字节跳动Deep Retrieval召回模型笔记

今天讲讲字节的一个召回的文章:《Deep Retrieval: An End-to-End Learnable Structure Model for Large-Scale Recommendations》
召回因为候选集个数多,一般用MIPS的思路做,这样的问题在于:
1、向量最大内积模型表达 能力有限,缺少特征交互;
2、ANN的时候会通过聚类减小候选集(IVFAQ),但是这个聚类建立索引的过程,跟召回模型的训练是分开的,效果肯定不好;可能存在召回模型学好了,但是检索不出来的情况。
召回的时间复杂度:T*N <= Bound,目前的思路是在inference阶段减小候选集N(如TDM,beam search),这样就需要确定一个item的空间划分结构,这个结构是和模型训练阶段做joint learning的。因为空间结构是离散的,所以joint learning其实是一种EM算法,将空间结构当做是latent variable。细看,其实TDM也是这种范式,M step训练item embedding,E step通过聚类得到空间结构。
回到字节这篇paper DR上来
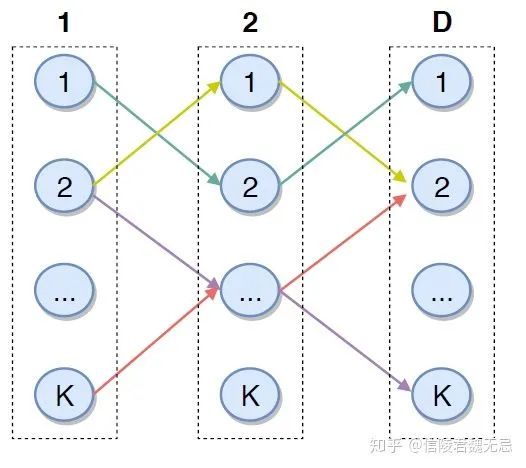
DR在item空间结构划分上,字节的DR用了一种矩阵结构,矩阵里面的路径对应item。
结构
使用一个D x K维的矩阵来作为索引结构。模型预测需要走D步,每一步有K种选择。走到最后会有K^D可能的路径(也可以叫做编码),每一条路径可以代表一个包含多个item的集合,每个item反过来也可以同时在多条路径的集合里面。路径可以看做是一个聚类结果。
不同的路径之间可能有交叉(有交叉的应该比较类似)
Objective
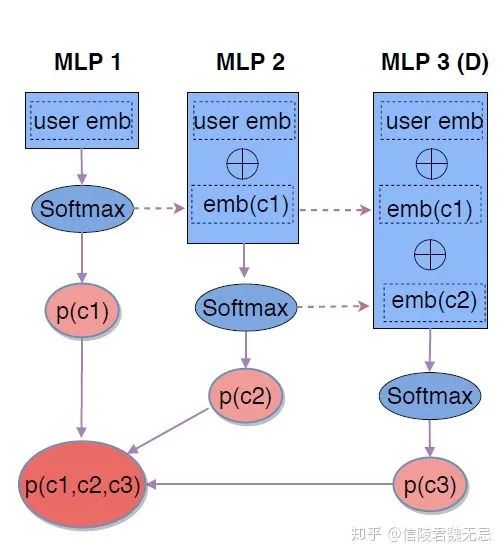
1、Structure Objective
每一层是一个MLP,输出K个概率,表示包含这个节点的概率,假设每个item对应的路径π固定。
1、emb(x)输入第一层MLP,生成K维的概率;
2、将路径上所有的embedding 全部concatenate起来,扔进去第d层的MLP内;
最后的概率是路径上所有概率的乘积:
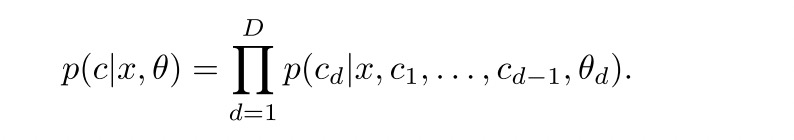
如果每个节点表示一个类别,多个类别乘起来,不过这不是独立的,所以怪怪的。
损失函数是log likehood,这里用(xi, yi)表示user,item,用π表示item->K^D条路径的映射。Π(yi)表示item yi对应的path
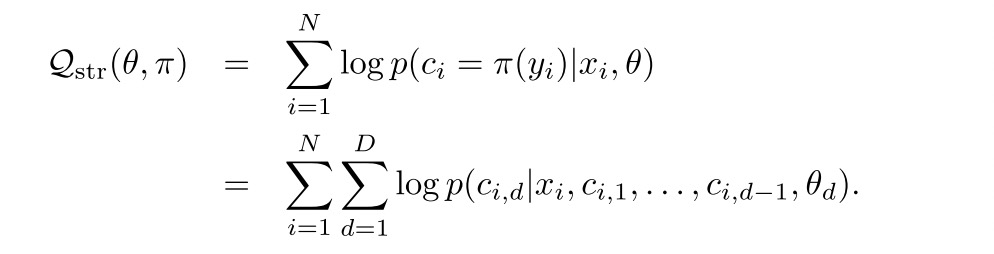
2、Multi-path structure Objective
每个节点属于多个路径,而不是单个,这是因为很多item都会被归到多个类里面去。比如巧克力和cake,既是food也是gift。而在TDM中,每个叶子节点只能表示一个item,一个item也只能包含在一个内部节点中。
DR将一个item对应J个path去。这个看到后面就很清楚了,其实一个item在EM算法的框架里面是可以对应K^D的路径的,但是每条路径对应的概率不同,现在是截断,取top J条。这里的π也表示item->path的路径,只不过现在有J个映射
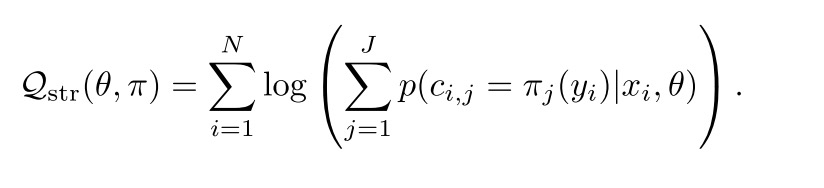
Learning
这里面item对应的路径是离散的,无法通过梯度下降去优化。Item->path的映射可以与聚类有点类似。所以用EM算法 train
下面是一个整体流程:

其中:
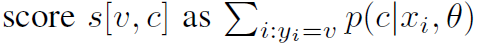
表示item在这个路径上所有概率的加权(item对应所有user加权)
每个item v, 通过beam search,在每一层选出J个node,最后得到J个路径。遍历所有item后就得到了item->path的map π
这里,将multi-path objective变换为遍历所有的item v,里面是item v对应的所有user->item pair
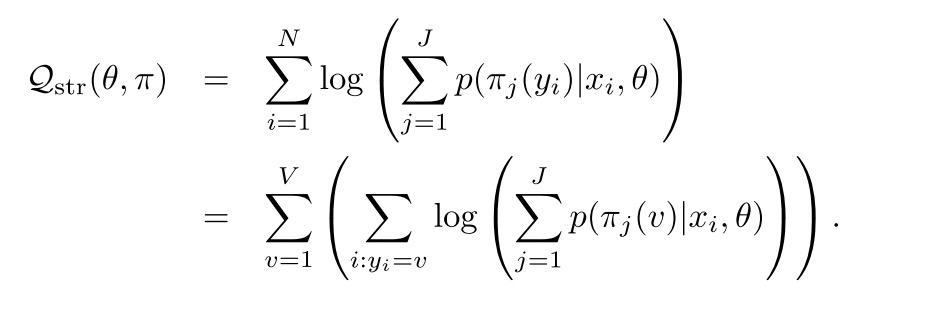
为了保证数值稳定性,这里用凸函数求了一个上界
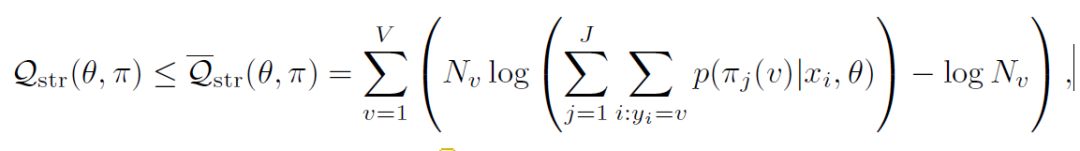
其中
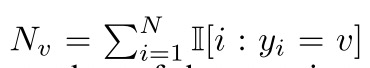
表示item v对应的user->item总数
正则化
DR这里的EM step貌似和我理解的是反的。我理解E step是得到隐含变量的概率(也就是item对应的top J path的概率);而M step是优化参数。字节的DR在E step是优化参数,M step是得到隐含变量的概率。在E step,优化的structure model可能出现overfit,导致某个path的概率很大;所以在M step,所有的item都到这个path去,导致无法聚类。所以在M step引入了path对应的item总数作为正则。
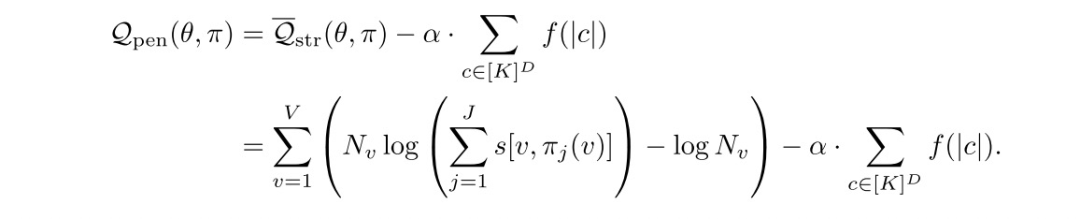
讨论
其实有几点的还是比较迷惑的,作者最后也说了
1、structure model的probability只是用了user侧的特征,没有用item的特征;
2、只是用了positive example来做;
还有一点是这个模型没法用item侧的特征,类似于YouTubeDNN,属于单侧建模
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏