前沿 | 使用Transformer与无监督学习,OpenAI提出可迁移至多种NLP任务的通用模型
选自OpenAI
机器之心编译
参与:刘晓坤、思源
OpenAI 最近通过一个与任务无关的可扩展系统在一系列语言任务中获得了当前最优的性能,目前他们已经发布了该系统。OpenAI 表示他们的方法主要结合了两个已存的研究,即 Transformer 和无监督预训练。实验结果提供了非常令人信服的证据,其表明联合监督学习方法和无监督预训练能够得到非常好的性能。这其实是很多研究者过去探索过的领域,OpenAI 也希望他们这次的实验结果能激发更加深入的研究,并在更大和更多的数据集上测试联合监督学习与无监督预训练的性能。
OpenAI 的系统分为两阶段,首先研究者以无监督的方式在大型数据集上训练一个 Transformer,即使用语言建模作为训练信号,然后研究者在小得多的有监督数据集上精调模型以解决具体任务。研究者开发的这种方式借鉴了他们关于 Sentiment Neuron(https://blog.openai.com/unsupervised-sentiment-neuron/)方面的研究成果,他们发现无监督学习技术在足够多的数据集上训练能产生令人惊讶的可区分特征。因此研究者希望更进一步探索这一概念:我们能开发一个在大量数据进行无监督学习,并精调后就能在很多不同任务上实现很好性能的模型吗?研究结果表明这种方法可能有非常好的性能,相同的核心模型可以针对不同的任务进行少量适应和精调就能实现非常不错的性能。
这一项研究任务建立在《Semi-supervised Sequence Learning》论文中所提出的方法,该方法展示了如何通过无监督预训练的 LSTM 与有监督的精调提升文本分类性能。这一项研究还扩展了论文《Universal Language Model Fine-tuning for Text Classification》所提出的 ULMFiT 方法,它展示了单个与数据集无关的 LSTM 语言模型如何进行精调以在各种文本分类数据集上获得当前最优的性能。OpenAI 的研究工作展示了如何使用基于 Transformer 的模型,并在精调后能适应于除文本分类外其它更多的任务,例如常识推理、语义相似性和阅读理解。该方法与 ELMo 相似但更加通用,ELMo 同样也结合了预训练,但使用为任务定制的架构以在各种任务中取得当前顶尖的性能。
OpenAI 只需要很少的调整就能实现最后的结果。所有数据集都使用单一的前向语言模型,且不使用任何集成方法,超参配置也与大多数研究成果相同。
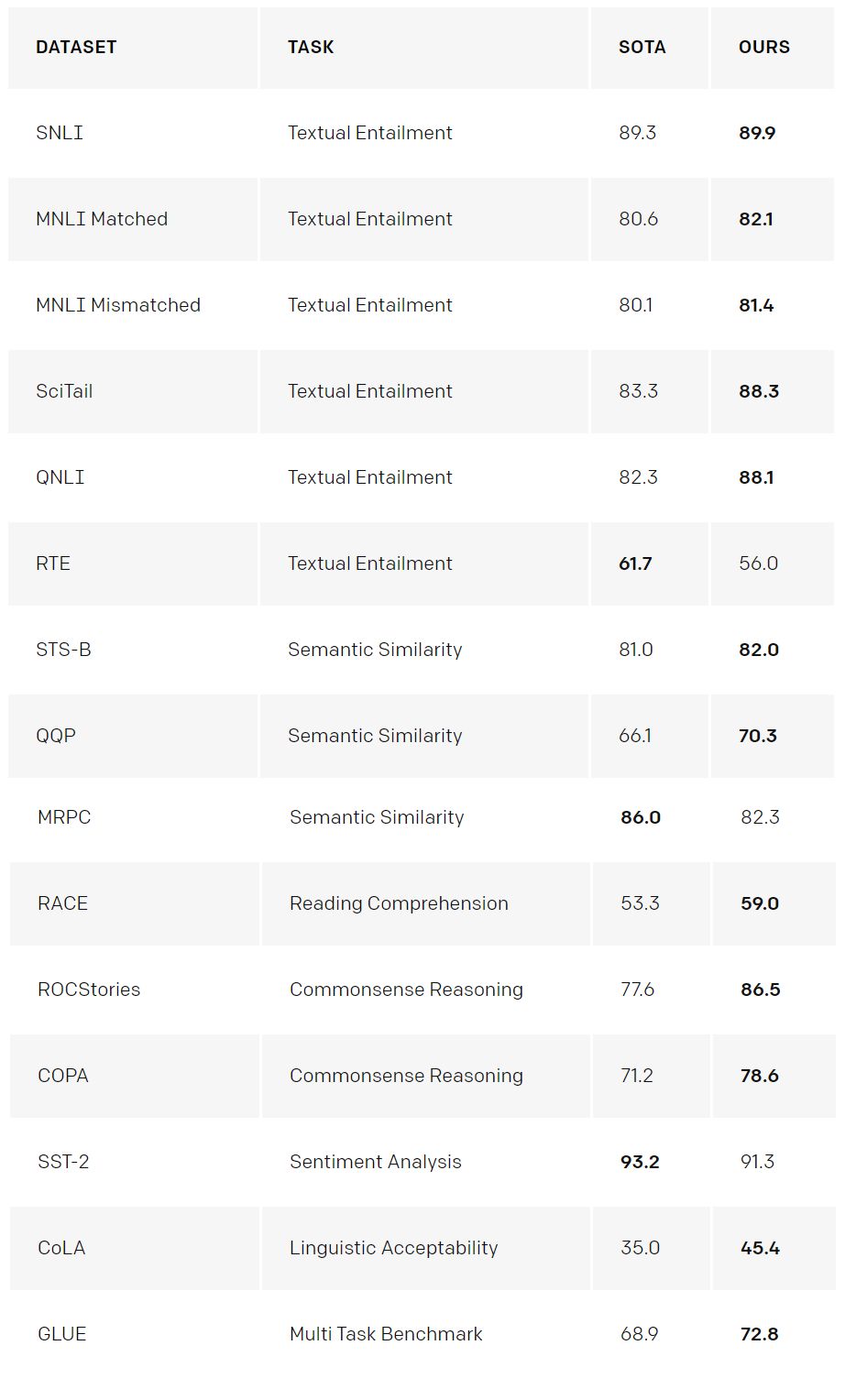
OpenAI 特别兴奋这一方法在三个数据集上得到的性能,即 COPA、RACE 和 ROCStories,它们都是旨在为常识推理和阅读理解设计的测试集。OpenAI 的模型在这些数据集上都获得了新的最佳性能,且有较大的提升。这些数据集通常被认为需要多句子推理和显著的世界知识来帮助解决问题,这表明研究者的模型通过无监督学习主要提升了这些技能。这同样表明我们可以通过无监督学习技术开发复杂的语言理解能力。
为什么使用无监督学习?
监督学习是近期大部分机器学习成功方法的关键,但是,它需要大型、经过仔细清洗的数据集才能表现良好,这需要很高的成本。无监督学习因其解决这些缺陷的潜力而具备极大吸引力。由于无监督学习解决了人工标注数据的瓶颈,它在计算能力不断增强、可获取原始数据增多的当前趋势下,仍然能够实现很好的扩展。无监督学习是非常活跃的研究领域,但是它在实际应用中仍然受到限制。
近期出现了利用无监督学习方法通过大量无标注数据来增强系统的热潮;使用无监督技术训练的词表征可以使用包含 TB 级信息的大型数据集,而且无监督方法与监督学习技术相结合能够在大量 NLP 任务上提高性能。直到最近,这些用于 NLP 任务的无监督技术(如 GLoVe 和 word2vec)使用简单的模型(词向量)和训练过的信号(局部词共现)。Skip-Thought 向量是对复杂方法才能实现的改进的较早呈现。但是现在新技术用于进一步提升性能,包括预训练句子表征模型、语境化词向量(ELMo 和 CoVE)的使用,以及使用自定义架构来结合无监督预训练和监督式精调的方法,比如本文中 OpenAI 的方法。
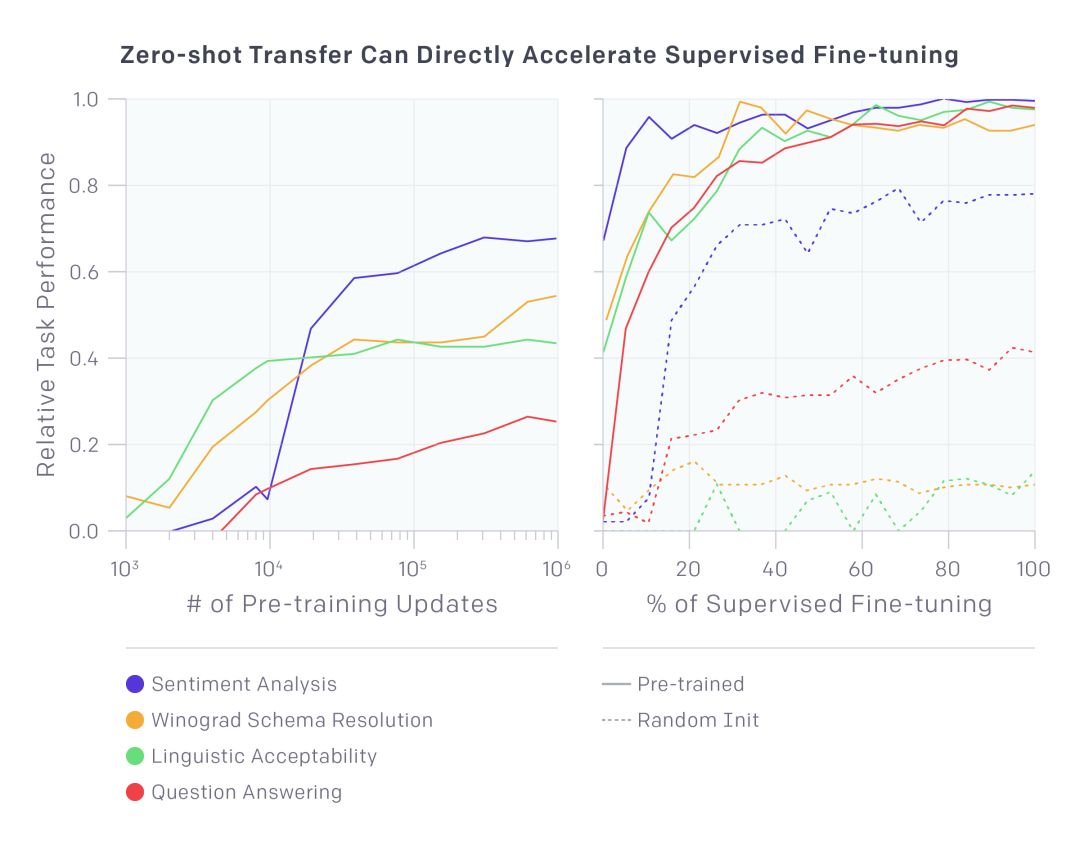
在大型文本语料库上对模型进行预训练可以极大地改善其在较难的自然语言处理任务(如 Winograd Schema Resolution)上的性能。
OpenAI 还注意到他们能够使用底层语言模型开始执行任务,无需训练。例如,在选择正确答案等任务中的性能随着底层语言模型的改进而得到改善。尽管这些方法的绝对性能与当前最优的监督方法相比仍然较低(在问答任务中,非监督方法的性能仍然不如简单的滑动窗口监督式基线模型),但是这些方法在大量任务上具备鲁棒性,这令人鼓舞。不包含任何任务和世界相关信息的随机初始化网络,其性能不比使用这些启发式方法的随机初始化网络好。这为生成性预训练为什么能够提高下游任务上的性能提供了一些洞见。
OpenAI 还使用模型中的现有语言功能来执行情感分析。研究人员使用了 Stanford Sentiment Treebank 数据集,该数据集包含积极和消极的电影评论句子,研究人员可以使用语言模型通过在一个评论句子后输入单词「very」,并查看该模型预测该单词是「积极」或「消极」的概率,来猜测这条评论是积极还是消极的。这种方法无需将模型针对特定任务进行调整,它与经典基线模型的性能持平——大约 80% 的准确率。
该研究也是对 Transformer 架构的鲁棒性和实用性的验证,表明无需针对特定任务进行复杂的定制化或调参,也可以在大量任务上达到当前最优的结果。
缺点
该项目也有几个突出的问题值得注意:
计算需求:很多之前的解决 NLP 任务的方法可以在单块 GPU 上从零开始训练相对较小的模型。OpenAI 的方法在预训练步骤中需要很高的成本——在 8 块 GPU 上训练 1 个月。幸运的是,这仅需要做一次,OpenAI 会发布他们的模型,从而其他人可以避免这一步。它也是一个很大的模型(相比于之前的工作),因而需要更多的计算和内存。OpenAI 使用了一个 37 层(12 个模块)的 Tranformer 架构,并且在达到 512 个 token 的序列上训练。多数实验都是在 4 和 8 块 GPU 的系统上构建的。该模型确实能很快速地精调到新的任务上,这缓解了额外的资源需求。
通过文本学习而导致的对世界理解的局限和偏差:在互联网上可用的书籍和文本并没有囊括关于世界的完整甚至是准确的信息。近期的研究表明特定类型的信息很难仅通过文本学习到,其它研究表明模型会从数据分布中学习和利用偏差。
泛化能力仍然很脆弱:虽然 OpenAI 的方法在多种任务中提高了性能,目前的深度学习 NLP 模型仍然展现出令人吃惊的和反直觉的行为,特别是当在系统化、对抗性或超出数据分布的方式进行评估的时候。OpenAI 的方法相比于之前的纯神经网络的方法在文本蕴涵任务上展示了提升的词法鲁棒性。在 Glockner 等人的论文《Breaking NLI Systems with Sentences that Require Simple Lexical Inferences》引入的数据集中,他们的模型达到了 83.75% 的准确率,和 KIM(Knowledge-based Inference Model,来自《NATURAL LANGUAGE INFERENCE WITH EXTERNAL KNOWLEDGE》)的性能相近(通过 WordNet 整合了外部知识)。
未来方向
扩展该方法:研究者观察到语言模型性能的提高和下游任务的提高有很大关联。他们目前使用的是商用 GPU(单个 8GPU 机器)以及仅包含数千本书籍的训练数据集(约 5GB 的文本)。这意味着如果使用验证效果好的方法以及更多的计算资源和数据,该模型还有很大的提升空间。
改善精调过程:研究者的方法目前还很简单。有可能使用更复杂的适应和迁移技术例如在 ULMFiT 中所探索的方法,可以让该模型获得显著的提升。
更好地理解生成式预训练的有效性:虽然本文中片面地讨论了一些思想,更多的目标指向的实验和研究将帮助分辨不同的解释。例如,实验中观察到的性能增益有多少是由于处理更广泛上下文的能力的提高,有多少是由于世界知识的提高。
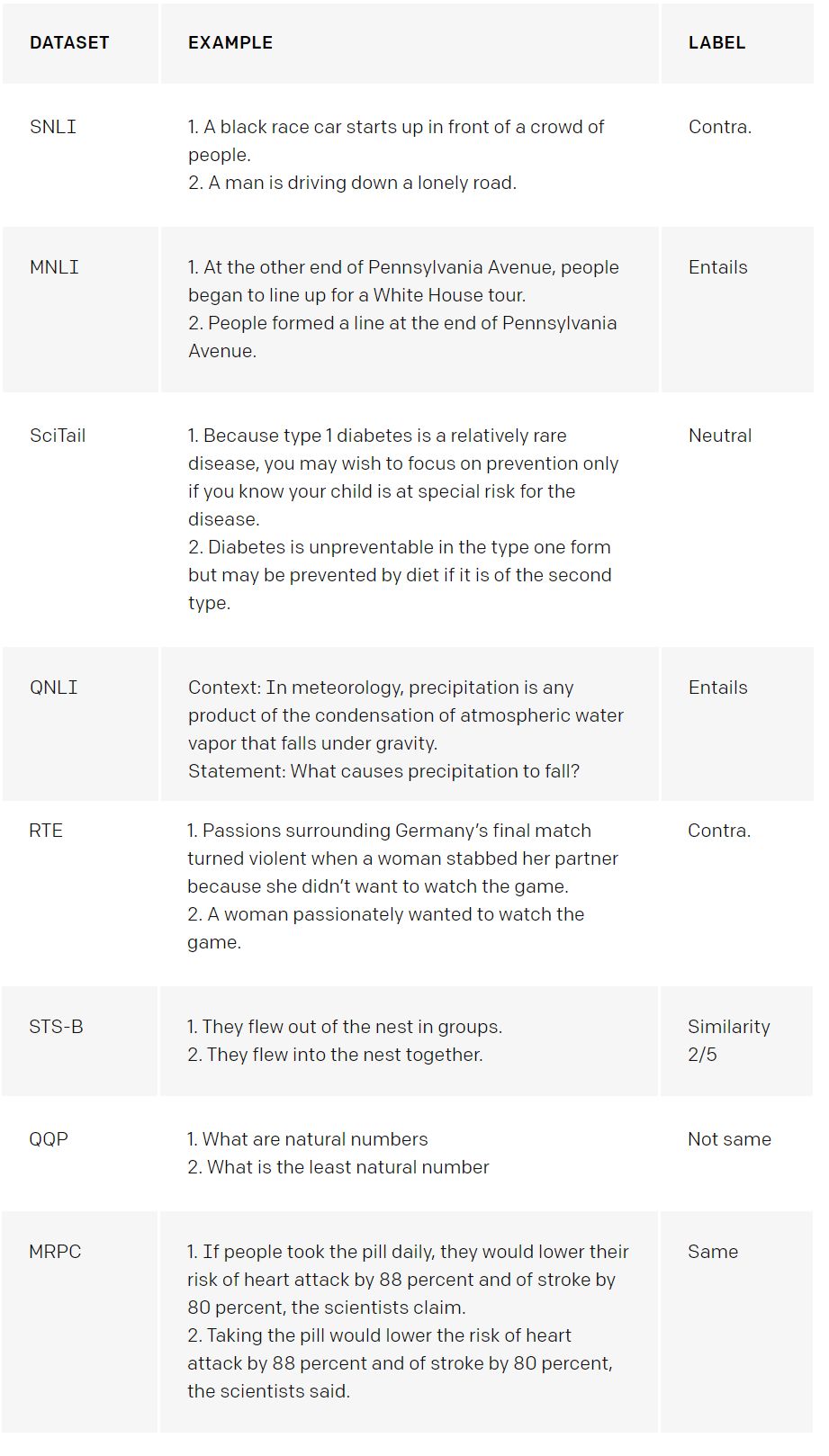
附录:数据集示例
论文:Improving Language Understanding by Generative Pre-Training

论文地址:https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
项目地址:https://github.com/openai/finetune-transformer-lm
摘要:自然语言理解包括很广泛的任务类型,例如文本蕴涵、问答、语义相似性评估以及文本分类。虽然存在大量的未标记文本语料库,但是为学习这些特定任务而标注的数据是较匮乏的,从而令有区别地训练表现足够好的模型变得很有挑战性。我们在本研究中表明通过在多个未标记文本语料库上对语言模型进行生成式预训练,然后有区别地对每个特定任务进行精调,可以在这些任务上取得很大的增益。相比于之前的方法,我们在精调以获得有效迁移的过程中利用了任务相关的输入转换,同时仅需要对模型架构做极小的改变。结果表明我们的方法在自然语言理解的很广泛的基准上具备有效性。我们不基于任务的模型超越了那些为每个任务特别设计架构而分别进行训练的模型,在研究的 12 项任务的 9 项中显著提高了当前最佳结果。例如,我们在常识推理(Stories Cloze Test)、问答(RACE)、文本蕴涵(MultiNLI)中分别达到了 8.9%、5.7%、1.5% 的绝对提高。

原文链接:https://blog.openai.com/language-unsupervised/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




