【技术揭秘】数据黑手操控美国大选,脸书何以封杀剑桥分析?


今日聚焦
近日,剑桥分析(Cambridge Analytica, CA)利用用户隐私数据进行心理侧写,在选举中发挥“神奇”助选效果。顷刻之间,舆论哗然,莫衷一是。数据黑手如何操控美国大选?剑桥分析又何以遭到封杀?接下来,有请自动化所中科闻歌的工程师小哥哥上线,揭秘剑桥分析的"夺权黑科技"!
据《纽约时报》和《观察家报》报道:一款名为“this is your digital life”的应用收集了5000万Facebook用户的数据,并将数据转移给位于伦敦的政治分析公司CambridgeAnalytica (剑桥分析,CA)。“剑桥分析”在未经用户同意的情况下,利用个人数据进行用户行为及心理分析。在秘密录制的视频中,该公司被停职的CEO表示,它们发起的网上拉票对美国总统特朗普2016年胜选起到决定性作用。
随着联邦贸易委员会的介入和媒体的后续曝光,事件不断发酵。3月25日,扎克伯格在英国《观察家报》、美国《纽约时报》、《华盛顿邮报》、《华尔街日报》英美数家主要报纸上刊登道歉信,就Facebook公司在保护用户数据方面犯的错误道歉。4月5日,Facebook公司承认,多达8700万名用户的个人数据被不恰当地共享给了“剑桥分析”,远大于之前公布的5000万。
Cambridge Analytica提供商业营销(CA Commercial)和政治竞选(CA Political)两种产品,本次主要分析其政治竞选产品。
CA Political依靠必要的数据,依靠预测分析,行为科学和数据技术,实现实时深入理解选民,并通过个性化广告的精准投放,有效地影响选民行为。
尽管大数据营销和个性化推荐并不新鲜,但CA的分析方法的确有所不同。他们分析的是人的心理特征,而不是人口统计学特征。CA的技术特点是将社会心理,行为科学与大数据分析相结合,其采用的对于搜集到的个人信息分析的计算模型最初是来自于Michal Kosinski,其发明的个人信息计算模型可以根据简单的个人信息就推断出该数据提供者可靠的个性特质。
通过查阅相关文献,作为CA技术的原型,其主要源自剑桥大学心里测度学实验室(The Psychometrics Centre)【1】Michal Kosinski成果。CA原型模型的功能如图1:
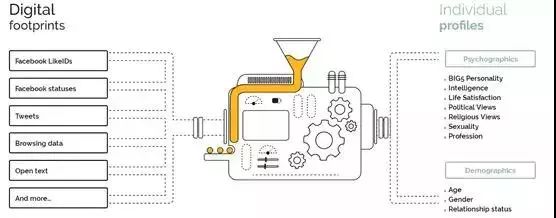
通过分析非隐私的网络痕迹信息(digital footprints:用户愿意共享,易于从社交媒体上获取的数据),获取涉及隐私的个人信息(individual profiles:用户通常不愿共享,难以从社交媒体直接获取的信息,如政治倾向)。
通过Facebook和Twitter收集数据或从第三方购买了一系列其他数据(如关于电视偏好,航空旅行,购物习惯,教堂出勤率,购买什么书籍,您订阅哪些杂志组织等)。其开放的数据集:myPersonality【2】,包含Facebook用户的likes(来自美国的58,466名志愿者样本)和他们的Facebook个人资料信息,心理测试分数和调查信息。
主要涉及的算法:奇异值分解(SVD)+线性回归(LR)/逻辑线性归回(logsitcLR)。
具体流程,示意图见图2:
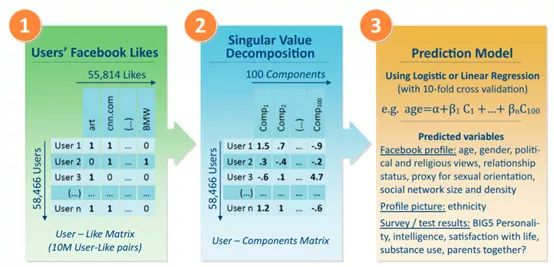
◆将用户的点赞信息(likes)表示为稀疏的用户喜好矩阵(纵轴为不同用户,横轴为不同事物,如果某用户点赞了某一个事物,则对应的矩阵位置被设置为1,否则为0。
◆使用奇异值分解(SVD),降低用户喜好矩阵的维数。降到k维,即得到前k top组件(component),表示用户的喜好。一般情况,k = 100。对于性取向,父母关系的地位和药物,使用k = 30,因为该信息可用的用户数量较少。
◆对于数字变量,如年龄或智力,使用线性回归模型(LR)进行预测。而对于二分变量,如性别或性倾向预测,使用逻辑回归(logisticLR)。(应用10倍交叉验证)
输出信息有数字型和二分量两种结果。
◆数字变量
年龄,生活满意度(SWL),友谊网络的大小和密度,智力程度,The Big Five Personality (包括Model开放性(Openness,对新经验的开放程度),尽责性conscientiousness,完美主义程度),外向性(extraversion,社交活跃程度),随和性(agreeableness,体贴和合作程度),情绪稳定性(neuroticism,焦躁不安程度))。
◆二分变量
性别,关系状态(是否单身),性取向,物质使用(酒精、毒品、香烟),种族出身(白种人还是非裔),政治观点(民主党还是共和党),宗教(基督教还是伊斯兰教),是否来自单亲家庭(是否是和父母一直呆在一起,直到个人21岁)。
社交媒体数据:通过APP(MTurk和Qualtrics),吸引facebook用户做心理测试。大约在2014年6月到8月间,一共有27万用户做了测试。通过这个测试收集了27万用户的信息和这27万用户的好友的信息。据说共获取了5000万Facebook用户的个人信息。
社会调查数据:每天对17个州的选民进行民意调查,实时监测运动的进展情况。总的来说,通过在线和电话调查在17个重点州调查了180,000人。
利用心理测度学,行为科学,数据科学和预测分析专业知识,构建了20个可用于预测选民行为的自定义数据模型。每次调查一个人时,CA都会将调查者的信息与CA数据库中的现有数据进行匹配。分析从他们的投票历史到他们驾驶的汽车的所有内容,CA确定与投票决策相关的行为,并预测个人投票的方式。进而,CA将选民放入不同的类别,并确定通过投放广告来影响他们的投票行为。
CA技术的特点在于成果借鉴了心理测度学的成果。基于Facebook,twitter等社交媒体数据的心理测度学的其他成果归纳如下:
◆基于大规模数据集,研究Facebook活跃度(number of contacts)和用户个性特点之间的关系。【4】
◆研究显示出用户的个性特征和Facebook简历信息的重要相关性,并展示如何基于Facebook资料,运用多元回归预测个人用户的个性特征。【5】
◆研究twitter用户个性特征和twitter个人使用数据的关系,并开发了一种基于following, followers, and listed counts三类信息而精准预测个性特征的模型【6】
咳咳,有待探索……,此处省略若干字。
参考资料与文献:
1)https://applymagicsauce.com/about_us.html
2)www.mypersonality.org/ wiki 或
https://apps.facebook.com/mypersonality
其他参考文献,请关注“闻歌大数据”后点击可见

更多精彩内容,欢迎关注
中科院自动化所官方网站:
http://www.ia.ac.cn
欢迎后台留言、推荐您感兴趣的话题、内容或资讯,小编恭候您的意见和建议!如需转载或投稿,请后台私信。
来源:中科闻歌
编辑:鲁宁、欧梨成


中科院自动化研究所
微信:casia1956
欢迎搭乘自动化所AI旗舰号!




