「深度理解强化学习」课程更新,完善资料免费学习新课!

AI 研习社「深度理解强化学习」课程更新啦~

强化学习是一种重要的机器学习类型,我们训练的智能体通过执行操作和查看结果来了解如何在环境中执行操作。最广为人知的强化学习例子就是Alphago。2016年Alphago战胜围棋世界冠军李世石,震撼全人类,AI学术界和工业界也积极投入到强化学习的研究和探索中。
本期更新的内容为第三课「RL 环境介绍与搭建」。在本期课程中,授课讲师将会一步步教你如何搭建 Python 环境、强化学习环境和深度学习环境,帮助初学者上手强化学习。
现在 AI 研习社的用户可通过完善个人资料获取解锁卡,免费解锁观看本系列课程最新课时,具体操作如下:
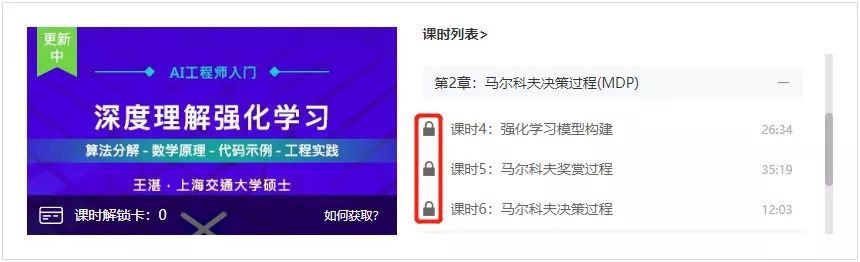
在解锁方式页面,点击「去完善」按钮,跳转至个人资料页。
将个人资料填写至完善度 100%,然后点击提交按钮,即可获得解锁卡一张。

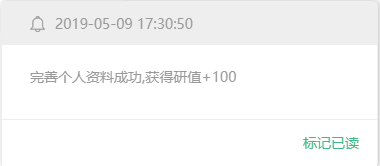


彩 蛋
完善个人资料后会立即获得 100 研值,您可以跳转至研习社福利市集兑换价值 100 元的课程优惠券。
扫描下方优惠券进行兑换:
https://ai.yanxishe.com/page/vouchersDetail/5cc50cf1e5794

完善个人资料会生成你的社区专有名片,有助于你结识更多社区内相同技术方向、研究兴趣的朋友。
后续 AI 研习社将会上线更多有趣有料的社交功能,帮助用户构建行业人脉。


王湛,上海交通大学硕士,研究方向为强化学习、计算机视觉等方向,在ACM MM Asia等国际会议上发表过相关论文。并对强化学习与计算机视觉的结合有很深的理解。
第一课 简介
1.1 强化学习初步介绍
1.2 强化学习基本要素和概念
1.3 课程要求
第二课 马尔科夫决策过程(MDP)
2.1 强化学习模型构建
2.2 马尔科夫奖赏过程
2.3 马尔科夫决策过程
第三课 RL环境介绍与搭建
3.1 Python环境
3.2 强化学习环境
3.3 深度学习环境搭建
第四课 强化学习解法1
4.1 动态规划(DP)-值函数
4.2 动态规划(DP)-动作值函数
4.3 动态规划(DP)-总结
第五课 强化学习解法2
5.1 蒙特卡洛学习(Monte-Carlo Prediction)
5.2 蒙特卡洛学习(Monte-Carlo Control)
5.3 蒙特卡洛学习(Coding exercise)
第六课 强化学习解法3
6.1 时序差分学习(Temporal-Difference Learning)
6.2 Sarsa算法
6.3 总结
第七课 强化学习解法4
7.1 时序差分学习之(Q-learning)
7.2 Q-learning(Coding exercise)
7.3 总结
第八课 深度Q网络
8.1 值函数的近似
8.2 Deep Q network
8.3 Coding exercise
第九课 策略梯度(Policy Gradient)
9.1 策略梯度思想
9.2 Reinforce算法
9.3 Coding exercise
第十课 Actor Critic
10.1 Actor Critic介绍
10.2 Deep Deterministic Policy Gradient (DDPG)
10.3 Asynchronous Advantage Actor-Critic (A3C)
10.4 RL新型算法的自我学习与提升
扫码加入强化学习课程群,和老师交流学习问题






