加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
本文授权转自知乎作者邵典,https://zhuanlan.zhihu.com/p/130720627。未经作者允许,不得二次转载。
不正经的引言
CVPR2020满分论文(3 strong accept),走过路过不要错过,reviewer看了都说好。你要问我好在哪?
正经的导读:
视频中的动作理解一直是计算机视觉领域的热点研究方向。原有的工作一般都是面向粗粒度的动作识别与分析,在许多现有数据集上相关研究已经遇到了瓶颈。
我们这篇工作则独树一帜,提出了一个大规模、高质量、层级化标注的细粒度人体动作数据集:FineGym。在这一数据集上,我们对现有的各类动作识别方法从多个层级多个角度进行了分析,得了很多有趣的结果,对领域一些固有结论产生了挑战,也为未来的研究带来了一些启发。
值得注意的是,除了支持动作识别任务,FineGym丰富的标注内容还可以支持其他动作相关的研究,如时域动作检测、动作质量评估、动作生成、动作属性识别等。基于这些特点,我们的工作在CVPR2020中,也获得了3 strong accept的满分成绩。
一、要点概览
为什么值得关注?
1) FineGym数据集的建立过程对行业有启发意义。2) 作为目前最全面的结构化细粒度动作数据集,FineGym开辟了新的研究土壤,为原有领域注入新的活力。3) 基于FineGym, 我们从粗粒度到细粒度对现有的SOTA方法进行了多角度分析,体现了粗粒度和细粒度动作理解的区别,研究了采样方法、时域信息整合、模型预训练等在细粒度动作理解方面的问题和特性,开放性地指出了现有方法的局限性和未来可能的研究方向。
值得什么人关注?
对视频动作识别、检测、生成等感兴趣的研究者。此外,论文中的分析表明在FineGym上现有的人体检测和姿态估计方法的结果误差很大,因而从事相关工作的研究者也可关注一下。
那么,既然都9102+1年了,一篇做数据集的文章究竟算哪块小饼干,可以在激烈厮杀、在CVPR2020中获得如此高分呢?
如果大家有兴趣一探究竟,那么可以接着看看以下的详细解读。
二、数据集的建立
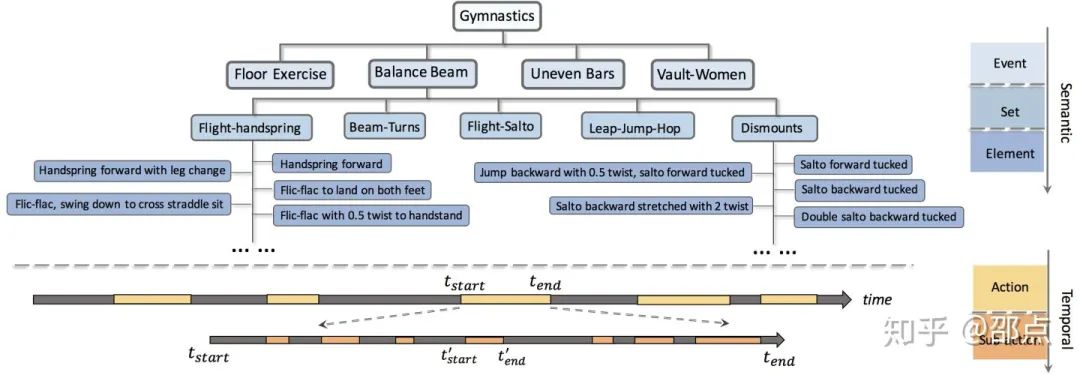
“三”:在语义层面,FineGym定义了三层的语义类别结构,遵循着从粗粒度到细粒度的顺序,它们包括:事件类别(event),组类别(set)和元素类别(element)。
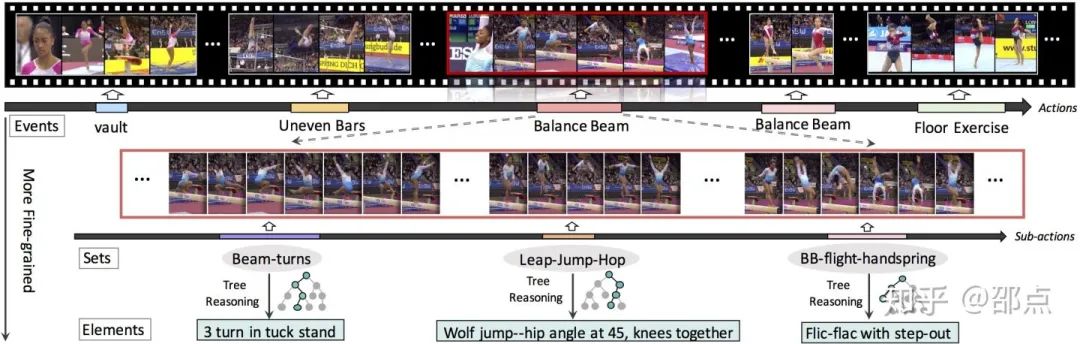
“二”:在时域上,FineGym具有两层的结构,分别为动作和子动作。一个长视频中会出现多个动作,它们的开头和结尾会被标注。同时,一个动作内部会有多个子动作,这些子动作的时域位置会被标注。动作由事件类别来描述,而时域上更细粒度的子动作可以由组类别和元素类别两种粒度进行描述。
[没空看可以跳过这部分,本节主要是怨念的作者传达“我太难了”的核心思想]
建立这样一个标注复杂、定义清楚、专业高质量的数据集,且标注粒度需要延伸到现有工作所未涉足过的细致程度,也算是“摸着石头过河”。期间遇到了许多“拦路虎”:
“巧妇难为,无米之炊”
:建立数据集的第一步是收集视频数据。以往类似的大规模视频数据集的数据来源基本是两种:一种是通过大型视频网站爬取数据;另一种则是提供相应的视频内容描述,直接要求众包人员自行演出、录制并上传视频。然而,这两种方式对于FineGym的数据收集都不适用。为什么呢?首先,FineGym的语义粒度需要延伸到元素类别,然而不幸的是,以元素类别为关键词如“交换腿跨跳转体180度”,在视频网站上很难搜索到高质量、内容匹配的视频;另一方面,FineGym基于专业度高、灵活性强的体操运动,普通人基本没可能标准地做出相应的动作。对此,我们采取的解决办法是,首先按照年份调研国家级及以上的专业体操比赛,之后下载相应的比赛视频,并逐个视频进行人工排查与清理,保证原始数据的清洁和专业性。
“乱花渐欲迷人眼”:
越细粒度的语义类别定义,越容易产生更多的类别数量。那么如何定义并组织数量众多、差别细微,容易混淆的类别呢?本文中采用的解决方法有两个方面。第一,类别的语义定义不再草率地人为制定,而是参考体操领域的专业知识,以国际体操协会发布的专业动作及打分手册为绳墨。第二,采用层级化的结构,粒度最细、数量众多的元素类别,则由树状结构进行组织。
“术业有专攻”:
有了数据并定义了类别之后,所需的标注又如何产生呢?FineGym的标注需要具备足够的专业知识,所以也不能像以往一样简单地依靠众包平台。对此,我们专门筛选和组织了一支专门的标注团队,对其进行了必需的专业知识培训,并进行了相关专业知识的考核和测试。在经历了多轮培训、测试与数据试标注后,标注团队完全满足FineGym所需要的专业性和高质量的要求。
“吾日三省吾身”:
对于细粒度数据集来说,其“阿喀琉斯之踵”是标注的质量问题。相比于粗粒度的标注,同样比率的错标误标,在细粒度的类别间容易引入更多的问题和更大的混乱。针对这个问题,我们采取了一系列的标注质量监控措施, 包括但不限于每日监控每一位标注人员的标注质量并及时反馈以避免重复性错误,标注人员间严格互检,标注团队的高比率二次检验等。
FineGym的建立包括原始视频数据收集、标注团队团队提供标注、后期的严格质量筛查等过程。要点这里不再赘述。
目前,FineGym收集了体操领域10种不同的事件类别(男子六种+女子四种)共三百多场专业比赛。
我们对女子的四种事件(女子跳马,女子平衡木,女子自由体操和女子高低杠)进行了“3+2”的细粒度标注。
基于这四种事件类别,FineGym定义和筛选了15个组类别,并由此进一步定义了530种不同的元素类别,其中共354类目前具有子动作数据,这种情况源自于体操动作本身使用的不均衡性。FineGym保留了原始的分布,但也提供了两版不同的数据集以供选择:
Gym99共99类,数据分布相对更加均衡;
Gym288共288类,数据分布较不平衡。
截止现在,FineGym已提供了两个版本的数据标注,提供了六千多个动作数据和3万多个子动作数据的细致标注。
详情请访问FineGym的project homepage:https://sdolivia.github.io/FineGym/
值得注意的是,FineGym中子动作的持续时间往往很短,大部分在几秒的长度,但信息量却很大(下面的实验部分有提到)。这种短时限制有效保证了数据的细粒度。
我们的标注的收集将会持续进行(有钱就进行,逃),欢迎大家持续关注。
三、“妙则不粗,湛则不浑”:数据集特点
a.原始数据高质量:
国家级及世界级的体操运动比赛视频,动作来自于专业运动员;
b.类别定义清晰:
借鉴体操运动标准和完备的动作参考手册,避免了类别增多带来的定义不清楚、类别间语义不一致等问题;
c.高分辨率:
所收集的视频大多为720P和1080P,更好地保留动作的视觉细节,也为后续更加精细的标注(如关键点)提供了良好的基础;
d.高标注质量:
FineGym的标注团队经历了严苛的培训、测试与筛选,最终的标注结果也接受了层层的质量把控。
a.丰富的层级结构:
时域方面,FineGym具有两层结构,而类别语义的层级则有三层;
b.粒度最细的一层具有530个定义清楚的类,超过了现有的所有细粒度数据集;
c.FineGym中的视频具有多样的拍摄角度,其动作也涵盖了各异的人体姿态,甚至包括很多不常见、高难度的极端姿态。
3.完全以人体动作为中心:
FineGym所收集和标注的体操数据,其背景都有很强的相似和一致性,研究的关注点完全放在视频中的运动员身上。这一点避免了模型在识别过程中喜欢“走捷径”的问题,即只学习背景、物体等与动作无关的信息来完成分类。
4.决策树标注过程
带来了比动作标签本身更丰富的信息:从根节点到叶子节点的路径还原了整个分类过程,并且记录了某一类运动最显著的属性标签集合。同时,在叶子节点中,每一个类别的动作还标注了其难度分数,可用于动作难度评估的研究。
四、“下马看花”——现有方法分析
实验分析的主要关注点在最细粒度的元素类别识别。在此之前,我们先简要在较粗糙粒度上(event&set),进行了相关实验和分析。由于粗粒度实验不是重点,我们选取了当前业界广泛应用的方法——TSN,以点带面。实验结果如下:
这个performance高,但不是我们的主要关注点哦
有趣的是,在最粗粒度的事件类别(event)识别中(也是当前动作识别领域的数据集和方法所关注和研究的粒度),appearance特征的贡献远远超过了Flow(光流)特征,并且准确率已经趋于饱和。
然而一旦往更细的粒度(set)前进,光流特征的作用则开始逐渐凸显。
这说明更细粒度的动作识别需要模型的关注点逐渐回到动作本身,而不能通过仅仅学习一些场景和物体信息就能很好地对动作进行分类。这一趋势在元素类别的识别中体现的更加明显。
下面就进入了方法分析的“重头戏”部分(细粒度识别实验)。
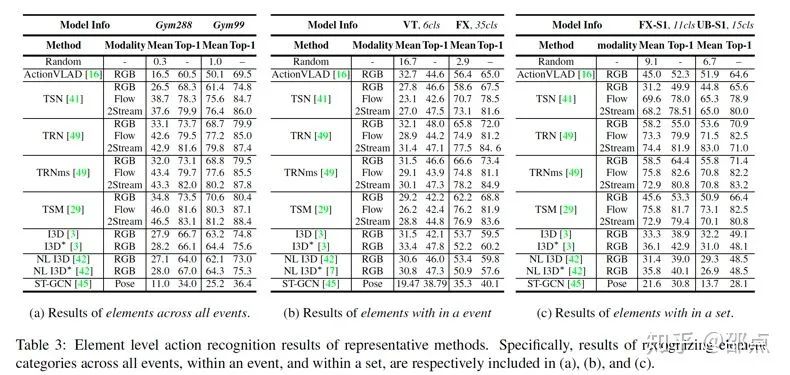
我们将现在主流的几类动作识别方法都在FineGym上进行了测评,具体有:
2D+1D模型,包括TSN, TRN, TSM和ActionVLAD;
基于3D卷积核的方法:I3D, Non-local;
最近火起来的基于人体关键点的识别方法,代表为ST-GCN。
实验在多个层级不同语义范围内进行,全方位地对模型进行测评分析。从字体大小可见诚意满满的实验结果如下图所示:
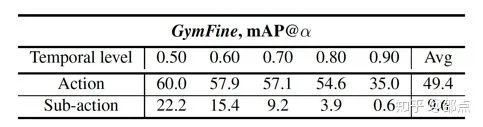
除了动作识别,文中还选取动作时域检测的开源代表方法——SSN,在动作和子动作两个不同的粒度上进行了实验。
实验结果表明,对细粒度的子动作进行准确时域定位仍没有得到很好地解决。
在以上实验的基础上,我们又进行了后续的更加细致、深入的分析,主要研究了以下几个不同的角度的问题:
稀疏采样和密集采样。
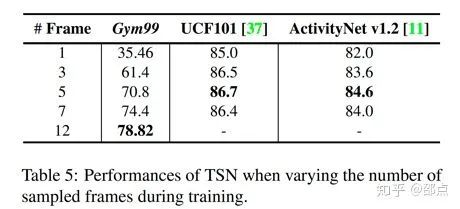
稀疏采样(sparse sampling) 在之前动作识别经典数据集如UCF101上十分有效,然而遇到了FineGym却遭遇了“滑铁卢”。
如下面的实验数据所示,在UCF上只用2.7%的采样率(5帧)TSN的识别准确率就达到了饱和,而在FineGym上的元素类别识别则需要采样30%(12帧)以上的数据帧。
这佐证了FineGym细粒度动作数据的信息丰富性,即“帧帧有用,帧多势众”。
基于视频的视觉理解,和图像理解相比,最大的特点应该就在于提供了丰富的时域信息。但是在以往的视频动作数据集上,时域信息的效用并没有得到非常明显的体现。
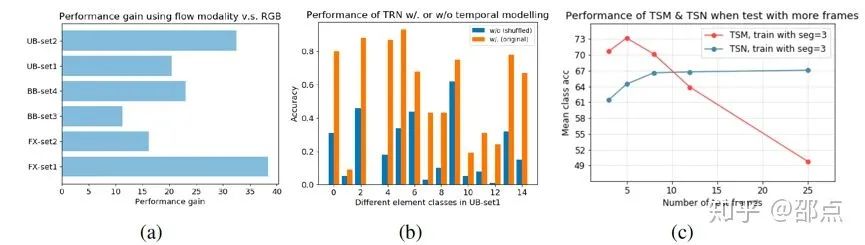
但是在FineGym上,对时域动态信息的整合和利用就显得尤为重要。我们在文中用三个不同的实验分析证明了这一观点,
a) 对TSN而言,在给定不同的组类别进行元素类别识别时,光流信息相比于RGB特征对结果贡献显著更多;
b) TRN学习了帧间关系来建模时域信息,然而一旦将输入的帧的顺序打乱,TRN 的表现将大幅下降。
c) 对于没有时域建模的TSN来讲,当测试的帧数逐渐超过训练帧数,识别的表现会因为引入新信息而变好并饱和;而对于在模型设计中嵌入了时域建模的TSM来说,当测试帧数和训练帧数的差异过大,学到的时域模型不再适用,识别准确率将“一落千丈”。
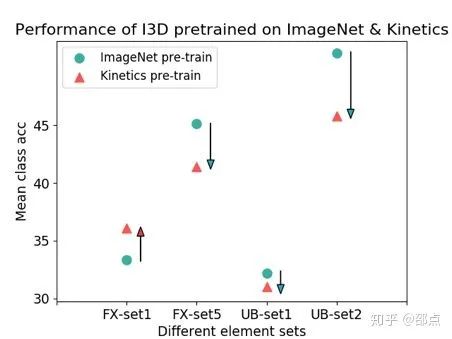
在视频动作识别领域,一个约定俗成的观念就是在大规模的视频数据集上进行预训练能够 大幅提升模型的识别准确率。
例如,在Kinetics数据集上进行预训练的I3D模型,在UCF101上的识别准确率可以从84.5%提升到97.9%。
然而这种视频数据集预训练在FineGym上并不能屡试屡验,如下图所示。
我们认为,一个可能的原因是细粒度与粗粒度动作的时域模式可能有较大的差异,因此预训练所学难以迁移。
最后,通过详细的实验分析和观察,我们启发性地提出了一些让当前方法“力不从心”的问题:
密集、快速的运动,如各种空翻;
空间语义信息的细微差别,如腿部姿态的些微不同;
比较复杂的时域动态线索,如运动方向的变化;
基本的推理能力,如数出空翻的次数等。
此外,FineGym对一些动作理解的基础模块提出了更高的要求,如视频中的人物位置检测,人体关键点定位等。
五、展望和后续
除了以上的提到的视频动作识别和时域动作检测,FineGym丰富的标注和高质量的数据使其具备被应用于以下任务的可能:1)自动打分及动作质量与难度评估;2)动作生成(得益于其较为一致的背景和丰富的类别信息);3)动作多属性预测,即利用标注过程中的决策树储存的属性信息;4)模型推理与可解释性,即同样利用标注过程中的决策树。
此外,FineGym可能对未来的模型设计引入了一些新的可能和思考,如当面对这种信息量大、差异细微的动作理解任务,如何在提升采样率的同时保证模型的运行效率?如何更好地建模时域信息并保证其鲁棒性?这些都期待未来的研究者们发挥才智,尝试解决。
我们的FineGym会持续收集和增加标注,包括更细致的视觉标注(如人体关键点),视频数据的扩充、事件类别的扩充和延伸到其他领域等。有兴趣的话可以持续关注。
最后再多说两句,
我们的这篇工作只是朝着细粒度动作识别领域做了一点小小的探索,得到审稿人的一致垂青也实属侥幸。
工作本身还存在很多不足之处,“曲有误,周郎顾”,欢迎各位路过的大神批评指正(玻璃心作者求轻喷);
也欢迎大神们“且将新火试新茶”,在FineGym上进行模型设计与方法研究!
论文地址:
https://arxiv.org/abs/2004.06704
项目网站:
https://sdolivia.github.io/FineGym/
40万奖金的AI移动应用大赛,参赛就有奖,入围还有额外奖励
![]()
添加极市小助手微信
(ID : cv-mart)
,备注:
研究方向-姓名-学校/公司-城市
(如:目标检测-小极-北大-深圳),即可申请加入
目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群
,更有
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、
干货资讯汇总、行业技术交流
,
一起来让思想之光照的更远吧~
![]()
△长按添加极市小助手
![]()
△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~ ![]()