比,对同一个场景同一个拍摄角度会采集多帧图像。
下面是具体的采集方法。
我们的数据集包含了室内和室外图像。室外图像通常是在月光或街道照明条件下拍摄。在室外场景下,相机的亮度一般在0.2 lux 和5 lux 之间。室内图像通常更暗。在室内场景中的相机亮度一般在0.03 lux 和0.3 lux 之间。输入图像的曝光时间设置为1/30和1/10秒。相应的参考图像 (真实图像) 的曝光时间通常会延长100到300倍:即10至30秒。
数据采集时,相机固定在三脚架上。我们用无反光镜相机来避免由于镜面拍打引起的振动。在每个场景中,相机设置 (如光圈,ISO,焦距和焦距) 进行了调整,以最大限度地提高参考图像(长曝光时间)的质量。此外,利用远程的智能手机 app 将曝光时间缩短一倍缩小后的曝光时间为100至300。该相机专门用于参考图像 (长曝光时间) 的拍摄,而没有触及短曝光的图像。我们收集了一系列短曝光的图像用于方法的比较和评估,以突出我们方法的优势。
虽然,数据集中的参考图像仍可能存在一些噪音,但感知质量足够高。我们目的是为了在光线不足的条件下产生在感知良好的图像,而不是彻底删除图像中所有噪音或最大化图像对比度。因此,这种参考图像的存在不会影响我们的方法评估。
整个数据集的信息见下表:

部分截图如下:

前面的是长曝光的照片,也即是金标准,后面的暗一点的照片就是短曝光的照片,也就是网络的输入。
FCN网络
有了数据集,接下来就是训练网络了。这篇文章中的pipeline如下图

对于输入的raw数据,先打包成4个通道,然后对每个通道做一次2两倍的下采样。然后将放大因子作为一个输入,送进网络(这里的放大因子指的是输入图片和金标准之间曝光时间的倍数)。输出是一个12通道的feature map,最后转化为sRGB图像。
主体的网络结构选择了CAN(快速图像处理的多尺度上下文聚合网络)和U-NET,后续有对比这两种主题网络结构的区别。
不同的放大倍数,网络输出的图片亮度也差别很大。下面是一个实例图片。

采用L1 Loss作为网络的损失函数,优化器选择了Adam,没有加载预训练模型。在每次迭代中,对一张输入图片进行随机裁剪。裁剪的大小为512*512,然后进行翻转,旋转等进行数据增强。初始的学习率设置为0.0001,在2000次epoch之后,学习率降为0.00001。总共迭代4000个epoch。
实验
1.与传统的算法对比
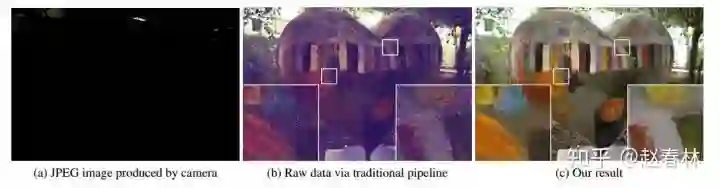
可以看出来和传统的算法比起来,利用这篇文章的算法处理之后的图片,噪声小很多,色彩也更丰富一些。
还有量化的评价指标。

还有一个采用PSNR(峰值信噪比)和SSIM(结构相似性)作为评价指标的表格。
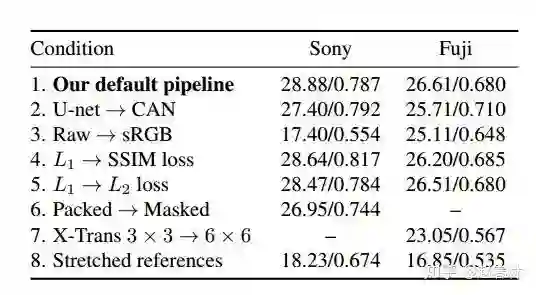
注:default pipeline是指采用U-NET,然后L1 loss。
可以看出,U-NET换成CAN之后,客观评价指标会有下降。下面的图片结果也说明了这个结论。

结语
总体来说,这篇文章建立了这样一个数据集,以及基于这个数据集训练的模型还是很有意义的。之后,其他研究者和从业者,也可以拿这个数据集做很多其他的研究。
但也正如作者在文章里说的,他们的方法中没有加入色调映射,数据集里也没有采集人和动态的图片。另外呢,放大因子也需要手动输入,没有实现自动化。同时,算法不够实时,不能用于移动端。
这些都是未来可以改进的地方。但我想有了这样的尝试,后续会有更多的人朝着这个方向努力。
论文地址:
https://arxiv.org/abs/1805.01934
Github地址:
https://github.com/cchen156/Learning-to-See-in-the-Dark



