知乎CTO李大海:谢邀,来分享下内容社区的AI架构搭建与应用
机器之心报道
作者:陈萍
谢邀! 知乎 CTO 来分享下内容社区的 AI 架构搭建与应用。



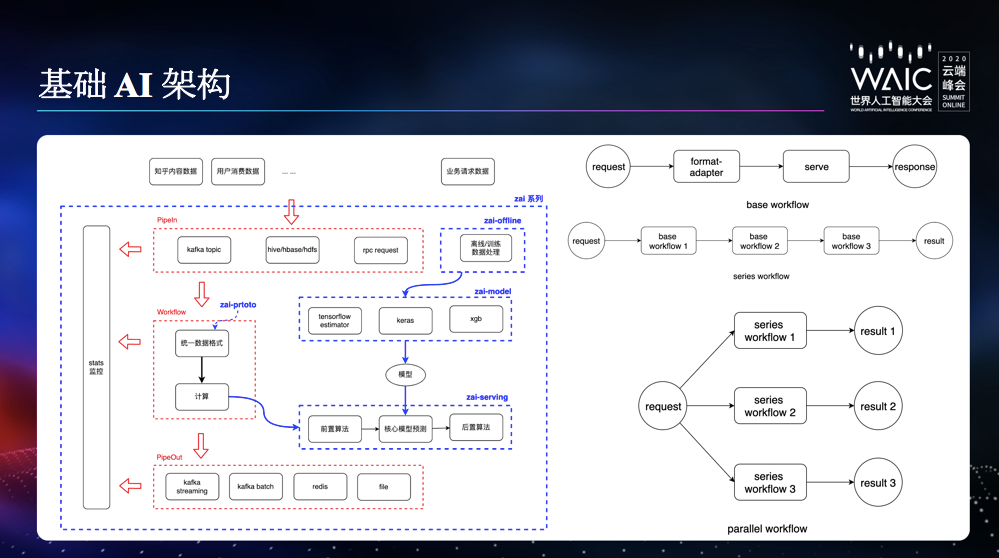
base workflow,通常只包含一种推断服务或预测服务。
series workflow ,其可以串联多个不同的 base workflow,形成一个更复杂的服务链,比如关键词服务,需要前序依赖分词服务。
parallel workflow ,其可以并联多种 series workflow,形成相对比较复杂的网络,比如监听内容创建 kafka topic,并分别进行多种预测处理。
数据管道和模型分离。
保留足够的模型灵活度,具有模型自定义的自由和模型相关超参调整的自由。
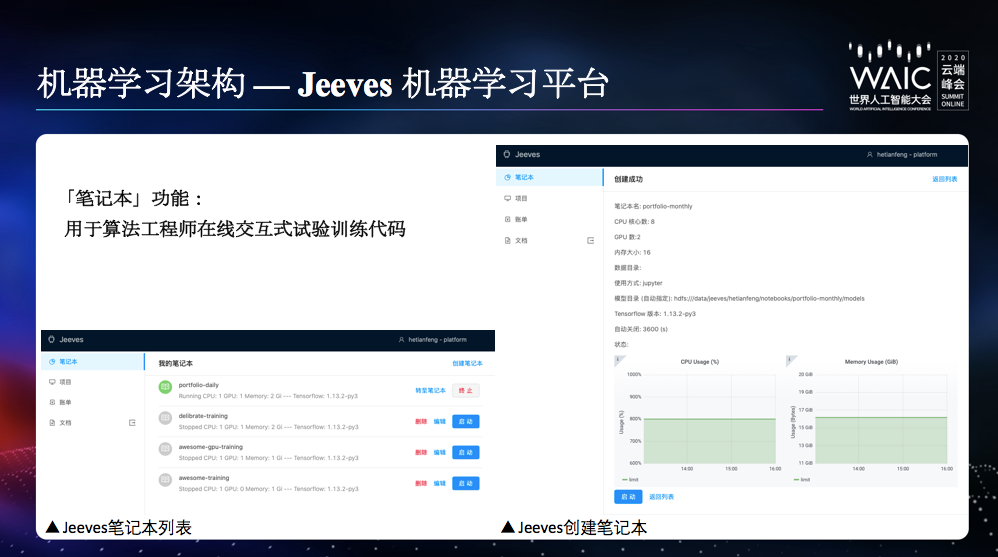
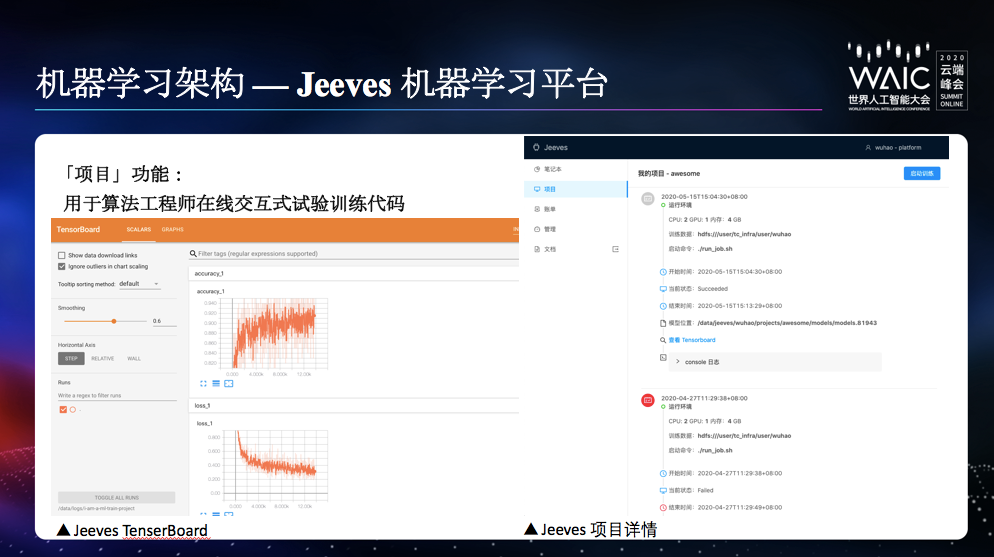
封装了训练、预测、评估、模型输出;只需要关心模型本身。
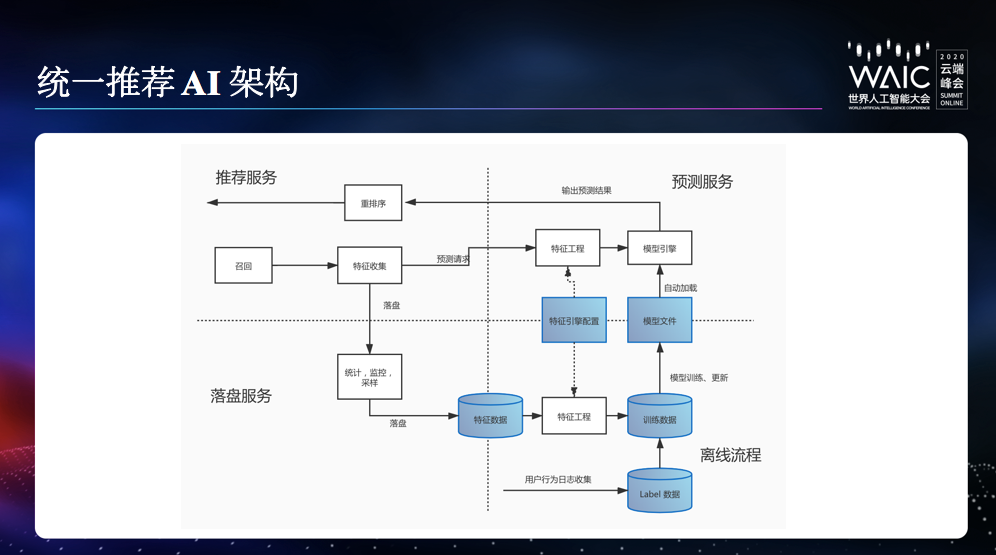
统一的完备的数据 schema,打通各业务线的数据,减少重复特征数据的落地成本,并成为统一推荐框架的标准输入。
统一的特征落盘服务,各业务线可根据业务特点,灵活填充 schema 中的特征字段,减少在特征落盘和训练数据管理部分的开发工作。特定业务还可以低成本的实现跨部门数据复用,打通不同部门之间的数据协同作用。
统一的训练数据流水线。
统一的特征工程框架。
统一的训练代码库。有利于模型结构复用,兼容离线训练和 online learning 训练。
统一的线上预测服务。支持 tensorflow 和 xgboost 的模型;支持模型的自动加载和更新;提供通用的特征、预测分数监控。支持 CPU 或 GPU 部署。优化公共特征计算。
特征工程配置化:管理使用哪些特征;增删特征无需改代码。避免了离线数据处理和线上预测服务代码不一致的情况。
特征工程模块化:我们把对特征数据的操作抽象成一个个操作子 (operator)。比如:Echo, OneHot 等。规范了 operator 的输入输出;每个 operator 可以处理不同的特征数据;大部分 operator 和具体的业务无关,代码可复用性大大增强。每个 operator 必须有严格的单元测试,保证了特征工程代码质量。
结构化数据字段获取动态加速,有效的提升效率。
自定义向量化特征数据格式:避免了 parse protobuf 的序列化、反序列化 cpu 开销,比 tensorflow 的 tf record 快很多,典型场景有 10 倍的性能差异。
流式特征覆盖率统计监控,特征分布统计。
样本数据分流。大的样本数据尽量落成一份,小的特殊业务可以进行灵活的分流。
跨业务的进行特征补全。
一站式配置管理、数据流管理、特征监控、指标监控。
通用化 online learning,让更多业务可以直接用在线学习的优势。
AutoML,降低业务使用机器学习模型的门槛。
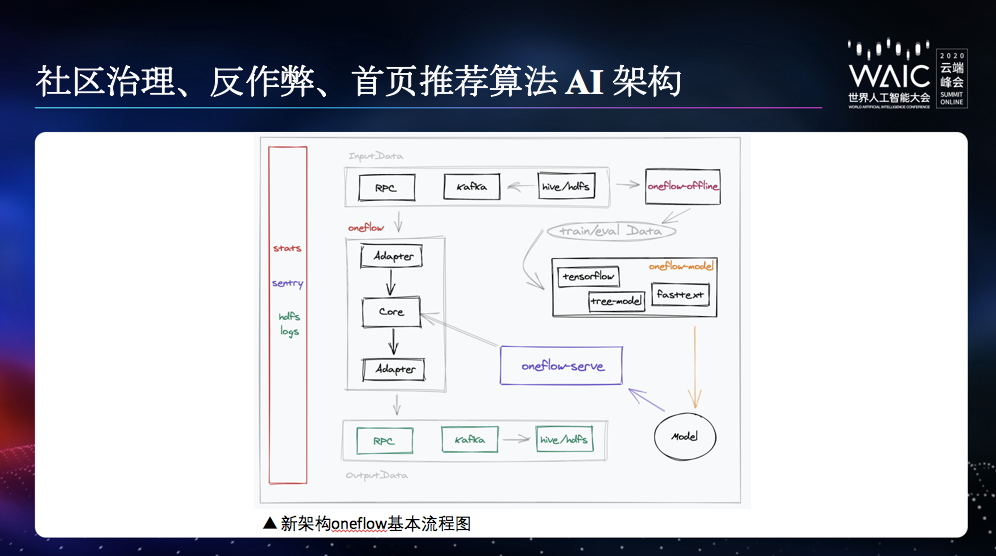

训练前部署难。算法工程师需投入大量精力进行运行环境的配置和资源调配,不便于工程师专注于模型优化和调参。
资源配置优化难。算法工程师难以判断机器学习任务的性能瓶颈在哪种资源上(如 CPU、GPU、内存等),不便于全局优化资源调配。
单机训练瓶颈。纵向扩展成本高、提升小。机器学习需要快速迭代试错,性能瓶颈制约了其最终产出的质量和速度。
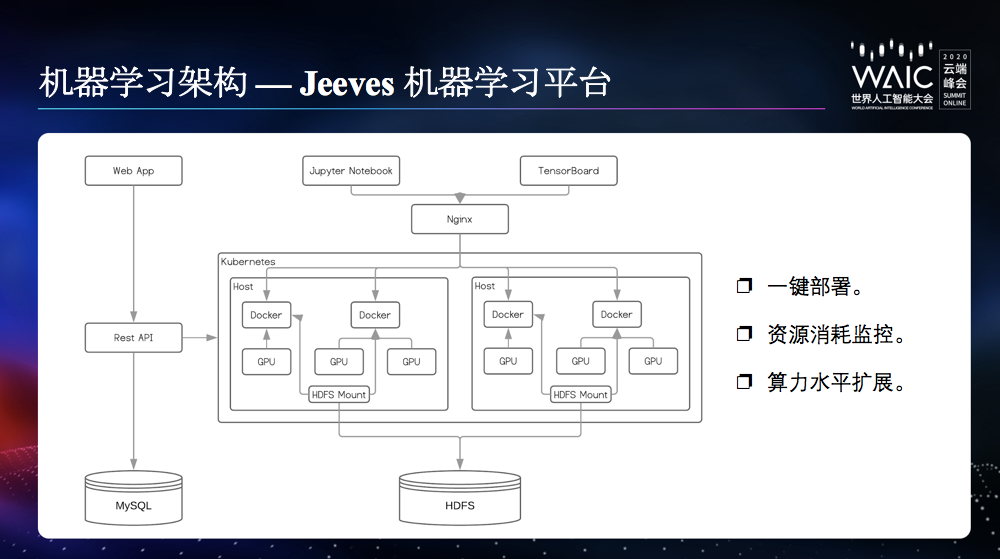
一键部署能力。算法工程师只需要申请资源、载入训练数据和代码,即可一键部署环境并开展工作。
资源消耗监控。监控资源在每个任务的消耗情况,便于识别瓶颈所在,针对性的进行性能优化和资源调配。
算力水平扩展。支持分布式机器学习,支持算力的快速扩展。